Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers

0

Sign in to get full access
Overview
- The paper introduces a method for effectively training large language models (LLMs) using structured feedforward layers.
- The key idea is to replace the dense feedforward layers in transformer models with more structured and efficient alternatives, such as low-rank or sparse layers.
- This approach can lead to significant improvements in training efficiency and performance, while maintaining the expressive power of the original model.
Plain English Explanation
The research paper discusses a way to make the training of large language models more efficient and effective. Large language models, such as those used in chatbots and language generation, are often very complex and computationally intensive to train.
The main insight of the paper is that the dense, fully-connected feedforward layers in these models can be replaced with more structured and efficient alternatives, such as low-rank or sparse layers. Low-rank layers use a smaller number of parameters to achieve similar expressiveness, while sparse layers can selectively activate only a subset of the neurons, reducing computational requirements.
By using these structured feedforward layers, the researchers were able to train large language models more efficiently, without sacrificing their performance or capabilities. This could lead to significant cost savings and faster development of advanced language AI systems.
Technical Explanation
The paper proposes a method for effectively training large language models (LLMs) by replacing the dense feedforward layers in transformer models with more structured and efficient alternatives. Specifically, the authors explore the use of low-rank and sparse feedforward layers.
Low-rank feedforward layers use a decomposition of the weight matrix into two smaller matrices, reducing the number of parameters and computation required. Sparse feedforward layers selectively activate only a subset of the neurons, further reducing the computational burden.
The authors conduct experiments to evaluate the performance of these structured feedforward layers on various language modeling tasks. They find that the structured layers can achieve similar or even better performance compared to the original dense layers, while significantly reducing the training time and computational resources required.
Critical Analysis
The paper presents a promising approach for improving the efficiency of training large language models, but there are a few potential limitations and areas for further research:
-
The experiments are conducted on relatively small-scale language modeling tasks, and it's unclear how well the structured feedforward layers would scale to truly massive LLMs used in production. Further research on larger models would be valuable.
-
The paper does not explore the interplay between the structured feedforward layers and other architectural choices, such as the attention mechanism or the number of transformer layers. Investigating these interactions could lead to further improvements.
-
The paper focuses on training efficiency, but it would be important to also examine the performance and capabilities of the resulting models in real-world applications, such as open-ended language generation or question-answering.
Overall, the research provides a solid foundation for improving the training of large language models and suggests that structured feedforward layers are a promising direction for further exploration and development.
Conclusion
The paper presents a novel approach for effectively training large language models by replacing the dense feedforward layers with more structured and efficient alternatives, such as low-rank and sparse layers. This method can lead to significant improvements in training efficiency and performance, while maintaining the expressive power of the original model.
The findings of this research have the potential to drive significant advancements in the development of large language models, leading to more cost-effective and faster-to-train AI systems that can be deployed in a wide range of applications, from chatbots to content generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers
Xiuying Wei, Skander Moalla, Razvan Pascanu, Caglar Gulcehre
State-of-the-art results in large language models (LLMs) often rely on scale, which becomes computationally expensive. This has sparked a research agenda to reduce these models' parameter count and computational costs without significantly impacting their performance. Our study focuses on transformer-based LLMs, specifically targeting the computationally intensive feedforward networks (FFN), which are less studied than attention blocks. We consider three candidate linear layer approximations in the FFN by combining efficient low-rank and block-diagonal matrices. In contrast to many previous works that examined these approximations, our study i) explores these structures from the training-from-scratch perspective, ii) scales up to 1.3B parameters, and iii) is conducted within recent Transformer-based LLMs rather than convolutional architectures. We first demonstrate they can lead to actual computational gains in various scenarios, including online decoding when using a pre-merge technique. Additionally, we propose a novel training regime, called textit{self-guided training}, aimed at improving the poor training dynamics that these approximations exhibit when used from initialization. Experiments on the large RefinedWeb dataset show that our methods are both efficient and effective for training and inference. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Further applying self-guided training to the structured matrices with 32% FFN parameters and 2.5$times$ speed-up enables only a 0.4 perplexity increase under the same training FLOPs. Finally, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at url{https://github.com/CLAIRE-Labo/StructuredFFN/tree/main}.
Read more6/26/2024

0
Investigating Low-Rank Training in Transformer Language Models: Efficiency and Scaling Analysis
Xiuying Wei, Skander Moalla, Razvan Pascanu, Caglar Gulcehre
State-of-the-art LLMs often rely on scale with high computational costs, which has sparked a research agenda to reduce parameter counts and costs without significantly impacting performance. Our study focuses on Transformer-based LLMs, specifically applying low-rank parametrization to the computationally intensive feedforward networks (FFNs), which are less studied than attention blocks. In contrast to previous works, (i) we explore low-rank parametrization at scale, up to 1.3B parameters; (ii) within Transformer language models rather than convolutional architectures; and (iii) starting from training from scratch. Experiments on the large RefinedWeb dataset show that low-rank parametrization is both efficient (e.g., 2.6$times$ FFN speed-up with 32% parameters) and effective during training. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Motivated by this finding, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at https://github.com/CLAIRE-Labo/StructuredFFN/tree/main.
Read more7/25/2024
0
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
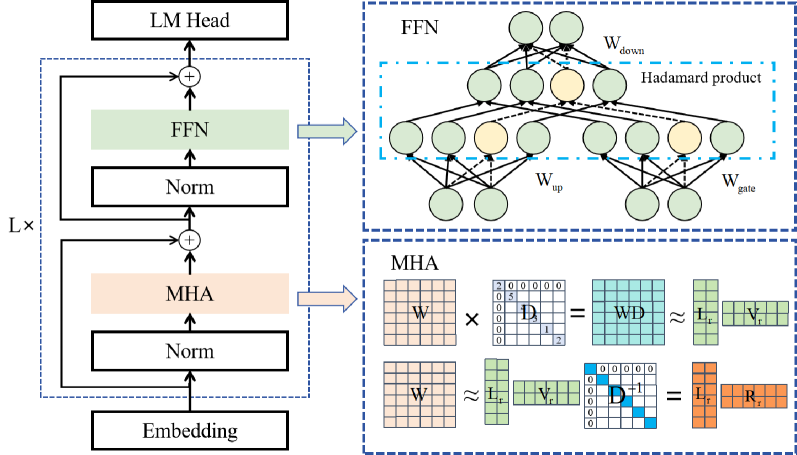
Guangyan Li, Yongqiang Tang, Wensheng Zhang
Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
Read more4/16/2024
0
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
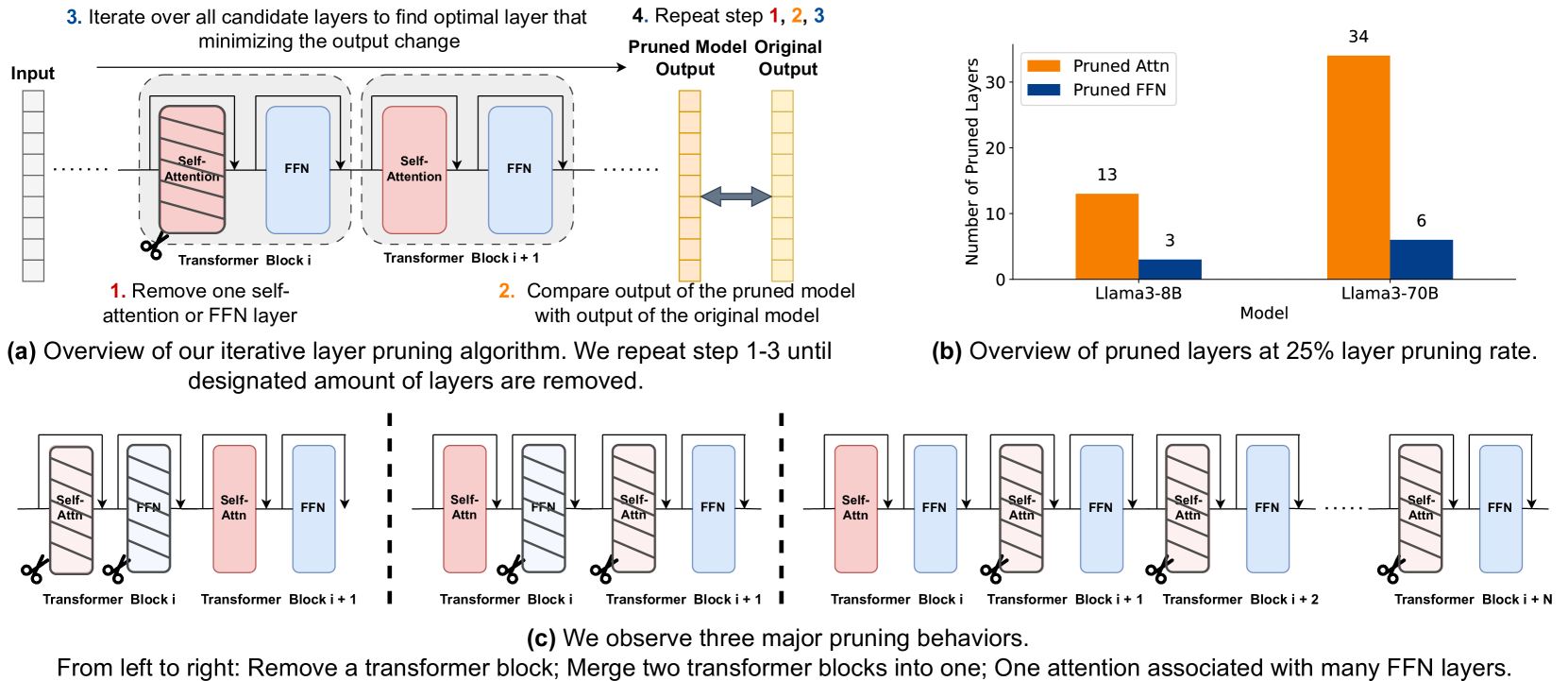
Yang Zhang, Yawei Li, Xinpeng Wang, Qianli Shen, Barbara Plank, Bernd Bischl, Mina Rezaei, Kenji Kawaguchi
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.
Read more5/29/2024