BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
2405.04272
0
0
🤷
Abstract
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
Create account to get full access
Overview
- This paper presents an unsupervised method for jointly performing blind dereverberation and room impulse response estimation, using posterior sampling with diffusion models.
- The reverberation process is modeled using a frequency-dependent exponential decay filter, and the parameters are iteratively estimated as the speech is refined during the reverse diffusion process.
- The method enforces measurement consistency while leveraging a strong prior for clean speech generation, without requiring any knowledge of the room impulse response or paired reverberant-anechoic data.
- The proposed approach outperforms previous blind unsupervised baselines and demonstrates improved robustness to unseen acoustic conditions compared to blind supervised methods.
Plain English Explanation
The paper describes a new method for removing the effects of reverberation from a single-channel audio recording, without needing any information about the specific room or recording setup. Reverberation occurs when sound waves bounce off surfaces in a room, creating a 'echoing' effect that can degrade speech quality.
The key idea is to use a diffusion model, a type of machine learning model that can generate realistic-sounding audio, to iteratively 'undo' the reverberation. The model learns to estimate the specific acoustic properties of the room (the 'room impulse response') as it refines the audio. This is done without any labeled training data showing examples of reverberant and 'clean' speech.
The method works by enforcing two important constraints: first, the generated audio must be consistent with the original reverberant recording; and second, it should follow a strong statistical 'prior' for what clean speech sounds like, as learned by the diffusion model. By iterating between these two principles, the algorithm is able to successfully remove reverberation even in challenging acoustic environments, outperforming previous blind, unsupervised approaches.
Technical Explanation
The paper proposes an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, using posterior sampling with diffusion models.
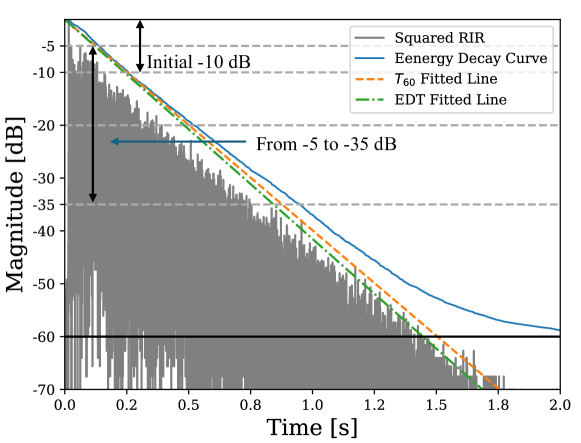
The reverberation operator is parameterized using a frequency-dependent exponential decay filter, and the corresponding parameters are iteratively estimated as the speech utterance is refined along the reverse diffusion trajectory. This allows the method to adapt to different acoustic environments without requiring prior knowledge of the room impulse response.
A measurement consistency criterion is used to ensure that the generated speech remains faithful to the original reverberant recording. Meanwhile, an unconditional diffusion model provides a strong prior for clean speech generation, leveraging its ability to capture the statistical structure of natural speech.
Through this iterative process of posterior sampling, the proposed approach is able to perform effective blind dereverberation without any paired reverberant-anechoic training data. Experimental results show that it significantly outperforms previous blind unsupervised baselines, and demonstrates increased robustness to unseen acoustic conditions compared to blind supervised methods.
The authors also provide audio samples and code online to facilitate further research in this area.
Critical Analysis
The paper presents a novel and promising approach for tackling the challenging problem of blind dereverberation. By combining diffusion models with iterative parameter estimation, the method is able to effectively remove reverberation effects without requiring any prior information about the acoustic environment.
One potential limitation is that the use of a frequency-dependent exponential decay filter may not capture the full complexity of real-world room impulse responses, which can exhibit more intricate temporal and spectral patterns. Exploring more expressive models for the reverberation operator could be an area for future research.
Additionally, while the paper demonstrates improved performance over previous blind unsupervised methods, the comparison to blind supervised techniques is limited to a single dataset. Further evaluation on a wider range of scenarios, including more diverse acoustic conditions and speaker characteristics, would help better assess the method's robustness and generalization capabilities.
It would also be interesting to see how the proposed approach compares to other recent advances in blind dereverberation, such as the BERP method or the fully reversible shoebox model. Combining the strengths of different techniques could potentially lead to even more powerful blind dereverberation systems.
Overall, the paper presents an innovative and promising direction for tackling the challenging problem of blind dereverberation, with potential applications in various speech-based technologies. The authors' willingness to share audio samples and code is also commendable and will hopefully inspire further research in this area.
Conclusion
This paper introduces an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, using posterior sampling with diffusion models. The approach is able to effectively remove reverberation effects without requiring any prior knowledge of the acoustic environment or paired reverberant-anechoic training data.
By iteratively estimating the parameters of a frequency-dependent exponential decay filter and leveraging the strong prior of a diffusion model for clean speech generation, the proposed method outperforms previous blind unsupervised baselines and demonstrates increased robustness to unseen acoustic conditions compared to blind supervised techniques.
The paper's innovative approach and the authors' commitment to open science, through the release of audio samples and code, make it a valuable contribution to the field of speech enhancement and dereverberation. While the method has some limitations, it opens up promising avenues for further research and development in this important area of audio processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Exploring the Potential of Data-Driven Spatial Audio Enhancement Using a Single-Channel Model
Arthur N. dos Santos, Bruno S. Masiero, T'ulio C. L. Mateus
0
0
One key aspect differentiating data-driven single- and multi-channel speech enhancement and dereverberation methods is that both the problem formulation and complexity of the solutions are considerably more challenging in the latter case. Additionally, with limited computational resources, it is cumbersome to train models that require the management of larger datasets or those with more complex designs. In this scenario, an unverified hypothesis that single-channel methods can be adapted to multi-channel scenarios simply by processing each channel independently holds significant implications, boosting compatibility between sound scene capture and system input-output formats, while also allowing modern research to focus on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning. This study verifies this hypothesis by comparing the enhancement promoted by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored to separate clean speech from noisy 3D mixes. A direction of arrival estimation model was used to objectively evaluate its capacity to preserve spatial information by comparing the output signals with ground-truth coordinate values. Consequently, a trade-off arises between preserving spatial information with a more straightforward single-channel solution at the cost of obtaining lower gains in intelligibility scores.
4/24/2024
BERP: A Blind Estimator of Room Acoustic and Physical Parameters for Single-Channel Noisy Speech Signals
Lijun Wang, Yixian Lu, Ziyan Gao, Kai Li, Jianqiang Huang, Yuntao Kong, Shogo Okada
0
0
Room acoustic parameters (RAPs) and room physical parameters ( RPPs) are essential metrics for parameterizing the room acoustical characteristics (RAC) of a sound field around a listener's local environment, offering comprehensive indications for various applications. The current RAPs and RPPs estimation methods either fall short of covering broad real-world acoustic environments in the context of real background noise or lack universal frameworks for blindly estimating RAPs and RPPs from noisy single-channel speech signals, particularly sound source distances, direction-of-arrival (DOA) of sound sources, and occupancy levels. On the other hand, in this paper, we propose a novel universal blind estimation framework called the blind estimator of room acoustical and physical parameters (BERP), by introducing a new stochastic room impulse response (RIR) model, namely, the sparse stochastic impulse response (SSIR) model, and endowing the BERP with a unified encoder and multiple separate predictors to estimate RPPs and SSIR parameters in parallel. This estimation framework enables the computationally efficient and universal estimation of room parameters by solely using noisy single-channel speech signals. Finally, all the RAPs can be simultaneously derived from the RIRs synthesized from SSIR model with the estimated parameters. To evaluate the effectiveness of the proposed BERP and SSIR models, we compile a task-specific dataset from several publicly available datasets. The results reveal that the BERP achieves state-of-the-art (SOTA) performance. Moreover, the evaluation results pertaining to the SSIR RIR model also demonstrated its efficacy. The code is available on GitHub.
5/17/2024

Listening to the Noise: Blind Denoising with Gibbs Diffusion
David Heurtel-Depeiges, Charles C. Margossian, Ruben Ohana, Bruno R'egaldo-Saint Blancard
0
0
In recent years, denoising problems have become intertwined with the development of deep generative models. In particular, diffusion models are trained like denoisers, and the distribution they model coincide with denoising priors in the Bayesian picture. However, denoising through diffusion-based posterior sampling requires the noise level and covariance to be known, preventing blind denoising. We overcome this limitation by introducing Gibbs Diffusion (GDiff), a general methodology addressing posterior sampling of both the signal and the noise parameters. Assuming arbitrary parametric Gaussian noise, we develop a Gibbs algorithm that alternates sampling steps from a conditional diffusion model trained to map the signal prior to the family of noise distributions, and a Monte Carlo sampler to infer the noise parameters. Our theoretical analysis highlights potential pitfalls, guides diagnostic usage, and quantifies errors in the Gibbs stationary distribution caused by the diffusion model. We showcase our method for 1) blind denoising of natural images involving colored noises with unknown amplitude and spectral index, and 2) a cosmology problem, namely the analysis of cosmic microwave background data, where Bayesian inference of noise parameters means constraining models of the evolution of the Universe.
6/27/2024

Unsupervised Improved MVDR Beamforming for Sound Enhancement
Jacob Kealey, John Hershey, Franc{c}ois Grondin
0
0
Neural networks have recently become the dominant approach to sound separation. Their good performance relies on large datasets of isolated recordings. For speech and music, isolated single channel data are readily available; however the same does not hold in the multi-channel case, and with most other sound classes. Multi-channel methods have the potential to outperform single channel approaches as they can exploit both spatial and spectral features, but the lack of training data remains a challenge. We propose unsupervised improved minimum variation distortionless response (UIMVDR), which enables multi-channel separation to leverage in-the-wild single-channel data through unsupervised training and beamforming. Results show that UIMVDR generalizes well and improves separation performance compared to supervised models, particularly in cases with limited supervised data. By using data available online, it also reduces the effort required to gather data for multi-channel approaches.
6/13/2024