Boosting Unsupervised Semantic Segmentation with Principal Mask Proposals

0
🤷
Sign in to get full access
Overview
- This paper focuses on the task of unsupervised semantic segmentation, which aims to automatically partition images into semantically meaningful regions without any manual annotations.
- The researchers build upon recent advances in self-supervised representation learning and explore how to leverage these large pre-trained models for the downstream task of unsupervised segmentation.
- The authors present PriMaPs - Principal Mask Proposals, a method that decomposes images into semantically meaningful masks based on their feature representation.
- PriMaPs-EM, a stochastic expectation-maximization algorithm, is then used to fit class prototypes to the PriMaPs, enabling unsupervised semantic segmentation.
- The proposed approach achieves competitive results across various pre-trained backbone models and datasets, and can also be applied orthogonally to current state-of-the-art unsupervised semantic segmentation pipelines.
Plain English Explanation
The paper addresses the challenge of unsupervised semantic segmentation, which is the task of automatically dividing images into meaningful regions without any prior labeling or human guidance. Building on recent breakthroughs in self-supervised representation learning, the researchers explore how to leverage these powerful pre-trained models to tackle the problem of unsupervised segmentation.
The key idea is to first decompose the images into semantically meaningful masks, which the authors call Principal Mask Proposals (PriMaPs). This is done by analyzing the feature representations of the images. The researchers then use a statistical algorithm called PriMaPs-EM to group these masks into distinct classes, effectively segmenting the images in an unsupervised manner.
Importantly, this approach works well across different pre-trained models, such as DINO and DINOv2, as well as various datasets, including Cityscapes, COCO-Stuff, and Potsdam-3. Moreover, the researchers show that their method can be combined with other state-of-the-art unsupervised segmentation techniques to further improve the results.
Technical Explanation
The key innovation of this work is the PriMaPs - Principal Mask Proposals approach, which decomposes images into semantically meaningful masks based on their feature representation. This is achieved by leveraging the rich feature hierarchies learned by large self-supervised pre-trained models, such as DINO and DINOv2.
The researchers then use a stochastic expectation-maximization algorithm, called PriMaPs-EM, to fit class prototypes to the PriMaPs. This allows them to realize unsupervised semantic segmentation without any form of manual annotation.
The experiments demonstrate that PriMaPs-EM achieves competitive results across various pre-trained backbone models and datasets, including Cityscapes, COCO-Stuff, and Potsdam-3. Importantly, the authors also show that their method can be applied orthogonally to current state-of-the-art unsupervised semantic segmentation pipelines, further boosting the performance.
Critical Analysis
One of the key strengths of the proposed approach is its conceptual simplicity and flexibility. By leveraging the powerful feature representations learned by self-supervised pre-trained models, the researchers are able to achieve strong unsupervised segmentation performance without relying on complex architectures or extensive task-specific training.
However, the paper does not provide a detailed analysis of the limitations or failure cases of the PriMaPs-EM algorithm. It would be valuable to understand the types of images or scenarios where the method struggles, as well as potential avenues for further improving its robustness and generalization.
Additionally, the paper does not explore the interpretability or explainability of the learned segmentation masks. Understanding how the PriMaPs correspond to meaningful semantic regions in the images could provide valuable insights and make the method more accessible to domain experts.
Conclusion
This paper presents a novel approach to unsupervised semantic segmentation, leveraging the power of self-supervised representation learning to decompose images into semantically meaningful masks. The proposed PriMaPs - Principal Mask Proposals and PriMaPs-EM algorithm demonstrate strong performance across various pre-trained models and datasets, without the need for manual annotation.
The conceptual simplicity and flexibility of the method suggest that it could be a valuable tool for a wide range of applications, from automated image understanding to medical image analysis. As the field of self-supervised learning continues to advance, techniques like those presented in this paper will likely play an increasingly important role in unlocking the full potential of unsupervised visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Boosting Unsupervised Semantic Segmentation with Principal Mask Proposals
Oliver Hahn, Nikita Araslanov, Simone Schaub-Meyer, Stefan Roth
Unsupervised semantic segmentation aims to automatically partition images into semantically meaningful regions by identifying global categories within an image corpus without any form of annotation. Building upon recent advances in self-supervised representation learning, we focus on how to leverage these large pre-trained models for the downstream task of unsupervised segmentation. We present PriMaPs - Principal Mask Proposals - decomposing images into semantically meaningful masks based on their feature representation. This allows us to realize unsupervised semantic segmentation by fitting class prototypes to PriMaPs with a stochastic expectation-maximization algorithm, PriMaPs-EM. Despite its conceptual simplicity, PriMaPs-EM leads to competitive results across various pre-trained backbone models, including DINO and DINOv2, and across datasets, such as Cityscapes, COCO-Stuff, and Potsdam-3. Importantly, PriMaPs-EM is able to boost results when applied orthogonally to current state-of-the-art unsupervised semantic segmentation pipelines.
Read more4/26/2024
🤷
0
ProMerge: Prompt and Merge for Unsupervised Instance Segmentation
Dylan Li, Gyungin Shin
Unsupervised instance segmentation aims to segment distinct object instances in an image without relying on human-labeled data. This field has recently seen significant advancements, partly due to the strong local correspondences afforded by rich visual feature representations from self-supervised models (e.g., DINO). Recent state-of-the-art approaches use self-supervised features to represent images as graphs and solve a generalized eigenvalue system (i.e., normalized-cut) to generate foreground masks. While effective, this strategy is limited by its attendant computational demands, leading to slow inference speeds. In this paper, we propose Prompt and Merge (ProMerge), which leverages self-supervised visual features to obtain initial groupings of patches and applies a strategic merging to these segments, aided by a sophisticated background-based mask pruning technique. ProMerge not only yields competitive results but also offers a significant reduction in inference time compared to state-of-the-art normalized-cut-based approaches. Furthermore, when training an object detector using our mask predictions as pseudo-labels, the resulting detector surpasses the current leading unsupervised model on various challenging instance segmentation benchmarks.
Read more9/30/2024
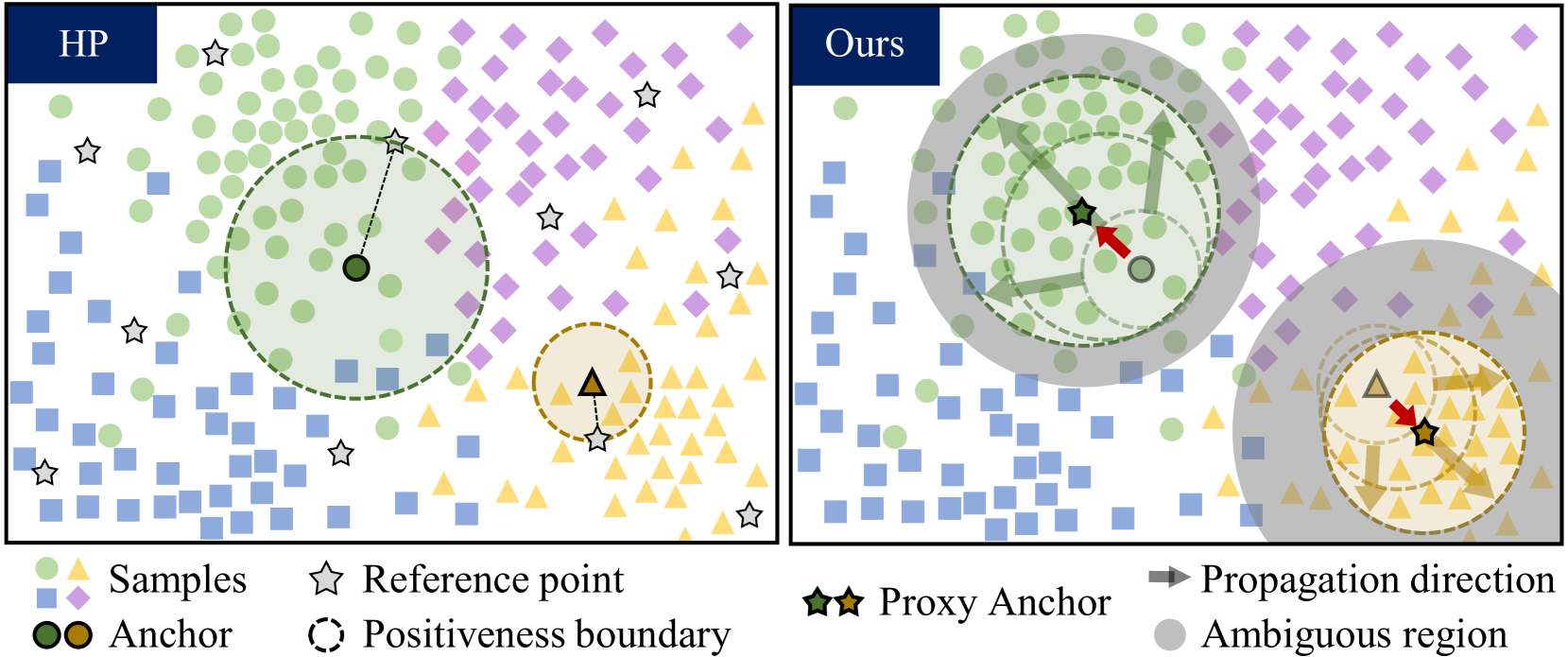
0
Progressive Proxy Anchor Propagation for Unsupervised Semantic Segmentation
Hyun Seok Seong, WonJun Moon, SuBeen Lee, Jae-Pil Heo
The labor-intensive labeling for semantic segmentation has spurred the emergence of Unsupervised Semantic Segmentation. Recent studies utilize patch-wise contrastive learning based on features from image-level self-supervised pretrained models. However, relying solely on similarity-based supervision from image-level pretrained models often leads to unreliable guidance due to insufficient patch-level semantic representations. To address this, we propose a Progressive Proxy Anchor Propagation (PPAP) strategy. This method gradually identifies more trustworthy positives for each anchor by relocating its proxy to regions densely populated with semantically similar samples. Specifically, we initially establish a tight boundary to gather a few reliable positive samples around each anchor. Then, considering the distribution of positive samples, we relocate the proxy anchor towards areas with a higher concentration of positives and adjust the positiveness boundary based on the propagation degree of the proxy anchor. Moreover, to account for ambiguous regions where positive and negative samples may coexist near the positiveness boundary, we introduce an instance-wise ambiguous zone. Samples within these zones are excluded from the negative set, further enhancing the reliability of the negative set. Our state-of-the-art performances on various datasets validate the effectiveness of the proposed method for Unsupervised Semantic Segmentation.
Read more7/18/2024

0
Segment Anything without Supervision
XuDong Wang, Jingfeng Yang, Trevor Darrell
The Segmentation Anything Model (SAM) requires labor-intensive data labeling. We present Unsupervised SAM (UnSAM) for promptable and automatic whole-image segmentation that does not require human annotations. UnSAM utilizes a divide-and-conquer strategy to discover the hierarchical structure of visual scenes. We first leverage top-down clustering methods to partition an unlabeled image into instance/semantic level segments. For all pixels within a segment, a bottom-up clustering method is employed to iteratively merge them into larger groups, thereby forming a hierarchical structure. These unsupervised multi-granular masks are then utilized to supervise model training. Evaluated across seven popular datasets, UnSAM achieves competitive results with the supervised counterpart SAM, and surpasses the previous state-of-the-art in unsupervised segmentation by 11% in terms of AR. Moreover, we show that supervised SAM can also benefit from our self-supervised labels. By integrating our unsupervised pseudo masks into SA-1B's ground-truth masks and training UnSAM with only 1% of SA-1B, a lightly semi-supervised UnSAM can often segment entities overlooked by supervised SAM, exceeding SAM's AR by over 6.7% and AP by 3.9% on SA-1B.
Read more7/1/2024