Improving Interpretable Embeddings for Ad-hoc Video Search with Generative Captions and Multi-word Concept Bank
2404.06173
0
0

Abstract
Aligning a user query and video clips in cross-modal latent space and that with semantic concepts are two mainstream approaches for ad-hoc video search (AVS). However, the effectiveness of existing approaches is bottlenecked by the small sizes of available video-text datasets and the low quality of concept banks, which results in the failures of unseen queries and the out-of-vocabulary problem. This paper addresses these two problems by constructing a new dataset and developing a multi-word concept bank. Specifically, capitalizing on a generative model, we construct a new dataset consisting of 7 million generated text and video pairs for pre-training. To tackle the out-of-vocabulary problem, we develop a multi-word concept bank based on syntax analysis to enhance the capability of a state-of-the-art interpretable AVS method in modeling relationships between query words. We also study the impact of current advanced features on the method. Experimental results show that the integration of the above-proposed elements doubles the R@1 performance of the AVS method on the MSRVTT dataset and improves the xinfAP on the TRECVid AVS query sets for 2016-2023 (eight years) by a margin from 2% to 77%, with an average about 20%.
Create account to get full access
Overview
- This paper presents a method to improve interpretable embeddings for ad-hoc video search using generative captions and a multi-word concept bank.
- The approach involves constructing a large-scale video-text dataset and using it to learn interpretable video representations that can capture complex visual concepts.
- The learned embeddings are shown to outperform existing methods on ad-hoc video search tasks, demonstrating the effectiveness of the proposed techniques.
Plain English Explanation
The paper focuses on improving how computers can understand and search through videos. When you search for a video online, the computer needs to be able to match what's in the video to your search query. This can be challenging, especially for complex or unusual search terms.
The researchers developed a new way to train the computer to better understand the content of videos. First, they built a large dataset of videos paired with descriptive captions. This helped the computer learn to associate visual elements in the videos with specific language concepts.
They also created a "concept bank" - a collection of multi-word phrases that describe common visual ideas, like "dog playing fetch" or "person riding a bike". This gave the computer a more nuanced understanding of the complex concepts found in videos.
By using this generative caption data and concept bank, the researchers were able to train the computer to create "interpretable embeddings" - mathematical representations of the video content that are easy for humans to understand. These improved embeddings allowed the computer to perform better at finding relevant videos when users searched for specific topics or actions.
The key insight is that providing the computer with richer, more human-like language descriptions of visual content helps it build a more sophisticated understanding. This in turn improves its ability to match videos to the complex, real-world search queries that users might have.
Technical Explanation
The paper first describes the construction of a large-scale video-text dataset, which pairs videos with multiple descriptive captions generated using a transformer-based model. This dataset serves as the foundation for learning interpretable video representations.
The researchers then propose a novel "concept bank" - a collection of multi-word phrases that capture common visual concepts. This concept bank is constructed by clustering video-caption pairs and extracting representative multi-word expressions. The concept bank allows the model to learn embeddings that can capture more complex semantics compared to single-word vocabularies.
To learn the interpretable video embeddings, the model is trained to predict the concept bank labels in addition to the generative captions. This "multi-task" learning objective encourages the model to discover visual-linguistic associations that are both descriptive and conceptually interpretable.
Experiments on ad-hoc video search benchmarks demonstrate that the proposed approach outperforms state-of-the-art methods in both retrieval and zero-shot video classification tasks. The interpretable embeddings learned by the model are shown to be more effective at capturing the semantic content of videos compared to existing techniques.
Critical Analysis
The paper presents a thorough and well-designed approach to improving interpretable video representations for ad-hoc search. The key strengths are the novel concept bank construction and the multi-task training objective that leverages both generative captions and conceptual labels.
One potential limitation is the reliance on a pre-defined set of multi-word phrases in the concept bank. While the researchers show this approach is effective, there may be opportunities to further improve the concept discovery process, perhaps through unsupervised or open-vocabulary techniques as explored in Understanding Video Transformers via Universal Concept Discovery.
Additionally, the paper does not explore the model's ability to handle "out-of-vocabulary" search queries that fall outside the concept bank. Techniques like Open Vocabulary Keyword Spotting through Transfer Learning could potentially be integrated to address this limitation.
Overall, the proposed methods represent a promising direction for advancing interpretable video understanding and search. The insights from this work could also inform other areas of visual-linguistic modeling, such as Language-Informed Visual Concept Learning and Video-Text Retrieval.
Conclusion
This paper introduces a novel approach to learning interpretable video embeddings for ad-hoc search tasks. By leveraging a large-scale video-text dataset and a multi-word concept bank, the proposed method is able to capture complex visual semantics in a human-understandable way.
The resulting embeddings demonstrate strong performance on video retrieval and zero-shot classification benchmarks, outperforming existing techniques. This work represents an important step forward in bridging the gap between machine understanding of video content and the nuanced way humans describe and search for visual information.
The insights from this research could have broader implications for improving multimodal learning and reasoning, with potential applications in areas like video-text retrieval, visual concept learning, and video understanding. As the field continues to advance, techniques like those presented in this paper will play a crucial role in making AI systems more interpretable and aligned with human cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Towards Holistic Language-video Representation: the language model-enhanced MSR-Video to Text Dataset
Yuchen Yang, Yingxuan Duan
0
0
A more robust and holistic language-video representation is the key to pushing video understanding forward. Despite the improvement in training strategies, the quality of the language-video dataset is less attention to. The current plain and simple text descriptions and the visual-only focus for the language-video tasks result in a limited capacity in real-world natural language video retrieval tasks where queries are much more complex. This paper introduces a method to automatically enhance video-language datasets, making them more modality and context-aware for more sophisticated representation learning needs, hence helping all downstream tasks. Our multifaceted video captioning method captures entities, actions, speech transcripts, aesthetics, and emotional cues, providing detailed and correlating information from the text side to the video side for training. We also develop an agent-like strategy using language models to generate high-quality, factual textual descriptions, reducing human intervention and enabling scalability. The method's effectiveness in improving language-video representation is evaluated through text-video retrieval using the MSR-VTT dataset and several multi-modal retrieval models.
6/21/2024

Video Enriched Retrieval Augmented Generation Using Aligned Video Captions
Kevin Dela Rosa
0
0
In this work, we propose the use of aligned visual captions as a mechanism for integrating information contained within videos into retrieval augmented generation (RAG) based chat assistant systems. These captions are able to describe the visual and audio content of videos in a large corpus while having the advantage of being in a textual format that is both easy to reason about & incorporate into large language model (LLM) prompts, but also typically require less multimedia content to be inserted into the multimodal LLM context window, where typical configurations can aggressively fill up the context window by sampling video frames from the source video. Furthermore, visual captions can be adapted to specific use cases by prompting the original foundational model / captioner for particular visual details or fine tuning. In hopes of helping advancing progress in this area, we curate a dataset and describe automatic evaluation procedures on common RAG tasks.
5/29/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024
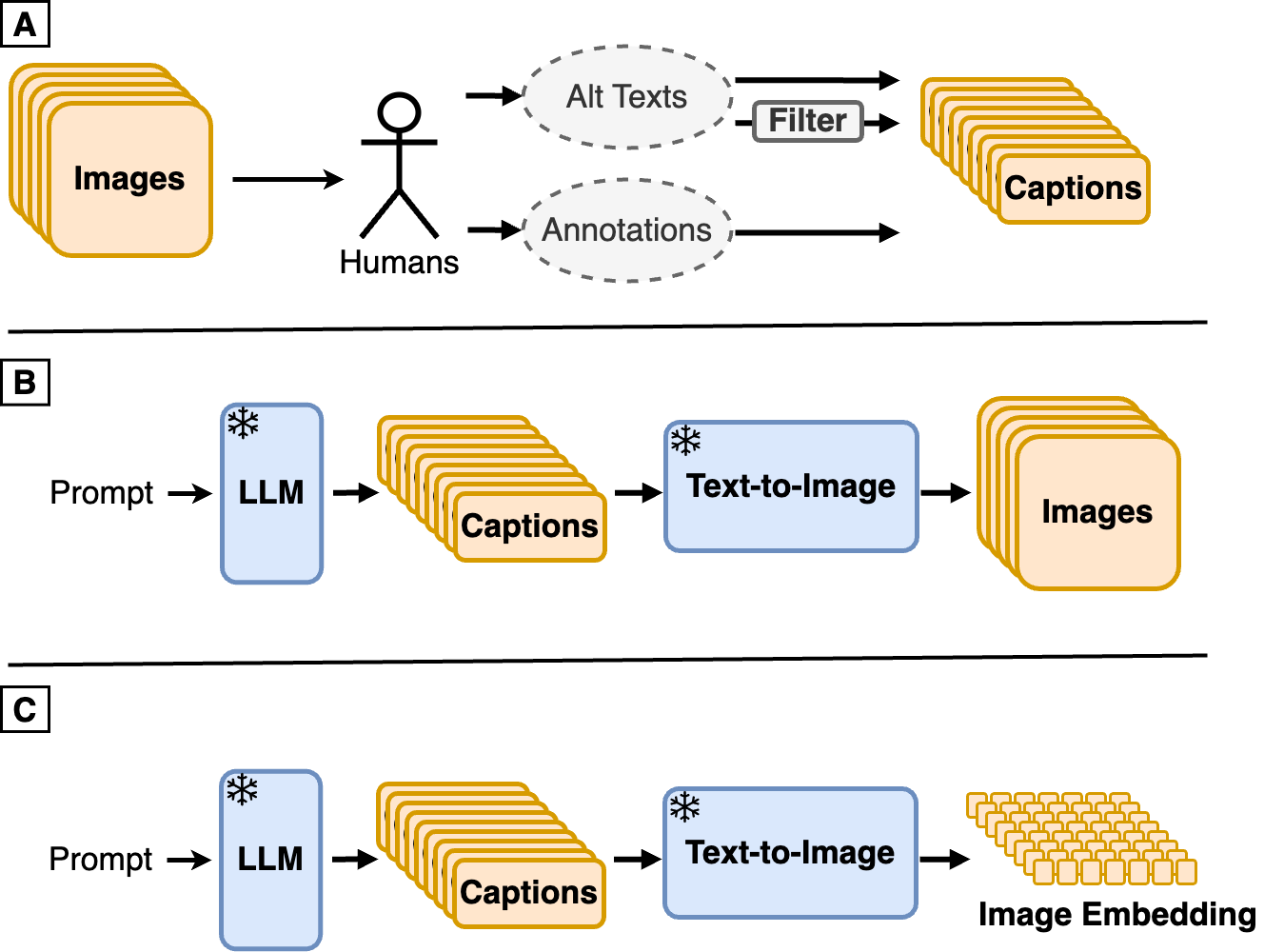
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024