Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
2406.04467
0
0

Abstract
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
Create account to get full access
Overview
- This paper introduces "Small-E", a small and efficient language model with linear attention for speech synthesis.
- The model aims to balance performance and efficiency, making it suitable for real-world speech synthesis applications.
- The authors explore various architectural choices and training strategies to create a compact yet capable model.
Plain English Explanation
The researchers have developed a new language model called "Small-E" that is designed for efficient speech synthesis. Speech synthesis is the process of generating human-like speech from text, and it has many practical applications, such as in virtual assistants, audiobooks, and text-to-speech software.
The key challenge the researchers are addressing is to create a language model that is small and efficient, while still maintaining high performance. Typically, larger and more complex language models tend to be more accurate, but they also require more computational resources, which can make them impractical for real-world use cases.
The researchers have explored various techniques to create a compact language model that can still produce high-quality speech. This includes using a linear attention mechanism, which is a more efficient way of processing the input text compared to traditional attention mechanisms. They have also experimented with different model architectures and training strategies to find the right balance between size, speed, and performance.
The goal is to develop a language model that can be deployed on a wide range of devices, from smartphones to embedded systems, without sacrificing the quality of the generated speech. This could pave the way for more accessible and ubiquitous speech synthesis technology, benefiting users in various applications.
Technical Explanation
The researchers propose a small and efficient language model called "Small-E" for speech synthesis tasks. To achieve this, they explore several architectural choices and training strategies:
-
Linear Attention Mechanism: Instead of using the standard attention mechanism, which can be computationally expensive, the researchers employ a linear attention mechanism that is more efficient and scalable. This allows the model to process the input text more quickly without sacrificing performance.
-
Model Architecture: The researchers experiment with different model architectures, including variations of Transformer-based models and other efficient designs, to find the right balance between size and performance.
-
Training Strategies: The researchers explore various training techniques, such as knowledge distillation and weight quantization, to compress the model while maintaining its capabilities. This helps to reduce the model's size and computational requirements.
-
Evaluation: The researchers evaluate the performance of Small-E on a range of speech synthesis benchmarks, including subjective listener tests and objective metrics. They compare the model's performance to larger, more complex language models as well as other efficient speech synthesis models, such as SimpleSpeech and CLAM-TTS.
The results show that Small-E can achieve competitive performance while being significantly smaller and more efficient than larger language models. This makes it a promising candidate for real-world speech synthesis applications that require low-latency and resource-constrained deployment, such as on mobile devices or embedded systems.
Critical Analysis
The researchers have made a reasonable effort to address the challenge of creating an efficient language model for speech synthesis. The use of a linear attention mechanism and various training strategies to compress the model are valid approaches to improve efficiency.
However, the paper does not delve into the potential limitations or trade-offs of the Small-E model. For example, it would be useful to understand how the model's performance scales with different input sizes or language complexities, and whether there are any specific domains or use cases where it may struggle compared to larger language models.
Additionally, the paper could have benefited from a more comprehensive comparison to other efficient speech synthesis models, such as Lean Attention or Towards Smaller, Faster Decoder-Only Transformers. This would help readers better understand the unique contributions and relative strengths of the Small-E model.
Overall, the research presented in this paper is a valuable contribution to the field of efficient speech synthesis, but some additional analysis and discussion of the model's limitations and trade-offs could strengthen the paper's impact.
Conclusion
The Small-E model proposed in this paper is a promising step towards developing efficient and compact language models for speech synthesis applications. By leveraging a linear attention mechanism and various compression techniques, the researchers have created a model that can deliver competitive performance while being significantly smaller and more efficient than larger language models.
This work could have important implications for the deployment of speech synthesis technology on a wide range of devices, from smartphones to embedded systems, where computational resources and power constraints are a critical concern. As the demand for accessible and ubiquitous speech synthesis continues to grow, research efforts like this one can help push the boundaries of what is possible in terms of balancing performance and efficiency.
Going forward, it would be valuable for the researchers to explore the model's performance in more diverse real-world scenarios, as well as to conduct a more in-depth comparison to other efficient speech synthesis models. This could further strengthen the understanding of Small-E's unique strengths and potential limitations, ultimately leading to even more impactful advancements in this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024
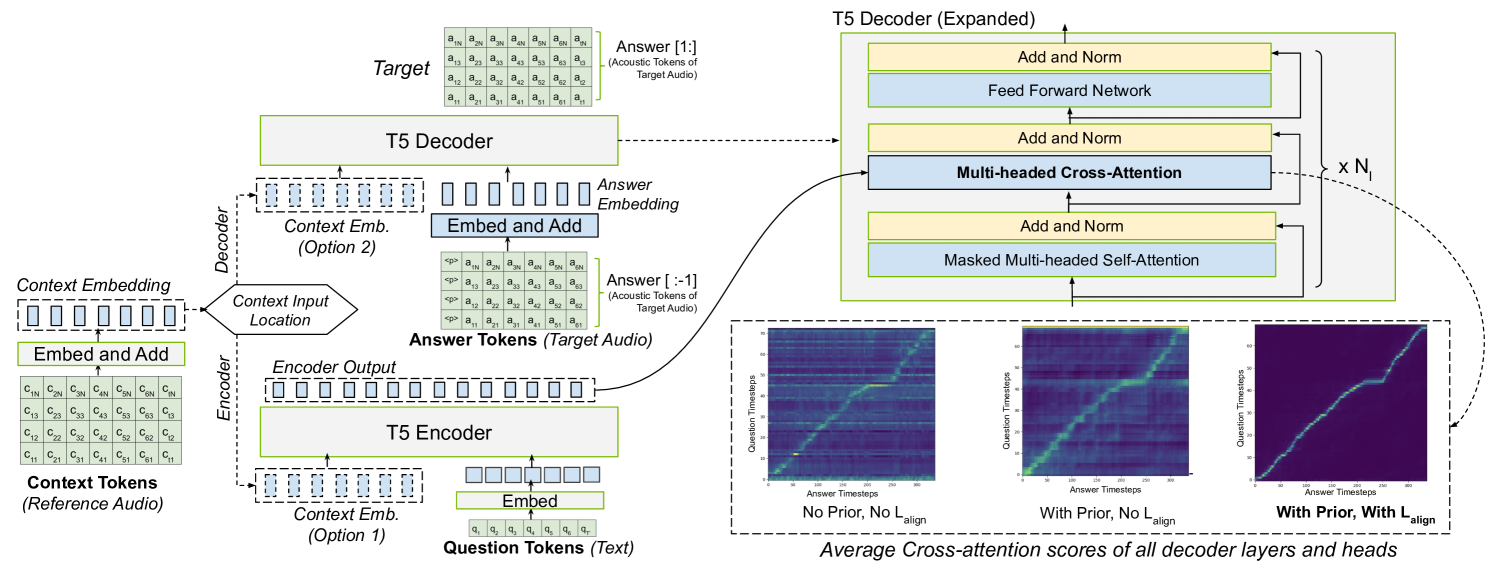
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Rafael Valle, Rohan Badlani, Boris Ginsburg
0
0
Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
6/27/2024
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Jaehyeon Kim, Keon Lee, Seungjun Chung, Jaewoong Cho
0
0
With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
4/4/2024

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024