Bridging the Gap between Different Vocabularies for LLM Ensemble
2404.09492
0
0

Abstract
Ensembling different large language models (LLMs) to unleash their complementary potential and harness their individual strengths is highly valuable. Nevertheless, vocabulary discrepancies among various LLMs have constrained previous studies to either selecting or blending completely generated outputs. This limitation hinders the dynamic correction and enhancement of outputs during the generation process, resulting in a limited capacity for effective ensemble. To address this issue, we propose a novel method to Ensemble LLMs via Vocabulary Alignment (EVA). EVA bridges the lexical gap among various LLMs, enabling meticulous ensemble at each generation step. Specifically, we first learn mappings between the vocabularies of different LLMs with the assistance of overlapping tokens. Subsequently, these mappings are employed to project output distributions of LLMs into a unified space, facilitating a fine-grained ensemble. Finally, we design a filtering strategy to exclude models that generate unfaithful tokens. Experimental results on commonsense reasoning, arithmetic reasoning, machine translation, and data-to-text generation tasks demonstrate the superiority of our approach compared with individual LLMs and previous ensemble methods conducted on complete outputs. Further analyses confirm that our approach can leverage knowledge from different language models and yield consistent improvement.
Create account to get full access
Overview
- This paper explores the "vocabulary overlap phenomenon" in large language model (LLM) ensembles, where models with different vocabularies struggle to communicate effectively.
- The researchers propose a novel method to bridge the gap between different vocabularies, enabling more seamless collaboration between diverse LLM models.
- The approach involves learning a cross-model mapping that aligns the vocabularies and representations of different LLMs, improving their ability to work together on complex tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 and SambaLingo have become incredibly powerful tools for a wide range of language-related tasks. However, when you combine multiple LLMs together into an "ensemble" to leverage their different strengths, they can struggle to understand each other due to differences in their vocabularies.
The researchers in this paper noticed that LLMs often develop their own unique vocabularies, even when trained on similar data. This "vocabulary overlap phenomenon" can create barriers to effective communication and collaboration between the models. To address this, the researchers developed a new method to bridge the gap between the vocabularies of different LLMs.
Their approach involves learning a cross-model mapping that aligns the representations and vocabularies of the individual models. This allows the models to better understand each other, making the ensemble more effective at completing complex tasks that require the diverse capabilities of multiple LLMs.
By overcoming the challenges posed by vocabulary differences, this research helps pave the way for more seamless integration and cooperation between diverse LLM models, unlocking new possibilities for advanced AI systems that can tackle increasingly complex problems.
Technical Explanation
The paper begins by identifying the "vocabulary overlap phenomenon" as a key challenge in LLM ensembles. The researchers observe that even when LLMs are trained on similar data, they often develop distinct vocabularies, making it difficult for them to effectively communicate and collaborate.
To address this issue, the researchers propose a novel method for learning a cross-model mapping that aligns the vocabularies and representations of different LLMs. This mapping allows the models to bridge the gap between their unique vocabularies, enabling them to better understand each other's outputs and work together more effectively.
The proposed approach involves training a neural network to learn the cross-model mapping, using a combination of supervised and unsupervised learning techniques. The researchers evaluate their method on several benchmark tasks, demonstrating that the ensemble of LLMs with aligned vocabularies outperforms both individual models and ensembles without the vocabulary alignment.
The paper also provides insights into the impact of vocabulary distinction on LLM ensemble performance, highlighting the importance of addressing this challenge for more seamless integration and cooperation between diverse LLM models.
Critical Analysis
The researchers have identified an important and practical challenge in the field of LLM ensembles, and their proposed approach offers a promising solution. By addressing the "vocabulary overlap phenomenon," the method helps to overcome a significant barrier to effective collaboration between different LLMs.
However, the paper does not delve into the potential limitations or caveats of the proposed approach. For example, it would be helpful to understand how the cross-model mapping performs when the underlying LLMs have more substantial differences in their architectures or training data, as this could impact the effectiveness of the alignment.
Additionally, the paper does not discuss the computational and memory requirements of the cross-model mapping, which could be an important consideration for real-world applications, especially when scaling to larger and more diverse LLM ensembles.
Further research could also explore the long-term implications of this approach, such as how it might affect the interpretability and transparency of the overall LLM ensemble, or how it might impact the fairness and bias of the system's outputs.
Despite these potential areas for further exploration, the core contribution of this paper – bridging the vocabulary gap between LLMs – represents an important step forward in enabling more seamless and effective cooperation between diverse AI models, which could have significant implications for the development of advanced AI systems and their applications.
Conclusion
This paper tackles the crucial challenge of the "vocabulary overlap phenomenon" in LLM ensembles, where differences in the vocabularies of individual models can hinder their ability to collaborate effectively. The researchers' proposed method of learning a cross-model mapping to align the vocabularies of different LLMs represents a significant advancement in this area.
By enabling LLMs to better understand each other's outputs, this approach helps to bridge the gap between diverse AI models, paving the way for more seamless integration and cooperation. This, in turn, could unlock new possibilities for advanced AI systems that can tackle increasingly complex problems by leveraging the unique strengths of multiple LLMs working together.
As the field of AI continues to evolve, addressing challenges like the vocabulary overlap phenomenon will be crucial for realizing the full potential of LLM ensembles and other collaborative AI architectures. This paper makes an important contribution to this ongoing effort, and its findings could have far-reaching implications for the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enabling Ensemble Learning for Heterogeneous Large Language Models with Deep Parallel Collaboration
Yichong Huang, Xiaocheng Feng, Baohang Li, Yang Xiang, Hui Wang, Bing Qin, Ting Liu
0
0
Large language models (LLMs) exhibit complementary strengths in various tasks, motivating the research of LLM ensembling. However, existing work focuses on training an extra reward model or fusion model to select or combine all candidate answers, posing a great challenge to the generalization on unseen data distributions. Besides, prior methods use textual responses as communication media, ignoring the valuable information in the internal representations. In this work, we propose a training-free ensemble framework DeePEn, fusing the informative probability distributions yielded by different LLMs at each decoding step. Unfortunately, the vocabulary discrepancy between heterogeneous LLMs directly makes averaging the distributions unfeasible due to the token misalignment. To address this challenge, DeePEn maps the probability distribution of each model from its own probability space to a universal relative space based on the relative representation theory, and performs aggregation. Next, we devise a search-based inverse transformation to transform the aggregated result back to the probability space of one of the ensembling LLMs (main model), in order to determine the next token. We conduct extensive experiments on ensembles of different number of LLMs, ensembles of LLMs with different architectures, and ensembles between the LLM and the specialist model. Experimental results show that (i) DeePEn achieves consistent improvements across six benchmarks covering subject examination, reasoning, and knowledge, (ii) a well-performing specialist model can benefit from a less effective LLM through distribution fusion, and (iii) DeePEn has complementary strengths with other ensemble methods such as voting.
5/31/2024
💬
An Empirical Study on Cross-lingual Vocabulary Adaptation for Efficient Language Model Inference
Atsuki Yamaguchi, Aline Villavicencio, Nikolaos Aletras
0
0
The development of state-of-the-art generative large language models (LLMs) disproportionately relies on English-centric tokenizers, vocabulary and pre-training data. Despite the fact that some LLMs have multilingual capabilities, recent studies have shown that their inference efficiency deteriorates when generating text in languages other than English. This results in increased inference time and costs. Cross-lingual vocabulary adaptation (CVA) methods have been proposed for adapting models to a target language aiming to improve downstream performance. However, the effectiveness of these methods on increasing inference efficiency of generative LLMs has yet to be explored. In this paper, we perform an empirical study of five CVA methods on four generative LLMs (including monolingual and multilingual models) across four typologically-diverse languages and four natural language understanding tasks. We find that CVA substantially contributes to LLM inference speedups of up to 271.5%. We also show that adapting LLMs that have been pre-trained on more balanced multilingual data results in downstream performance comparable to the original models.
6/18/2024
🔮
How Vocabulary Sharing Facilitates Multilingualism in LLaMA?
Fei Yuan, Shuai Yuan, Zhiyong Wu, Lei Li
0
0
Large Language Models (LLMs), often show strong performance on English tasks, while exhibiting limitations on other languages. What is an LLM's multilingual capability when it is trained only on certain languages? The underlying mechanism remains unclear. This study endeavors to examine the multilingual capability of LLMs from the vocabulary sharing perspective by conducting an exhaustive analysis across 101 languages. Through the investigation of the performance gap before and after embedding fine-tuning, we discovered four distinct quadrants. By delving into each quadrant we provide actionable and efficient guidelines for tuning these languages. Extensive experiments reveal that existing LLMs possess multilingual capabilities that surpass our expectations, and we can significantly improve the multilingual performance of LLMs based on these attributes of each quadrant~footnote{url{https://github.com/CONE-MT/Vocabulary-Sharing-Facilitates-Multilingualism}.}.
6/4/2024
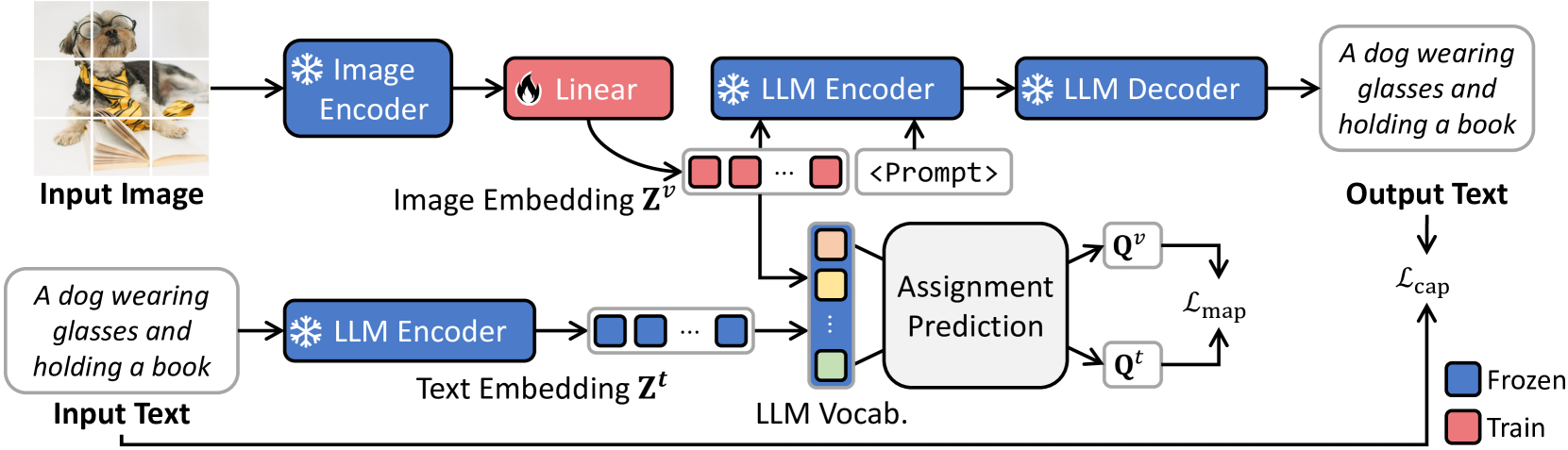
Bridging Vision and Language Spaces with Assignment Prediction
Jungin Park, Jiyoung Lee, Kwanghoon Sohn
0
0
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
4/16/2024