Building Better Datasets: Seven Recommendations for Responsible Design from Dataset Creators

0

Sign in to get full access
Overview
- Building better datasets requires careful consideration of responsible design principles
- Seven key recommendations from dataset creators for improving dataset development
- Focuses on addressing challenges around fairness, privacy, and ethics in dataset creation
Plain English Explanation
Datasets are the foundation for many machine learning and artificial intelligence systems. However, the process of building datasets can introduce biases, privacy concerns, and other ethical issues if not done responsibly. This paper provides recommendations from dataset creators on how to design better datasets that are more fair, ethical, and privacy-preserving.
The authors highlight the importance of actively considering the social context and implications of dataset design, rather than treating it as a purely technical exercise. They offer seven key recommendations, including carefully evaluating dataset sources, engaging with diverse stakeholders, and being transparent about dataset limitations and potential harms.
By following these principles, dataset creators can help ensure their work supports beneficial AI applications while mitigating risks around unfairness and unintended consequences.
Technical Explanation
The paper presents seven key recommendations for responsible dataset design:
-
Carefully Evaluate Data Sources: Scrutinize the provenance, context, and potential biases of data used to construct datasets.
-
Engage with Diverse Stakeholders: Collaborate with a wide range of stakeholders, including impacted communities, to understand different perspectives and needs.
-
Document Dataset Limitations: Provide clear, comprehensive documentation about dataset scope, intended uses, and potential risks or harms.
-
Prioritize Privacy and Consent: Ensure dataset collection and use respects individual privacy rights and obtains appropriate consent.
-
Address Representation and Inclusion: Strive for diverse dataset composition that reflects the full breadth of the target population.
-
Employ Iterative and Reflexive Processes: Continuously re-evaluate datasets as they are used, and make updates to address emerging issues.
-
Cultivate Dataset Creators' Expertise: Build the capacity of dataset creators through training, mentorship, and access to best practices.
The authors emphasize that responsible dataset design requires considering the social context and impacts, not just technical factors. They provide examples and case studies to illustrate how these principles can be applied in practice.
Critical Analysis
The recommendations presented in this paper provide a valuable framework for dataset creators seeking to develop responsible, ethical, and inclusive datasets. The authors rightly highlight the need to move beyond narrow technical approaches and deeply engage with diverse stakeholders and social implications.
One potential limitation is the generalizability of the recommendations, as dataset creation often occurs within specific organizational or domain contexts with unique challenges. Further research may be needed to understand how these principles can be effectively scaled and adapted.
Additionally, the paper does not delve into the complex trade-offs and tensions that can arise when trying to balance different ethical priorities, such as privacy, fairness, and representation. Dataset creators may need more guidance on navigating these nuanced ethical dilemmas.
Overall, this paper makes an important contribution by elevating the voice of dataset creators and providing a solid foundation for responsible dataset design. As AI systems become increasingly pervasive, ensuring the ethical development of foundational datasets will be crucial for building trustworthy and beneficial technologies.
Conclusion
This paper offers a comprehensive set of recommendations from dataset creators on how to design more responsible and ethical datasets. By carefully considering data sources, engaging stakeholders, documenting limitations, and prioritizing privacy and inclusion, dataset creators can help mitigate the risks of unfairness, bias, and unintended consequences in AI applications.
Implementing these principles will require a shift in mindset, moving beyond purely technical approaches to dataset development and deeply engaging with the social context and implications. While further research may be needed to address specific challenges, this paper provides a valuable starting point for dataset creators, researchers, and policymakers committed to building better, more responsible datasets that support the responsible development of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Building Better Datasets: Seven Recommendations for Responsible Design from Dataset Creators
Will Orr, Kate Crawford
The increasing demand for high-quality datasets in machine learning has raised concerns about the ethical and responsible creation of these datasets. Dataset creators play a crucial role in developing responsible practices, yet their perspectives and expertise have not yet been highlighted in the current literature. In this paper, we bridge this gap by presenting insights from a qualitative study that included interviewing 18 leading dataset creators about the current state of the field. We shed light on the challenges and considerations faced by dataset creators, and our findings underscore the potential for deeper collaboration, knowledge sharing, and collective development. Through a close analysis of their perspectives, we share seven central recommendations for improving responsible dataset creation, including issues such as data quality, documentation, privacy and consent, and how to mitigate potential harms from unintended use cases. By fostering critical reflection and sharing the experiences of dataset creators, we aim to promote responsible dataset creation practices and develop a nuanced understanding of this crucial but often undervalued aspect of machine learning research.
Read more9/4/2024
✨
0
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Surbhi Mittal, Kartik Thakral, Richa Singh, Mayank Vatsa, Tamar Glaser, Cristian Canton Ferrer, Tal Hassner
Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
Read more8/20/2024

0
AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Read more4/16/2024
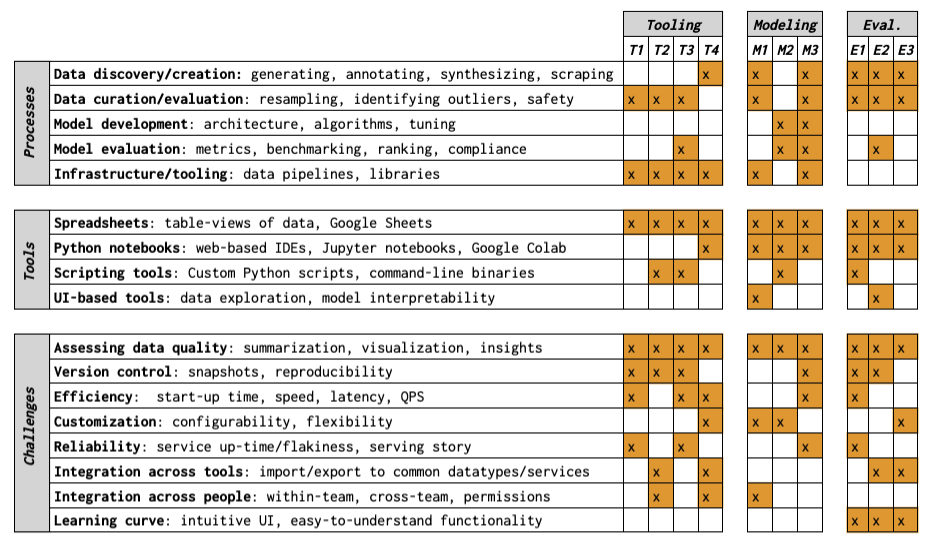
0
Understanding the Dataset Practitioners Behind Large Language Model Development
Crystal Qian, Emily Reif, Minsuk Kahng
As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of dataset practitioners by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at a technology company, Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that although data quality is a top priority, there is little consensus around what data quality is and how to evaluate it. Consequently, practitioners either rely on their own intuition or write custom code to evaluate their data. We discuss potential reasons for this phenomenon and opportunities for alignment.
Read more4/3/2024