Boosting X-formers with Structured Matrix for Long Sequence Time Series Forecasting

0
🤷
Sign in to get full access
Overview
- Transformer-based models have become popular for long sequence time series forecasting (LSTF) tasks due to their high forecasting accuracy.
- The self-attention mechanism, a key component of these models, poses efficiency challenges during training and inference due to its quadratic time complexity.
- The paper proposes a novel architectural design called the Surrogate Attention Framework to improve the efficiency of Transformer-based LSTF models without sacrificing accuracy.
Plain English Explanation
Transformer-based models have shown great success in forecasting long-term time series data. These models use a technique called self-attention, which helps them understand the relationships between different parts of the input data. However, self-attention can be computationally intensive, making training and using these models slow and resource-intensive.
The researchers in this paper have developed a new way to make Transformer-based models more efficient, without losing their forecasting accuracy. They call their approach the Surrogate Attention Framework. The key idea is to replace the self-attention mechanism with a more efficient "surrogate" version that achieves similar performance. This allows the models to run faster and use less computational resources, while still maintaining their impressive forecasting capabilities.
The paper demonstrates the effectiveness of this approach by testing it on a variety of time series forecasting tasks, showing an average performance improvement of 9.45% and a significant 46% reduction in model size.
Technical Explanation
The paper proposes a novel architectural design called the Surrogate Attention Framework to improve the efficiency of Transformer-based models for long sequence time series forecasting (LSTF) tasks. The framework incorporates two key components: Surrogate Attention Blocks and Surrogate FFN Blocks, which are used to replace the self-attention mechanism and the feedforward network (FFN) layers, respectively.
The researchers establish the equivalence of the Surrogate Attention Block to the self-attention mechanism in terms of both expressiveness and trainability. This means the surrogate version can achieve similar performance to the original self-attention, but with significantly improved computational efficiency.
Through extensive experiments on nine Transformer-based models across five time series tasks, the authors observe an average performance improvement of 9.45% while achieving a significant reduction in model size by 46%. This demonstrates the effectiveness of the Surrogate Attention Framework in boosting the efficiency of Transformer-based LSTF models without sacrificing accuracy.
Critical Analysis
The paper provides a thorough and rigorous evaluation of the Surrogate Attention Framework, testing it across a diverse set of Transformer-based models and time series forecasting tasks. The researchers have done a commendable job in establishing the theoretical equivalence between the Surrogate Attention Block and the original self-attention mechanism, which lends credibility to their approach.
However, the paper does not address the potential limitations or caveats of their framework. For example, it would be helpful to understand how the Surrogate Attention Framework performs in more complex, real-world time series forecasting scenarios, or whether there are any specific types of time series data or tasks where the framework may not be as effective.
Additionally, the paper could have delved deeper into the underlying reasons for the significant reduction in model size reported. It would be interesting to understand the specific aspects of the framework that contribute to this size reduction and how it might impact the practical deployment of these models in resource-constrained environments.
Overall, the Surrogate Attention Framework is a promising approach to improving the efficiency of Transformer-based LSTF models, and the paper's findings suggest that it is a meaningful contribution to the field. Further research and exploration of the framework's limitations and potential applications would be valuable.
Conclusion
The paper introduces a novel Surrogate Attention Framework to enhance the efficiency of Transformer-based models for long sequence time series forecasting tasks. By replacing the computationally expensive self-attention mechanism with a more efficient surrogate version, the framework is able to achieve significant improvements in model performance and size reduction without sacrificing forecasting accuracy.
The thorough evaluation and theoretical analysis presented in the paper demonstrate the effectiveness of this approach, which could have important implications for the practical deployment of Transformer-based models in real-world applications where computational resources and deployment latency are key considerations. As the field of time series forecasting continues to evolve, the Surrogate Attention Framework offers a promising direction for developing more efficient and high-performing models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Boosting X-formers with Structured Matrix for Long Sequence Time Series Forecasting
Zhicheng Zhang, Yong Wang, Shaoqi Tan, Bowei Xia, Yujie Luo
Transformer-based models for long sequence time series forecasting (LSTF) problems have gained significant attention due to their exceptional forecasting precision. As the cornerstone of these models, the self-attention mechanism poses a challenge to efficient training and inference due to its quadratic time complexity. In this article, we propose a novel architectural design for Transformer-based models in LSTF, leveraging a substitution framework that incorporates Surrogate Attention Blocks and Surrogate FFN Blocks. The framework aims to boost any well-designed model's efficiency without sacrificing its accuracy. We further establish the equivalence of the Surrogate Attention Block to the self-attention mechanism in terms of both expressiveness and trainability. Through extensive experiments encompassing nine Transformer-based models across five time series tasks, we observe an average performance improvement of 9.45% while achieving a significant reduction in model size by 46%
Read more5/24/2024
⛏️
628
xLSTMTime : Long-term Time Series Forecasting With xLSTM
Musleh Alharthi, Ausif Mahmood
In recent years, transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), demonstrating significant advancements despite facing challenges such as high computational demands, difficulty in capturing temporal dynamics, and managing long-term dependencies. The emergence of LTSF-Linear, with its straightforward linear architecture, has notably outperformed transformer-based counterparts, prompting a reevaluation of the transformer's utility in time series forecasting. In response, this paper presents an adaptation of a recent architecture termed extended LSTM (xLSTM) for LTSF. xLSTM incorporates exponential gating and a revised memory structure with higher capacity that has good potential for LTSF. Our adopted architecture for LTSF termed as xLSTMTime surpasses current approaches. We compare xLSTMTime's performance against various state-of-the-art models across multiple real-world da-tasets, demonstrating superior forecasting capabilities. Our findings suggest that refined recurrent architectures can offer competitive alternatives to transformer-based models in LTSF tasks, po-tentially redefining the landscape of time series forecasting.
Read more8/13/2024
0
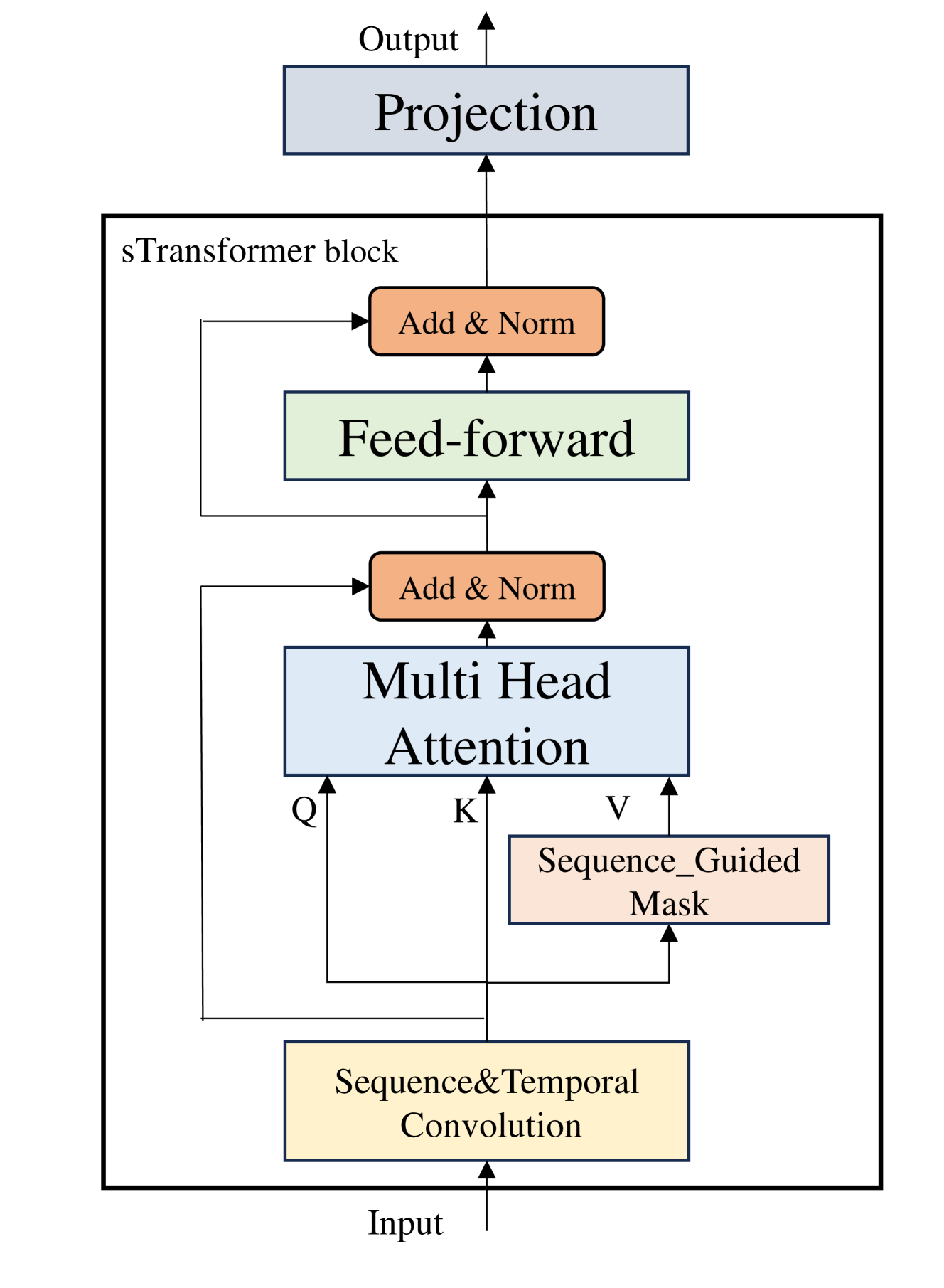
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Jiaheng Yin, Zhengxin Shi, Jianshen Zhang, Xiaomin Lin, Yulin Huang, Yongzhi Qi, Wei Qi
In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Read more8/20/2024

0
Are Self-Attentions Effective for Time Series Forecasting?
Dongbin Kim, Jinseong Park, Jaewook Lee, Hoki Kim
Time series forecasting is crucial for applications across multiple domains and various scenarios. Although Transformer models have dramatically shifted the landscape of forecasting, their effectiveness remains debated. Recent findings have indicated that simpler linear models might outperform complex Transformer-based approaches, highlighting the potential for more streamlined architectures. In this paper, we shift focus from the overall architecture of the Transformer to the effectiveness of self-attentions for time series forecasting. To this end, we introduce a new architecture, Cross-Attention-only Time Series transformer (CATS), that rethinks the traditional Transformer framework by eliminating self-attention and leveraging cross-attention mechanisms instead. By establishing future horizon-dependent parameters as queries and enhanced parameter sharing, our model not only improves long-term forecasting accuracy but also reduces the number of parameters and memory usage. Extensive experiment across various datasets demonstrates that our model achieves superior performance with the lowest mean squared error and uses fewer parameters compared to existing models.
Read more5/28/2024