Unsupervised Improved MVDR Beamforming for Sound Enhancement
2406.06310
0
0

Abstract
Neural networks have recently become the dominant approach to sound separation. Their good performance relies on large datasets of isolated recordings. For speech and music, isolated single channel data are readily available; however the same does not hold in the multi-channel case, and with most other sound classes. Multi-channel methods have the potential to outperform single channel approaches as they can exploit both spatial and spectral features, but the lack of training data remains a challenge. We propose unsupervised improved minimum variation distortionless response (UIMVDR), which enables multi-channel separation to leverage in-the-wild single-channel data through unsupervised training and beamforming. Results show that UIMVDR generalizes well and improves separation performance compared to supervised models, particularly in cases with limited supervised data. By using data available online, it also reduces the effort required to gather data for multi-channel approaches.
Create account to get full access
Overview
- This paper proposes an unsupervised method for improving the Minimum Variance Distortionless Response (MVDR) beamforming technique to enhance sound quality.
- MVDR beamforming is a common approach for speech enhancement, but it can introduce distortions. The authors aim to address this issue in an unsupervised manner.
- The proposed method leverages the spectral and spatial properties of the target speech and noise signals to adaptively adjust the MVDR beamformer, leading to improved speech quality.
Plain English Explanation
The paper describes a way to improve the quality of enhanced speech using a common audio processing technique called MVDR beamforming. MVDR beamforming is used to isolate a target speech signal from background noise, but it can sometimes introduce unwanted distortions to the speech.
The researchers developed an unsupervised method to adaptively adjust the MVDR beamformer based on the characteristics of the speech and noise signals. This allows the beamformer to be optimized in a way that reduces distortions and enhances the overall sound quality, without requiring any labeled training data.
The key idea is to analyze the spectral (frequency-based) and spatial (location-based) properties of the speech and noise to guide the beamformer's parameters. This enables the system to automatically adapt to different acoustic environments and noise conditions, leading to better speech enhancement performance.
Technical Explanation
The paper presents an unsupervised improved MVDR beamforming method for enhancing speech quality. MVDR beamforming is a widely used technique for speech enhancement, but it can introduce speech distortions due to imperfect noise covariance estimation.
The proposed method addresses this issue in an unsupervised manner by adaptively adjusting the MVDR beamformer based on the spectral and spatial properties of the target speech and noise signals. Specifically, the authors:
- Estimate the speech and noise spatial covariance matrices using an unsupervised source separation approach.
- Derive an optimal MVDR beamformer by jointly considering the speech and noise spatial properties.
- Adaptively update the MVDR beamformer parameters to minimize speech distortions.
This approach allows the system to automatically adapt to different acoustic environments and noise conditions, leading to improved speech enhancement performance compared to standard MVDR beamforming.
The authors evaluate their method on both simulated and real-world noisy speech datasets, demonstrating significant improvements in objective speech quality measures compared to baseline methods.
Critical Analysis
The paper presents a promising unsupervised approach for improving MVDR beamforming, which is an important tool for speech enhancement. The authors have identified a key limitation of standard MVDR beamforming, namely the introduction of speech distortions, and have proposed an effective solution to address this issue.
One potential limitation of the work is that it assumes the availability of a microphone array to capture the spatial information needed for the adaptive beamforming. In some scenarios, only a single-channel input may be available, which would require different dereverberation techniques.
Additionally, the paper does not consider the case of multiple, concurrent speech sources, which would require more advanced source separation capabilities. Further research could explore extensions of the proposed method to handle such challenging scenarios.
Overall, the paper presents a valuable contribution to the field of speech enhancement, demonstrating the potential of unsupervised, data-driven techniques to improve upon established algorithms like MVDR beamforming. The proposed approach for enhancing speech auto-disentanglement is a promising direction for further research and development.
Conclusion
This paper introduces an unsupervised method for improving the performance of MVDR beamforming, a widely used speech enhancement technique. By adaptively adjusting the beamformer's parameters based on the spectral and spatial properties of the target speech and noise, the proposed approach can effectively reduce speech distortions and improve overall sound quality.
The key innovation is the unsupervised nature of the method, which allows it to automatically adapt to different acoustic environments without requiring any labeled training data. This makes the technique widely applicable and practical for real-world speech enhancement applications.
The results demonstrate the potential of data-driven, unsupervised techniques to enhance established algorithms like MVDR beamforming. Further research could explore extensions to handle more complex scenarios, such as multiple concurrent speech sources or single-channel input. Overall, this work represents an important step forward in improving the quality of enhanced speech signals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Exploring the Potential of Data-Driven Spatial Audio Enhancement Using a Single-Channel Model
Arthur N. dos Santos, Bruno S. Masiero, T'ulio C. L. Mateus
0
0
One key aspect differentiating data-driven single- and multi-channel speech enhancement and dereverberation methods is that both the problem formulation and complexity of the solutions are considerably more challenging in the latter case. Additionally, with limited computational resources, it is cumbersome to train models that require the management of larger datasets or those with more complex designs. In this scenario, an unverified hypothesis that single-channel methods can be adapted to multi-channel scenarios simply by processing each channel independently holds significant implications, boosting compatibility between sound scene capture and system input-output formats, while also allowing modern research to focus on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning. This study verifies this hypothesis by comparing the enhancement promoted by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored to separate clean speech from noisy 3D mixes. A direction of arrival estimation model was used to objectively evaluate its capacity to preserve spatial information by comparing the output signals with ground-truth coordinate values. Consequently, a trade-off arises between preserving spatial information with a more straightforward single-channel solution at the cost of obtaining lower gains in intelligibility scores.
4/24/2024

Neural Blind Source Separation and Diarization for Distant Speech Recognition
Yoshiaki Bando, Tomohiko Nakamura, Shinji Watanabe
0
0
This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, the trained model can jointly separate and diarize speech mixtures without any auxiliary information. The experiments with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates. The code is available online.
6/13/2024
🤷
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
Eloi Moliner, Jean-Marie Lemercier, Simon Welker, Timo Gerkmann, Vesa Valimaki
0
0
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
5/8/2024
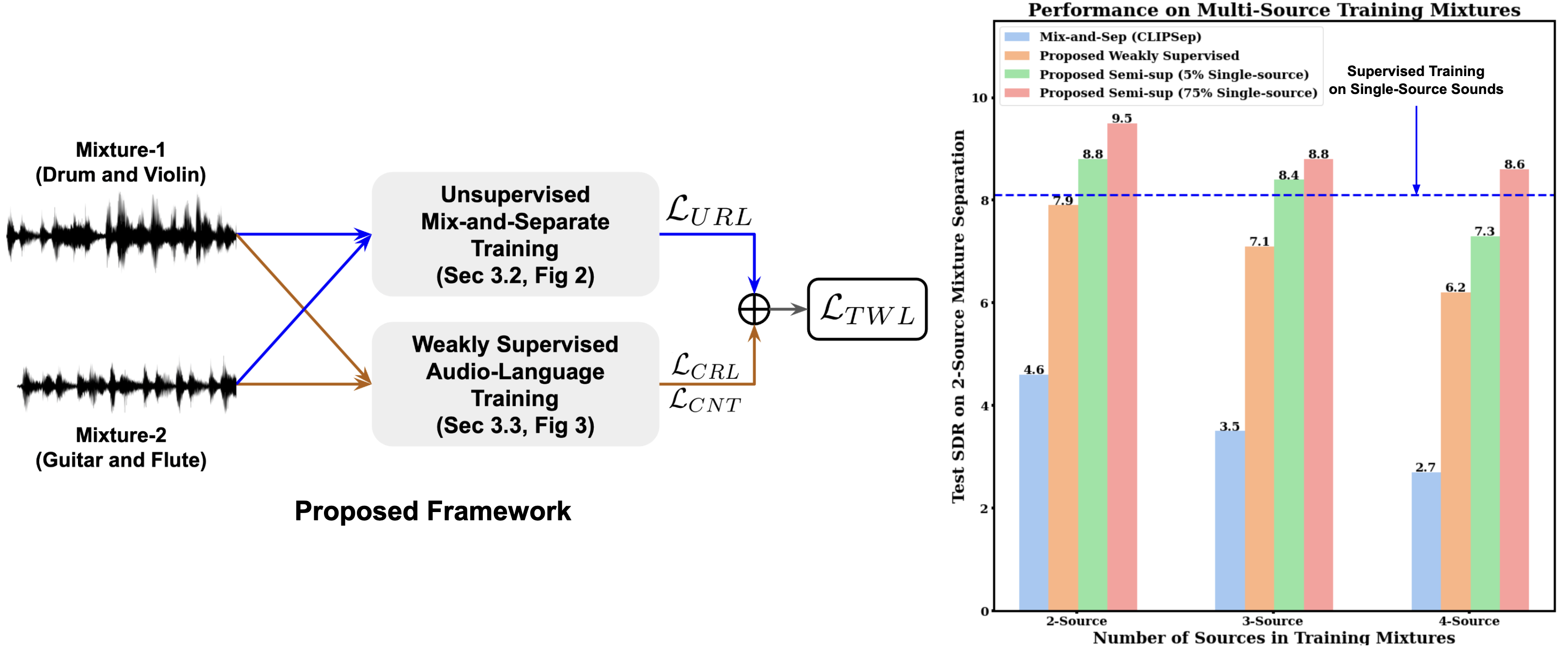
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
0
0
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
4/3/2024