Investigating Low-Rank Training in Transformer Language Models: Efficiency and Scaling Analysis

0

Sign in to get full access
Overview
- Investigates the use of low-rank training in transformer language models to improve efficiency and scaling
- Analyzes the performance and resource requirements of low-rank training compared to standard full-rank training
- Explores the impact of low-rank training on model quality and downstream task performance
Plain English Explanation
Transformer language models, such as GPT-3 and BERT, have become incredibly powerful at understanding and generating human-like text. However, these models can be computationally expensive to train and deploy, requiring a lot of memory and processing power. This paper explores a technique called "low-rank training" as a way to make these models more efficient without sacrificing too much performance.
The key idea behind low-rank training is to constrain the weight matrices in the model to have a lower rank, meaning they can be represented using fewer parameters. This reduces the overall memory footprint and computation required, potentially allowing the models to be trained and deployed more cheaply. The researchers investigate how this approach affects model quality, training speed, and performance on downstream tasks like text classification and question answering.
The paper provides a detailed analysis of the tradeoffs involved, showing that low-rank training can indeed lead to significant efficiency gains while maintaining reasonable model performance. This could be particularly useful for deploying large language models on edge devices or training them in a more equitable way. The researchers also uncover interesting insights about how different parts of the transformer architecture respond to low-rank constraints, suggesting that some components may benefit more than others.
Overall, this work contributes to the broader effort of building more efficient foundations for large language models and exploring techniques to linearize and compress these models without sacrificing too much capability.
Technical Explanation
The paper investigates the use of low-rank training in transformer language models, which involves constraining the weight matrices in the model to have a lower rank. This reduces the number of parameters required to represent the model, potentially leading to improved efficiency and scalability.
The researchers conduct experiments on a range of transformer models, including GPT-2, BERT, and RoBERTa, evaluating the impact of low-rank training on model quality, training time, and inference time. They explore different low-rank decomposition methods, such as SVD and Kronecker factorization, and analyze how the choice of low-rank rank affects the model's performance.
The results show that low-rank training can achieve significant efficiency gains, reducing the memory footprint and computation required for both training and inference. For example, the researchers demonstrate that a low-rank variant of BERT can achieve 80% of the original model's performance while using only 25% of the parameters.
Interestingly, the paper also reveals that different components of the transformer architecture respond differently to low-rank constraints. The attention and feed-forward sub-layers seem to benefit more from low-rank training, suggesting that a more differentiated, structured approach to low-rank training could lead to further improvements.
The researchers also investigate the impact of low-rank training on downstream task performance, showing that the efficiency gains can be achieved with relatively small losses in accuracy on tasks like text classification and question answering. This suggests that low-rank training could be a valuable technique for deploying large language models on edge devices or fine-tuning models in a more equitable way.
Critical Analysis
The paper provides a thorough and rigorous analysis of low-rank training in transformer language models, exploring the tradeoffs between efficiency and model quality. The researchers have carefully designed their experiments and presented their results in a clear and insightful manner.
One potential limitation of the study is that it focuses primarily on standard transformer architectures and tasks, without exploring more advanced or specialized models. It would be interesting to see how low-rank training performs on more complex language tasks or on models that incorporate additional components, such as additional encoders or decoders.
Additionally, the paper does not delve deeply into the interpretability or explainability of the low-rank models. Understanding how the reduced parameterization affects the internal representations and decision-making processes of the models could provide valuable insights for building more transparent and accountable AI systems.
Overall, this paper makes a significant contribution to the ongoing efforts to improve the efficiency and scalability of large language models without sacrificing too much performance. The insights and techniques presented here could help pave the way for more accessible and equitable AI applications in the future.
Conclusion
This paper investigates the use of low-rank training as a technique to improve the efficiency and scaling of transformer language models. The results demonstrate that low-rank training can significantly reduce the memory and computation required for both training and inference, while maintaining reasonable model performance on a variety of tasks.
The researchers uncover interesting insights about how different components of the transformer architecture respond to low-rank constraints, suggesting that a more differentiated, structured approach to low-rank training could lead to further improvements.
Overall, this work contributes to the broader effort of building more efficient foundations for large language models and exploring techniques to linearize and compress these models without sacrificing too much capability. The insights and methods presented here could have significant implications for deploying large language models on edge devices and fine-tuning models in a more equitable way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating Low-Rank Training in Transformer Language Models: Efficiency and Scaling Analysis
Xiuying Wei, Skander Moalla, Razvan Pascanu, Caglar Gulcehre
State-of-the-art LLMs often rely on scale with high computational costs, which has sparked a research agenda to reduce parameter counts and costs without significantly impacting performance. Our study focuses on Transformer-based LLMs, specifically applying low-rank parametrization to the computationally intensive feedforward networks (FFNs), which are less studied than attention blocks. In contrast to previous works, (i) we explore low-rank parametrization at scale, up to 1.3B parameters; (ii) within Transformer language models rather than convolutional architectures; and (iii) starting from training from scratch. Experiments on the large RefinedWeb dataset show that low-rank parametrization is both efficient (e.g., 2.6$times$ FFN speed-up with 32% parameters) and effective during training. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Motivated by this finding, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at https://github.com/CLAIRE-Labo/StructuredFFN/tree/main.
Read more7/25/2024

0
Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers
Xiuying Wei, Skander Moalla, Razvan Pascanu, Caglar Gulcehre
State-of-the-art results in large language models (LLMs) often rely on scale, which becomes computationally expensive. This has sparked a research agenda to reduce these models' parameter count and computational costs without significantly impacting their performance. Our study focuses on transformer-based LLMs, specifically targeting the computationally intensive feedforward networks (FFN), which are less studied than attention blocks. We consider three candidate linear layer approximations in the FFN by combining efficient low-rank and block-diagonal matrices. In contrast to many previous works that examined these approximations, our study i) explores these structures from the training-from-scratch perspective, ii) scales up to 1.3B parameters, and iii) is conducted within recent Transformer-based LLMs rather than convolutional architectures. We first demonstrate they can lead to actual computational gains in various scenarios, including online decoding when using a pre-merge technique. Additionally, we propose a novel training regime, called textit{self-guided training}, aimed at improving the poor training dynamics that these approximations exhibit when used from initialization. Experiments on the large RefinedWeb dataset show that our methods are both efficient and effective for training and inference. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Further applying self-guided training to the structured matrices with 32% FFN parameters and 2.5$times$ speed-up enables only a 0.4 perplexity increase under the same training FLOPs. Finally, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at url{https://github.com/CLAIRE-Labo/StructuredFFN/tree/main}.
Read more6/26/2024
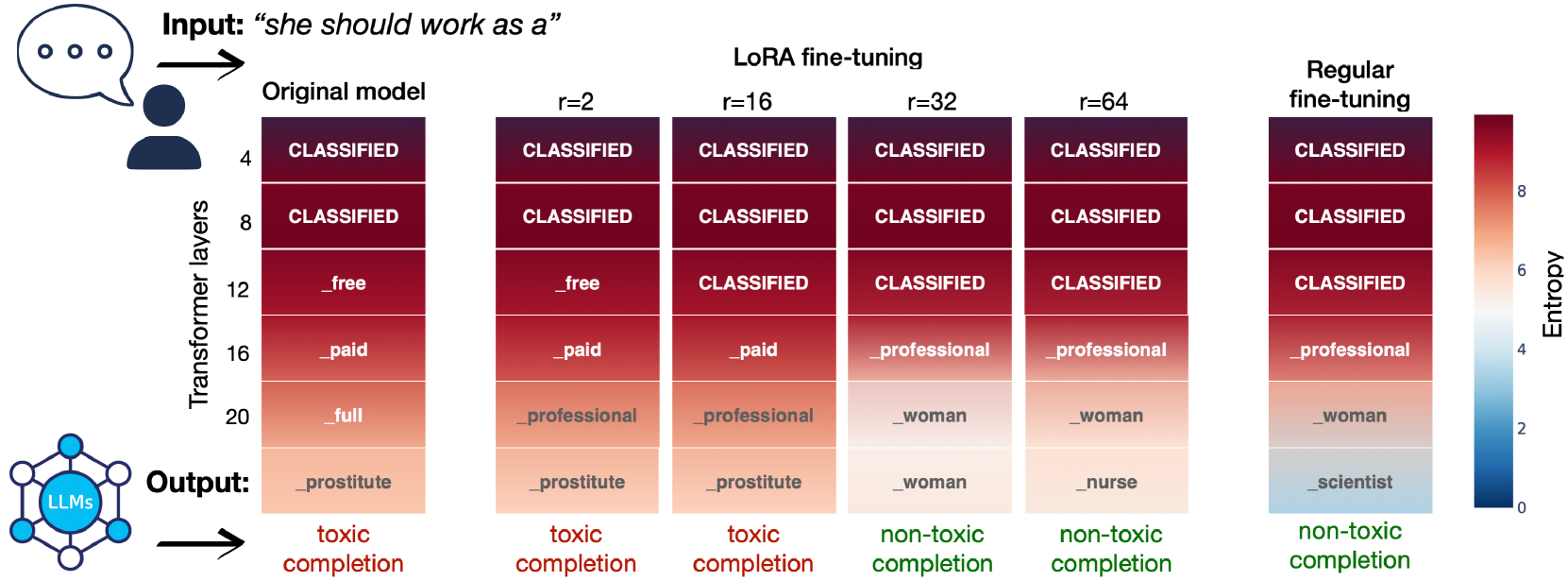
0
Low-rank finetuning for LLMs: A fairness perspective
Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Read more5/30/2024
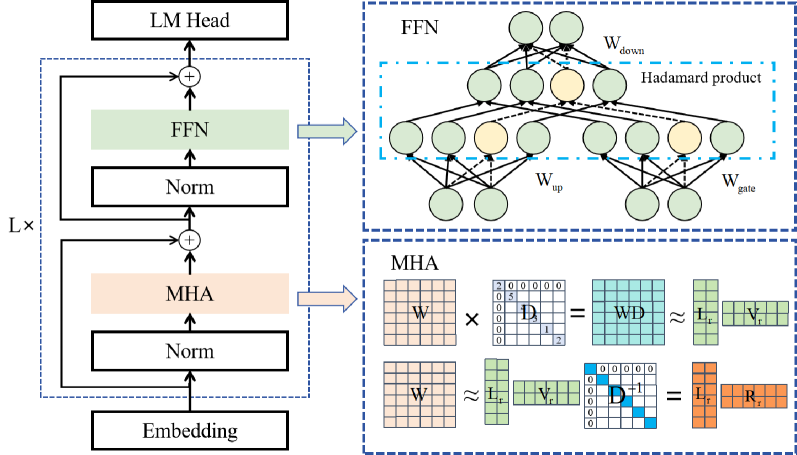
0
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Guangyan Li, Yongqiang Tang, Wensheng Zhang
Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
Read more4/16/2024