Data Imputation with Iterative Graph Reconstruction
2212.02810
0
0
📊
Abstract
Effective data imputation demands rich latent structure discovery capabilities from plain tabular data. Recent advances in graph neural networks-based data imputation solutions show their strong structure learning potential by directly translating tabular data as bipartite graphs. However, due to a lack of relations between samples, those solutions treat all samples equally which is against one important observation: similar sample should give more information about missing values. This paper presents a novel Iterative graph Generation and Reconstruction framework for Missing data imputation(IGRM). Instead of treating all samples equally, we introduce the concept: friend networks to represent different relations among samples. To generate an accurate friend network with missing data, an end-to-end friend network reconstruction solution is designed to allow for continuous friend network optimization during imputation learning. The representation of the optimized friend network, in turn, is used to further optimize the data imputation process with differentiated message passing. Experiment results on eight benchmark datasets show that IGRM yields 39.13% lower mean absolute error compared with nine baselines and 9.04% lower than the second-best. Our code is available at https://github.com/G-AILab/IGRM.
Create account to get full access
Overview
- Addresses the challenge of effectively imputing missing data in tabular datasets
- Proposes a novel Iterative Graph Generation and Reconstruction framework for Missing data imputation (IGRM)
- Introduces the concept of "friend networks" to represent different relations among samples, improving upon previous graph neural network-based solutions
Plain English Explanation
Missing data is a common problem in many datasets, and accurately filling in those gaps is crucial for effective data analysis. Recent advances in graph neural networks-based data imputation solutions have shown promise by representing tabular data as bipartite graphs. However, these solutions treat all samples equally, which goes against the observation that "similar samples should give more information about missing values."
The IGRM framework introduced in this paper aims to address this limitation. Instead of treating all samples equally, IGRM introduces the concept of "friend networks" to represent the different relationships between samples. This allows the model to prioritize information from more similar samples when imputing missing values. To generate an accurate friend network, the framework includes an end-to-end solution for continuously optimizing the friend network during the imputation learning process.
The optimized friend network representation is then used to further refine the data imputation process, using differentiated message passing to leverage the insights from the friend network. This results in more accurate imputation of missing values compared to previous approaches.
Technical Explanation
The key elements of the IGRM framework are:
-
Friend Network Reconstruction: The model learns an end-to-end solution to reconstruct a "friend network" that represents the relationships between samples. This is done by continuously optimizing the friend network during the imputation learning process.
-
Differentiated Message Passing: The optimized friend network representation is used to inform the data imputation process, with differentiated message passing that gives more weight to information from more similar "friend" samples.
The authors evaluate IGRM on eight benchmark datasets and show that it outperforms nine baseline methods, achieving a 39.13% lower mean absolute error than the best baseline and a 9.04% improvement over the second-best method.
Critical Analysis
The paper presents a novel and promising approach to data imputation, leveraging the relationships between samples to improve the quality of imputations. However, some potential limitations and areas for further research include:
- The performance of the friend network reconstruction component and its impact on the overall imputation accuracy could be further explored.
- The scalability of the IGRM framework, especially for large-scale datasets, is not discussed in detail and may warrant additional investigation.
- The paper does not provide a detailed comparison to other graph-based imputation methods or clustering-based approaches for missing data, which could offer additional insights.
- The generalization of the IGRM framework to other types of data, beyond tabular datasets, could be an interesting area for future research.
Conclusion
The IGRM framework presented in this paper offers a novel approach to data imputation, leveraging the concept of "friend networks" to better capture the relationships between samples and improve the accuracy of missing value imputations. The strong experimental results demonstrate the potential of this method and highlight the importance of considering the inherent structure within tabular data when designing effective imputation solutions.
The paper's insights contribute to the ongoing efforts to address the challenge of missing data, which is a pervasive issue in many real-world datasets. The IGRM framework's ability to outperform a range of baseline methods suggests that it could be a valuable tool for researchers and practitioners working with incomplete data, with potential applications across a wide variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
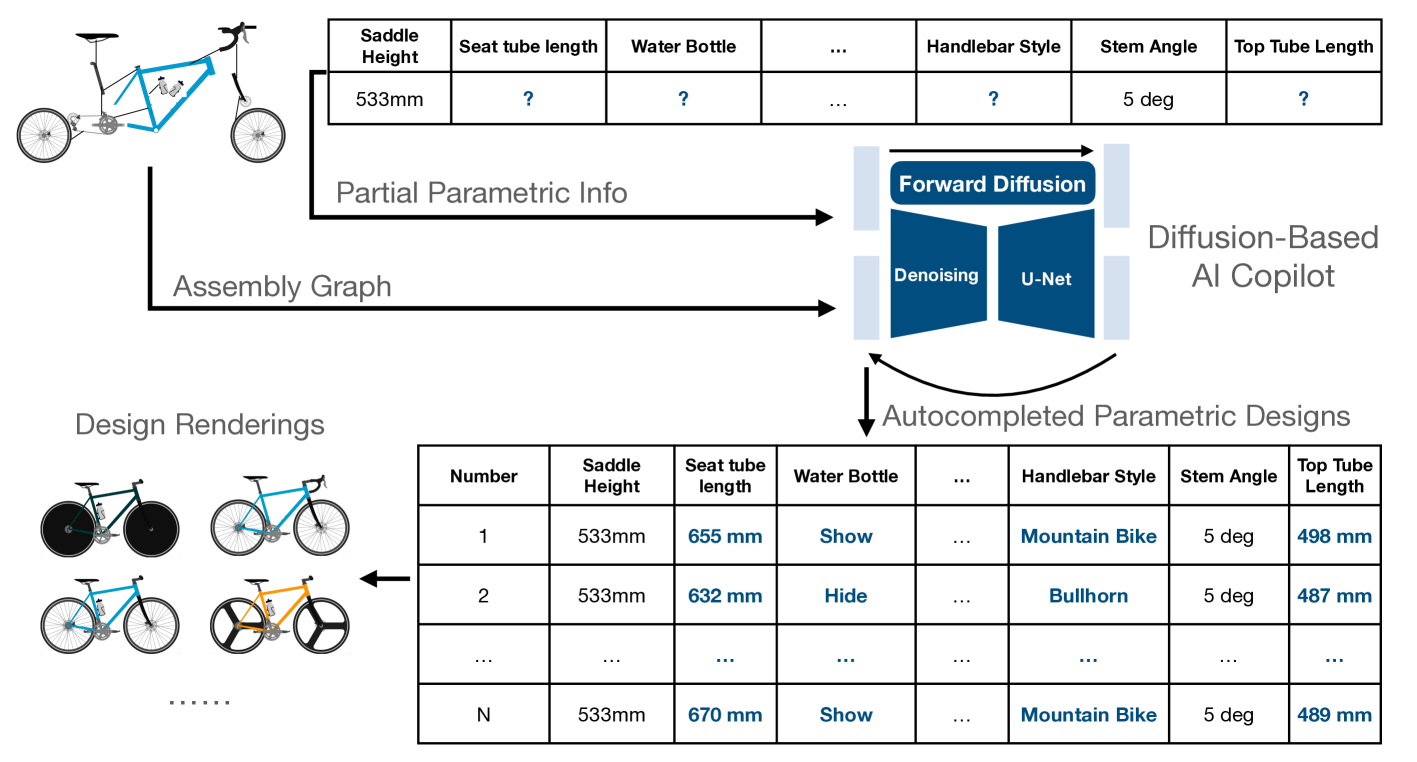
Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
Rui Zhou, Chenyang Yuan, Frank Permenter, Yanxia Zhang, Nikos Arechiga, Matt Klenk, Faez Ahmed
0
0
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
6/19/2024
DPGAN: A Dual-Path Generative Adversarial Network for Missing Data Imputation in Graphs
Xindi Zheng, Yuwei Wu, Yu Pan, Wanyu Lin, Lei Ma, Jianjun Zhao
0
0
Missing data imputation poses a paramount challenge when dealing with graph data. Prior works typically are based on feature propagation or graph autoencoders to address this issue. However, these methods usually encounter the over-smoothing issue when dealing with missing data, as the graph neural network (GNN) modules are not explicitly designed for handling missing data. This paper proposes a novel framework, called Dual-Path Generative Adversarial Network (DPGAN), that can deal simultaneously with missing data and avoid over-smoothing problems. The crux of our work is that it admits both global and local representations of the input graph signal, which can capture the long-range dependencies. It is realized via our proposed generator, consisting of two key components, i.e., MLPUNet++ and GraphUNet++. Our generator is trained with a designated discriminator via an adversarial process. In particular, to avoid assessing the entire graph as did in the literature, our discriminator focuses on the local subgraph fidelity, thereby boosting the quality of the local imputation. The subgraph size is adjustable, allowing for control over the intensity of adversarial regularization. Comprehensive experiments across various benchmark datasets substantiate that DPGAN consistently rivals, if not outperforms, existing state-of-the-art imputation algorithms. The code is provided at url{https://github.com/momoxia/DPGAN}.
4/29/2024

Physics-incorporated Graph Neural Network for Multivariate Time Series Imputation
Guojun Liang, Prayag Tiwari, Slawomir Nowaczyk, Stefan Byttner
0
0
Exploring the missing values is an essential but challenging issue due to the complex latent spatio-temporal correlation and dynamic nature of time series. Owing to the outstanding performance in dealing with structure learning potentials, Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) are often used to capture such complex spatio-temporal features in multivariate time series. However, these data-driven models often fail to capture the essential spatio-temporal relationships when significant signal corruption occurs. Additionally, calculating the high-order neighbor nodes in these models is of high computational complexity. To address these problems, we propose a novel higher-order spatio-temporal physics-incorporated GNN (HSPGNN). Firstly, the dynamic Laplacian matrix can be obtained by the spatial attention mechanism. Then, the generic inhomogeneous partial differential equation (PDE) of physical dynamic systems is used to construct the dynamic higher-order spatio-temporal GNN to obtain the missing time series values. Moreover, we estimate the missing impact by Normalizing Flows (NF) to evaluate the importance of each node in the graph for better explainability. Experimental results on four benchmark datasets demonstrate the effectiveness of HSPGNN and the superior performance when combining various order neighbor nodes. Also, graph-like optical flow, dynamic graphs, and missing impact can be obtained naturally by HSPGNN, which provides better dynamic analysis and explanation than traditional data-driven models. Our code is available at https://github.com/gorgen2020/HSPGNN.
5/21/2024

MagiNet: Mask-Aware Graph Imputation Network for Incomplete Traffic Data
Jianping Zhou, Bin Lu, Zhanyu Liu, Siyu Pan, Xuejun Feng, Hua Wei, Guanjie Zheng, Xinbing Wang, Chenghu Zhou
0
0
Due to detector malfunctions and communication failures, missing data is ubiquitous during the collection of traffic data. Therefore, it is of vital importance to impute the missing values to facilitate data analysis and decision-making for Intelligent Transportation System (ITS). However, existing imputation methods generally perform zero pre-filling techniques to initialize missing values, introducing inevitable noises. Moreover, we observe prevalent over-smoothing interpolations, falling short in revealing the intrinsic spatio-temporal correlations of incomplete traffic data. To this end, we propose Mask-Aware Graph imputation Network: MagiNet. Our method designs an adaptive mask spatio-temporal encoder to learn the latent representations of incomplete data, eliminating the reliance on pre-filling missing values. Furthermore, we devise a spatio-temporal decoder that stacks multiple blocks to capture the inherent spatial and temporal dependencies within incomplete traffic data, alleviating over-smoothing imputation. Extensive experiments demonstrate that our method outperforms state-of-the-art imputation methods on five real-world traffic datasets, yielding an average improvement of 4.31% in RMSE and 3.72% in MAPE.
6/7/2024