Automating the Diagnosis of Human Vision Disorders by Cross-modal 3D Generation

0

Sign in to get full access
Overview
- This paper explores a novel approach to automating the diagnosis of human vision disorders using cross-modal 3D generation.
- The researchers developed a deep learning model that can generate 3D representations of the eye and visual system from 2D medical images, allowing for more accurate and efficient diagnosis of vision disorders.
- The model was trained on a large dataset of 2D eye scans and 3D anatomical models, enabling it to learn the complex relationships between visual structures and disease characteristics.
Plain English Explanation
The researchers have created an artificial intelligence (AI) system that can help doctors diagnose vision problems more easily. The system works by taking 2D medical images of a person's eyes, like the ones doctors use to examine patients, and generating 3D models of the eye and visual system. These 3D models allow doctors to see the structure of the eye in much more detail, which can help them identify signs of vision disorders that might be hard to spot in the 2D images alone.
The key innovation is that the AI model has been trained on a large dataset of 2D eye scans and 3D anatomical models of the eye. By learning the connections between the 2D images and the 3D structures, the model can then take a new 2D scan and accurately generate a corresponding 3D model. This allows doctors to get a more complete picture of the patient's visual system, which can lead to faster and more accurate diagnoses of conditions like [link to https://aimodels.fyi/papers/arxiv/reconstructing-retinal-visual-images-from-3t-fmri]eye diseases[/link], [link to https://aimodels.fyi/papers/arxiv/animate-your-thoughts-decoupled-reconstruction-dynamic-natural]vision impairments[/link], and even [link to https://aimodels.fyi/papers/arxiv/dream-visual-decoding-from-reversing-human-visual]neurological disorders that affect vision[/link].
Technical Explanation
The researchers developed a cross-modal 3D generation model that can translate 2D medical images of the eye into 3D representations of the underlying anatomical structures. [link to https://aimodels.fyi/papers/arxiv/neuro-vision-to-language-enhancing-visual-reconstruction]The model was trained on a large dataset of paired 2D eye scans and 3D anatomical models[/link], allowing it to learn the complex mappings between the 2D visual inputs and the 3D structural features.
The model architecture consists of an encoder network that processes the 2D input image and a decoder network that generates the corresponding 3D output. The encoder uses convolutional layers to extract visual features from the 2D image, while the decoder employs a series of transposed convolutions to generate the 3D structure. The two networks are trained end-to-end using a combination of reconstruction and adversarial loss functions to ensure the generated 3D models accurately reflect the underlying anatomy.
The researchers evaluated the model's performance on a held-out test set of 2D-3D image pairs, demonstrating its ability to generate high-fidelity 3D reconstructions that closely matched the ground truth anatomical models. They also showed that the generated 3D representations could be used to improve the accuracy of vision disorder diagnosis compared to using the 2D images alone.
Critical Analysis
The researchers have presented a promising approach to automating the diagnosis of vision disorders using cross-modal 3D generation. However, there are some potential limitations and areas for further research:
-
The study was conducted on a relatively small dataset of 2D-3D image pairs, which may limit the model's generalization to a wider range of patient populations and disease types. [link to https://aimodels.fyi/papers/arxiv/fmri-exploration-visual-quality-assessment]Larger and more diverse datasets would be needed to fully assess the model's robustness and scalability.[/link]
-
The researchers did not provide detailed information on the specific vision disorders included in the dataset or the performance of the model on different types of conditions. Further research is needed to understand the model's capabilities and limitations in diagnosing different types of vision problems.
-
While the 3D reconstructions generated by the model were visually compelling, the researchers did not quantify the medical relevance or diagnostic utility of the 3D outputs. Additional validation studies involving clinicians and patient outcomes would be necessary to fully demonstrate the model's practical impact on vision disorder diagnosis.
-
The paper did not address potential ethical concerns, such as the need for careful deployment of such AI systems to avoid biases or errors that could lead to misdiagnosis and harm to patients. Rigorous testing and appropriate safeguards would be crucial before implementing this technology in clinical settings.
Conclusion
The paper presents a novel approach to automating the diagnosis of vision disorders using cross-modal 3D generation. By learning to translate 2D medical images into 3D representations of the eye and visual system, the researchers have developed a tool that could potentially enhance the accuracy and efficiency of vision disorder diagnosis. While further research is needed to fully assess the model's capabilities and limitations, this work represents an exciting step forward in the application of AI to healthcare challenges. If successfully deployed, such technologies could have a significant impact on improving visual health outcomes for patients around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automating the Diagnosis of Human Vision Disorders by Cross-modal 3D Generation
Yuankun Yang, Li Zhang, Ziyang Xie, Zhiyuan Yuan, Jianfeng Feng, Xiatian Zhu, Yu-Gang Jiang
Understanding the hidden mechanisms behind human's visual perception is a fundamental question in neuroscience. To that end, investigating into the neural responses of human mind activities, such as functional Magnetic Resonance Imaging (fMRI), has been a significant research vehicle. However, analyzing fMRI signals is challenging, costly, daunting, and demanding for professional training. Despite remarkable progress in fMRI analysis, existing approaches are limited to generating 2D images and far away from being biologically meaningful and practically useful. Under this insight, we propose to generate visually plausible and functionally more comprehensive 3D outputs decoded from brain signals, enabling more sophisticated modeling of fMRI data. Conceptually, we reformulate this task as a {em fMRI conditioned 3D object generation} problem. We design a novel 3D object representation learning method, Brain3D, that takes as input the fMRI data of a subject who was presented with a 2D image, and yields as output the corresponding 3D object images. The key capabilities of this model include tackling the noises with high-level semantic signals and a two-stage architecture design for progressive high-level information integration. Extensive experiments validate the superior capability of our model over previous state-of-the-art 3D object generation methods. Importantly, we show that our model captures the distinct functionalities of each region of human vision system as well as their intricate interplay relationships, aligning remarkably with the established discoveries in neuroscience. Further, preliminary evaluations indicate that Brain3D can successfully identify the disordered brain regions in simulated scenarios, such as V1, V2, V3, V4, and the medial temporal lobe (MTL) within the human visual system. Our data and code will be available at https://brain-3d.github.io/.
Read more8/29/2024

0
MinD-3D: Reconstruct High-quality 3D objects in Human Brain
Jianxiong Gao, Yuqian Fu, Yun Wang, Xuelin Qian, Jianfeng Feng, Yanwei Fu
In this paper, we introduce Recon3DMind, an innovative task aimed at reconstructing 3D visuals from Functional Magnetic Resonance Imaging (fMRI) signals, marking a significant advancement in the fields of cognitive neuroscience and computer vision. To support this pioneering task, we present the fMRI-Shape dataset, which includes data from 14 participants and features 360-degree videos of 3D objects to enable comprehensive fMRI signal capture across various settings, thereby laying a foundation for future research. Furthermore, we propose MinD-3D, a novel and effective three-stage framework specifically designed to decode the brain's 3D visual information from fMRI signals, demonstrating the feasibility of this challenging task. The framework begins by extracting and aggregating features from fMRI frames through a neuro-fusion encoder, subsequently employs a feature bridge diffusion model to generate visual features, and ultimately recovers the 3D object via a generative transformer decoder. We assess the performance of MinD-3D using a suite of semantic and structural metrics and analyze the correlation between the features extracted by our model and the visual regions of interest (ROIs) in fMRI signals. Our findings indicate that MinD-3D not only reconstructs 3D objects with high semantic relevance and spatial similarity but also significantly enhances our understanding of the human brain's capabilities in processing 3D visual information. Project page at: https://jianxgao.github.io/MinD-3D.
Read more7/19/2024

0
Reconstructing Retinal Visual Images from 3T fMRI Data Enhanced by Unsupervised Learning
Yujian Xiong, Wenhui Zhu, Zhong-Lin Lu, Yalin Wang
The reconstruction of human visual inputs from brain activity, particularly through functional Magnetic Resonance Imaging (fMRI), holds promising avenues for unraveling the mechanisms of the human visual system. Despite the significant strides made by deep learning methods in improving the quality and interpretability of visual reconstruction, there remains a substantial demand for high-quality, long-duration, subject-specific 7-Tesla fMRI experiments. The challenge arises in integrating diverse smaller 3-Tesla datasets or accommodating new subjects with brief and low-quality fMRI scans. In response to these constraints, we propose a novel framework that generates enhanced 3T fMRI data through an unsupervised Generative Adversarial Network (GAN), leveraging unpaired training across two distinct fMRI datasets in 7T and 3T, respectively. This approach aims to overcome the limitations of the scarcity of high-quality 7-Tesla data and the challenges associated with brief and low-quality scans in 3-Tesla experiments. In this paper, we demonstrate the reconstruction capabilities of the enhanced 3T fMRI data, highlighting its proficiency in generating superior input visual images compared to data-intensive methods trained and tested on a single subject.
Read more4/9/2024
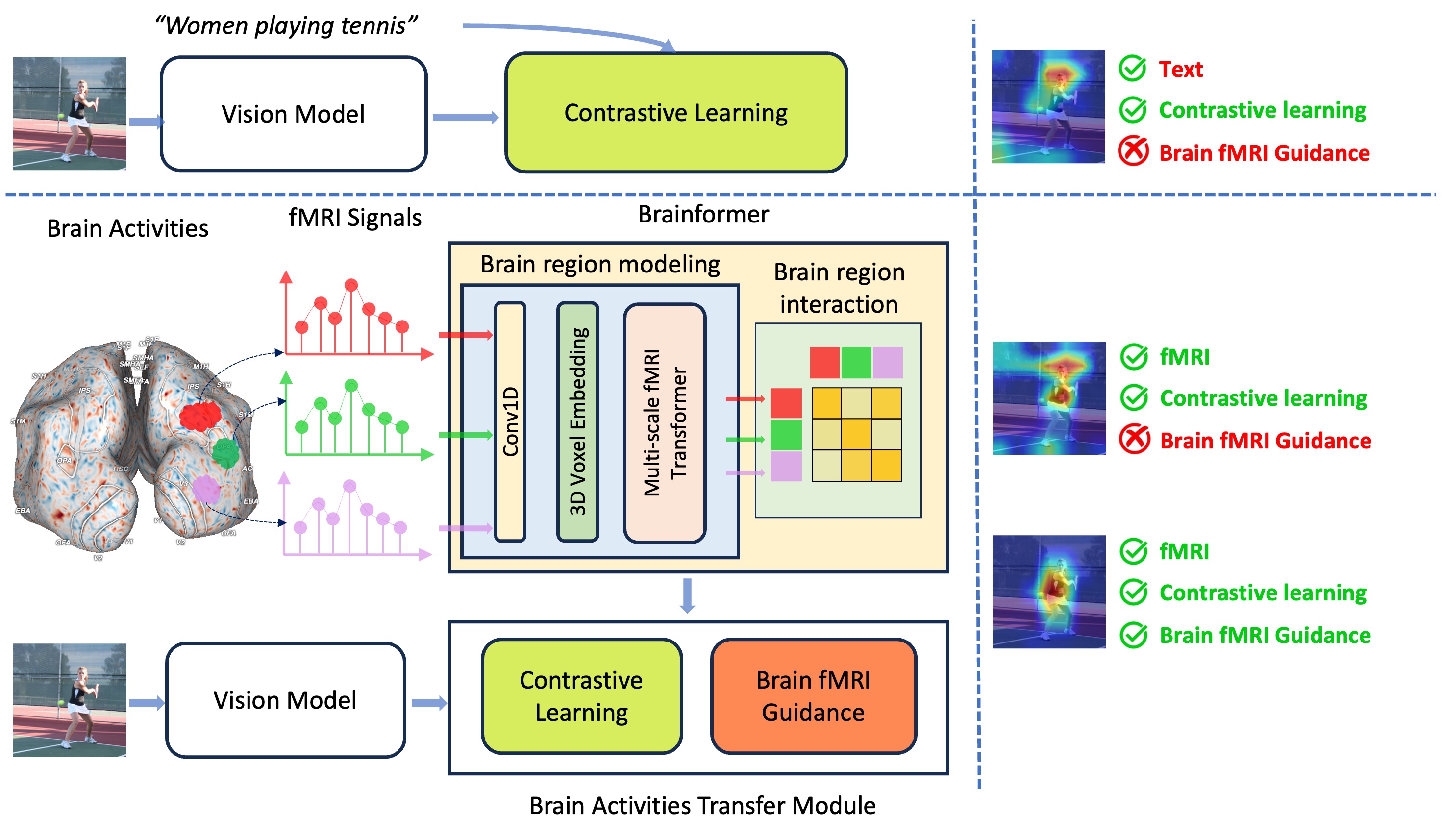
0
Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
Xuan-Bac Nguyen, Xin Li, Pawan Sinha, Samee U. Khan, Khoa Luu
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
Read more5/30/2024