Directly Fine-Tuning Diffusion Models on Differentiable Rewards
2309.17400
2
0
📊
Abstract
We present Direct Reward Fine-Tuning (DRaFT), a simple and effective method for fine-tuning diffusion models to maximize differentiable reward functions, such as scores from human preference models. We first show that it is possible to backpropagate the reward function gradient through the full sampling procedure, and that doing so achieves strong performance on a variety of rewards, outperforming reinforcement learning-based approaches. We then propose more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation to only the last K steps of sampling, and DRaFT-LV, which obtains lower-variance gradient estimates for the case when K=1. We show that our methods work well for a variety of reward functions and can be used to substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4. Finally, we draw connections between our approach and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
Create account to get full access
Overview
- Presents a method called Direct Reward Fine-Tuning (DRaFT) for fine-tuning diffusion models to maximize differentiable reward functions
- Shows that it's possible to backpropagate the reward function gradient through the full sampling procedure, outperforming reinforcement learning-based approaches
- Proposes more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation, and DRaFT-LV, which obtains lower-variance gradient estimates
- Demonstrates that the methods can substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4
- Provides a unifying perspective on the design space of gradient-based fine-tuning algorithms
Plain English Explanation
The paper introduces a new method called Direct Reward Fine-Tuning (DRaFT) for improving the performance of diffusion models on specific tasks. Diffusion models are a type of machine learning model that can generate images, text, and other types of data.
The key idea behind DRaFT is to fine-tune these diffusion models to maximize a differentiable reward function, such as a score from a human preference model. This means that the model can be trained to generate outputs that are preferred by humans, rather than just following the original training data.
The researchers show that it's possible to backpropagate the gradient of the reward function all the way through the sampling process used to generate the outputs. This allows the model to be directly optimized for the desired reward, rather than using a more indirect reinforcement learning approach.
The paper also proposes two more efficient variants of DRaFT: DRaFT-K, which only backpropagates the gradient for the last K steps of the sampling process, and DRaFT-LV, which uses a lower-variance gradient estimate when K=1. These variants can make the training process more efficient while still achieving strong results.
The researchers demonstrate that DRaFT can be used to substantially improve the aesthetic quality of images generated by the popular Stable Diffusion 1.4 model. This suggests that the technique could be broadly applicable to improving the performance of diffusion models on a variety of tasks.
Finally, the paper provides a unifying perspective on the design space of gradient-based fine-tuning algorithms, connecting DRaFT to prior work in this area.
Technical Explanation
The core idea behind Direct Reward Fine-Tuning (DRaFT) is to fine-tune diffusion models to directly optimize a differentiable reward function, such as a score from a human preference model. This is in contrast to more indirect reinforcement learning approaches.
The researchers show that it is possible to backpropagate the gradient of the reward function all the way through the sampling procedure used to generate the outputs of the diffusion model. This allows the model to be directly optimized for the desired reward, rather than just following the original training data.
The paper proposes two more efficient variants of DRaFT:
- DRaFT-K: This method truncates the backpropagation to only the last K steps of the sampling process, reducing the computational cost.
- DRaFT-LV: This method obtains lower-variance gradient estimates for the case when K=1, further improving efficiency.
The researchers demonstrate that these DRaFT methods can substantially improve the aesthetic quality of images generated by the Stable Diffusion 1.4 model, outperforming reinforcement learning-based approaches.
The paper also draws connections between DRaFT and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
Critical Analysis
The paper presents a promising approach for fine-tuning diffusion models to optimize for specific reward functions, such as human preferences. The key strength of the DRaFT method is its ability to directly backpropagate the gradient of the reward function through the full sampling procedure, which allows for more effective optimization.
However, the paper does not address some potential limitations of the approach. For example, it's unclear how well DRaFT would scale to more complex reward functions or to larger-scale diffusion models. Additionally, the paper does not explore the robustness of the method to different types of reward functions or to distribution shift in the training data.
Further research could also investigate the potential for misuse of DRaFT, such as optimizing diffusion models to produce outputs that are deceptive or harmful. Careful consideration of the ethical implications of this technology will be important as it continues to develop.
Overall, the DRaFT method is a promising step forward in the field of diffusion model fine-tuning, but there are still open questions and areas for further exploration.
Conclusion
The Direct Reward Fine-Tuning (DRaFT) method presented in this paper offers a novel approach for fine-tuning diffusion models to optimize for specific reward functions, such as human preferences. By directly backpropagating the gradient of the reward function through the full sampling procedure, DRaFT and its variants can substantially improve the performance of diffusion models on a variety of tasks.
This work provides a unifying perspective on the design space of gradient-based fine-tuning algorithms, connecting DRaFT to prior research in this area. While the method shows promise, further research is needed to explore its scalability, robustness, and potential for misuse. Nonetheless, DRaFT represents an important advancement in the field of diffusion model optimization and could have significant implications for the development of more capable and aligned artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
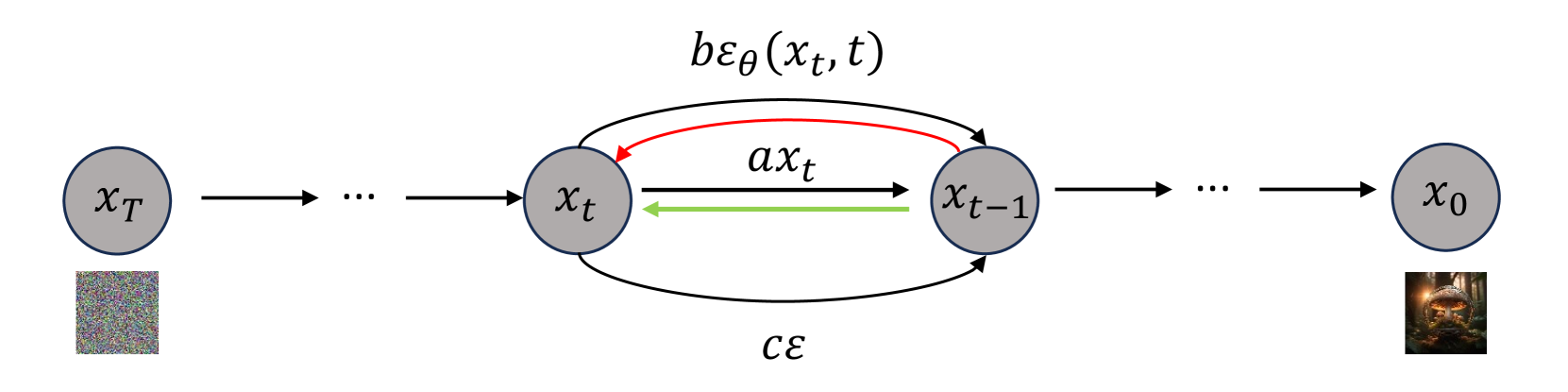
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
Xiaoshi Wu, Yiming Hao, Manyuan Zhang, Keqiang Sun, Zhaoyang Huang, Guanglu Song, Yu Liu, Hongsheng Li
0
0
Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
5/3/2024
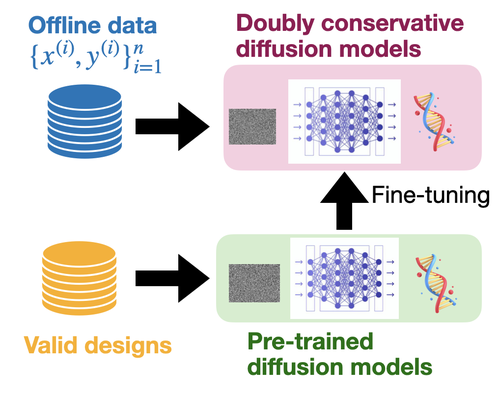
Bridging Model-Based Optimization and Generative Modeling via Conservative Fine-Tuning of Diffusion Models
Masatoshi Uehara, Yulai Zhao, Ehsan Hajiramezanali, Gabriele Scalia, Gokcen Eraslan, Avantika Lal, Sergey Levine, Tommaso Biancalani
0
0
AI-driven design problems, such as DNA/protein sequence design, are commonly tackled from two angles: generative modeling, which efficiently captures the feasible design space (e.g., natural images or biological sequences), and model-based optimization, which utilizes reward models for extrapolation. To combine the strengths of both approaches, we adopt a hybrid method that fine-tunes cutting-edge diffusion models by optimizing reward models through RL. Although prior work has explored similar avenues, they primarily focus on scenarios where accurate reward models are accessible. In contrast, we concentrate on an offline setting where a reward model is unknown, and we must learn from static offline datasets, a common scenario in scientific domains. In offline scenarios, existing approaches tend to suffer from overoptimization, as they may be misled by the reward model in out-of-distribution regions. To address this, we introduce a conservative fine-tuning approach, BRAID, by optimizing a conservative reward model, which includes additional penalization outside of offline data distributions. Through empirical and theoretical analysis, we demonstrate the capability of our approach to outperform the best designs in offline data, leveraging the extrapolation capabilities of reward models while avoiding the generation of invalid designs through pre-trained diffusion models.
6/4/2024

Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization
Zhiwei Tang, Jiangweizhi Peng, Jiasheng Tang, Mingyi Hong, Fan Wang, Tsung-Hui Chang
0
0
In this work, we focus on the alignment problem of diffusion models with a continuous reward function, which represents specific objectives for downstream tasks, such as improving human preference. The central goal of the alignment problem is to adjust the distribution learned by diffusion models such that the generated samples maximize the target reward function. We propose a novel alignment approach, named Direct Noise Optimization (DNO), that optimizes the injected noise during the sampling process of diffusion models. By design, DNO is tuning-free and prompt-agnostic, as the alignment occurs in an online fashion during generation. We rigorously study the theoretical properties of DNO and also propose variants to deal with non-differentiable reward functions. Furthermore, we identify that naive implementation of DNO occasionally suffers from the out-of-distribution reward hacking problem, where optimized samples have high rewards but are no longer in the support of the pretrained distribution. To remedy this issue, we leverage classical high-dimensional statistics theory and propose to augment the DNO loss with certain probability regularization. We conduct extensive experiments on several popular reward functions trained on human feedback data and demonstrate that the proposed DNO approach achieves state-of-the-art reward scores as well as high image quality, all within a reasonable time budget for generation.
5/30/2024

Efficient Differentially Private Fine-Tuning of Diffusion Models
Jing Liu, Andrew Lowy, Toshiaki Koike-Akino, Kieran Parsons, Ye Wang
0
0
The recent developments of Diffusion Models (DMs) enable generation of astonishingly high-quality synthetic samples. Recent work showed that the synthetic samples generated by the diffusion model, which is pre-trained on public data and fully fine-tuned with differential privacy on private data, can train a downstream classifier, while achieving a good privacy-utility tradeoff. However, fully fine-tuning such large diffusion models with DP-SGD can be very resource-demanding in terms of memory usage and computation. In this work, we investigate Parameter-Efficient Fine-Tuning (PEFT) of diffusion models using Low-Dimensional Adaptation (LoDA) with Differential Privacy. We evaluate the proposed method with the MNIST and CIFAR-10 datasets and demonstrate that such efficient fine-tuning can also generate useful synthetic samples for training downstream classifiers, with guaranteed privacy protection of fine-tuning data. Our source code will be made available on GitHub.
6/11/2024