Exploring the Potential of Data-Driven Spatial Audio Enhancement Using a Single-Channel Model
2404.14564
0
0
📈
Abstract
One key aspect differentiating data-driven single- and multi-channel speech enhancement and dereverberation methods is that both the problem formulation and complexity of the solutions are considerably more challenging in the latter case. Additionally, with limited computational resources, it is cumbersome to train models that require the management of larger datasets or those with more complex designs. In this scenario, an unverified hypothesis that single-channel methods can be adapted to multi-channel scenarios simply by processing each channel independently holds significant implications, boosting compatibility between sound scene capture and system input-output formats, while also allowing modern research to focus on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning. This study verifies this hypothesis by comparing the enhancement promoted by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored to separate clean speech from noisy 3D mixes. A direction of arrival estimation model was used to objectively evaluate its capacity to preserve spatial information by comparing the output signals with ground-truth coordinate values. Consequently, a trade-off arises between preserving spatial information with a more straightforward single-channel solution at the cost of obtaining lower gains in intelligibility scores.
Create account to get full access
Overview
- This paper explores the differences between single-channel and multi-channel speech enhancement and dereverberation methods.
- It investigates the hypothesis that single-channel methods can be adapted to multi-channel scenarios by processing each channel independently.
- The study compares the performance of a basic single-channel speech enhancement model with two multi-channel models designed for separating clean speech from noisy 3D mixes.
Plain English Explanation
Speech enhancement and dereverberation are important tasks in audio processing, where the goal is to improve the quality and intelligibility of speech signals. Single-channel methods are generally simpler to implement and train, while multi-channel methods can leverage spatial information from multiple microphones to achieve better performance. However, multi-channel methods are more complex and require larger datasets.
The researchers in this study tested the idea that single-channel methods could be adapted to multi-channel scenarios by processing each channel independently. This could be a useful approach if it maintains spatial information while simplifying the problem. The researchers compared the performance of a basic single-channel model with two multi-channel models designed for separating clean speech from noisy 3D audio mixes.
Technical Explanation
The paper compares the enhancement achieved by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored for separating clean speech from noisy 3D audio mixes. The single-channel model processes each channel independently, while the multi-channel models leverage spatial information from the multiple microphones.
To evaluate the models, the researchers used a direction of arrival estimation model to objectively assess the capacity of the single-channel approach to preserve spatial information. They compared the output signals to ground-truth coordinate values.
The results reveal a trade-off between preserving spatial information with the simpler single-channel solution and achieving higher gains in intelligibility scores. The single-channel approach was able to maintain spatial information, but at the cost of lower performance improvements compared to the multi-channel models.
Critical Analysis
The paper acknowledges that the single-channel approach may not achieve the same level of intelligibility enhancement as the more complex multi-channel models. However, it highlights the potential benefits of the single-channel approach, such as compatibility with existing sound scene capture and system input-output formats and the ability to focus research efforts on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning.
One potential limitation not addressed in the paper is the impact of the specific audio environments and noise conditions on the performance of the single-channel approach. Further research may be needed to understand the limitations and applicability of this approach in diverse real-world scenarios.
Conclusion
This study provides empirical evidence that a single-channel speech enhancement and dereverberation model can be adapted to multi-channel scenarios by processing each channel independently. While this approach may not achieve the same level of intelligibility enhancement as dedicated multi-channel models, it offers benefits in terms of simplicity, compatibility, and the ability to focus research efforts on other challenging aspects of speech enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
Eloi Moliner, Jean-Marie Lemercier, Simon Welker, Timo Gerkmann, Vesa Valimaki
0
0
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
5/8/2024

Unsupervised Improved MVDR Beamforming for Sound Enhancement
Jacob Kealey, John Hershey, Franc{c}ois Grondin
0
0
Neural networks have recently become the dominant approach to sound separation. Their good performance relies on large datasets of isolated recordings. For speech and music, isolated single channel data are readily available; however the same does not hold in the multi-channel case, and with most other sound classes. Multi-channel methods have the potential to outperform single channel approaches as they can exploit both spatial and spectral features, but the lack of training data remains a challenge. We propose unsupervised improved minimum variation distortionless response (UIMVDR), which enables multi-channel separation to leverage in-the-wild single-channel data through unsupervised training and beamforming. Results show that UIMVDR generalizes well and improves separation performance compared to supervised models, particularly in cases with limited supervised data. By using data available online, it also reduces the effort required to gather data for multi-channel approaches.
6/13/2024
🤿
Real-time multichannel deep speech enhancement in hearing aids: Comparing monaural and binaural processing in complex acoustic scenarios
Nils L. Westhausen, Hendrik Kayser, Theresa Jansen, Bernd T. Meyer
0
0
Deep learning has the potential to enhance speech signals and increase their intelligibility for users of hearing aids. Deep models suited for real-world application should feature a low computational complexity and low processing delay of only a few milliseconds. In this paper, we explore deep speech enhancement that matches these requirements and contrast monaural and binaural processing algorithms in two complex acoustic scenes. Both algorithms are evaluated with objective metrics and in experiments with hearing-impaired listeners performing a speech-in-noise test. Results are compared to two traditional enhancement strategies, i.e., adaptive differential microphone processing and binaural beamforming. While in diffuse noise, all algorithms perform similarly, the binaural deep learning approach performs best in the presence of spatial interferers. Through a post-analysis, this can be attributed to improvements at low SNRs and to precise spatial filtering.
5/6/2024
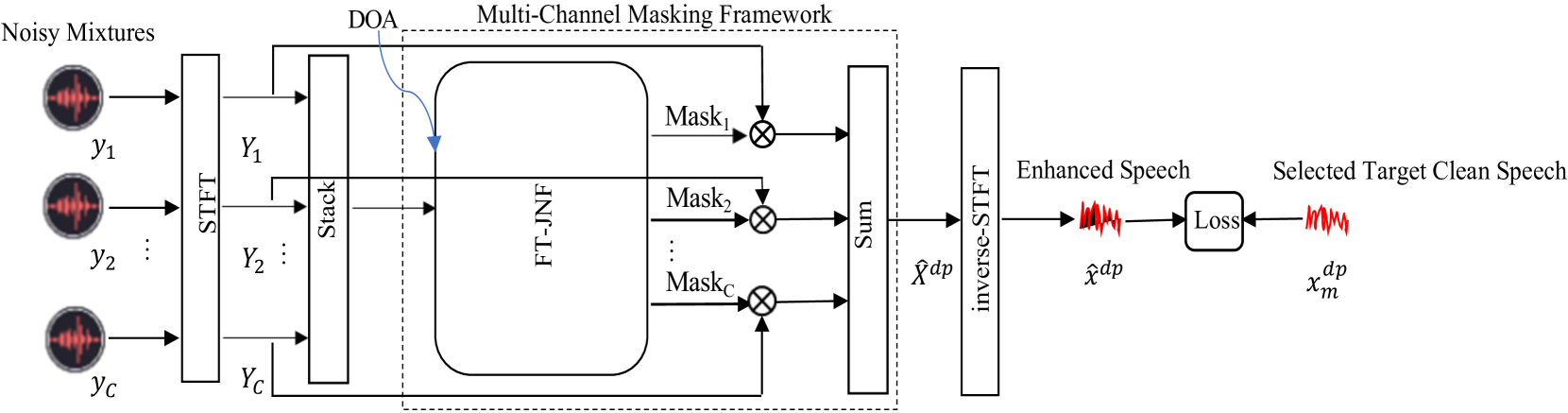
Reference Channel Selection by Multi-Channel Masking for End-to-End Multi-Channel Speech Enhancement
Wang Dai, Xiaofei Li, Archontis Politis, Tuomas Virtanen
0
0
In end-to-end multi-channel speech enhancement, the traditional approach of designating one microphone signal as the reference for processing may not always yield optimal results. The limitation is particularly in scenarios with large distributed microphone arrays with varying speaker-to-microphone distances or compact, highly directional microphone arrays where speaker or microphone positions change over time. Current mask-based methods often fix the reference channel during training, which makes it not possible to adaptively select the reference channel for optimal performance. To address this problem, we introduce an adaptive approach for selecting the optimal reference channel. Our method leverages a multi-channel masking-based scheme, where multiple masked signals are combined to generate a single-channel output signal. This enhanced signal is then used for loss calculation, while the reference clean speech is adjusted based on the highest scale-invariant signal-to-distortion ratio (SI-SDR). The experimental results on the Spear challenge simulated dataset D4 demonstrate the superiority of our proposed method over the conventional approach of using a fixed reference channel with single-channel masking.
6/12/2024