C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition

0

Sign in to get full access
Overview
- This research paper, titled "C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition," explores a new approach for recognizing complex actions composed of simpler elements.
- The key idea is to learn how individual action components (e.g., "walking," "holding") can be combined to form more complex actions (e.g., "walking while holding an object") without needing to see examples of the full compositions during training.
- This "zero-shot" compositional action recognition capability could have important applications in areas like robotics, where systems need to understand and execute novel combinations of basic actions.
Plain English Explanation
The researchers in this paper are trying to develop AI systems that can recognize complex actions, even if they haven't seen examples of those exact actions during training. The key insight is that many complex actions are actually just combinations of simpler, more basic actions.
For example, imagine you want to train an AI system to recognize the action of "walking while holding an object." Instead of trying to show the system tons of examples of this specific action, the researchers propose teaching the system about the individual components - "walking" and "holding" - and then letting it figure out how to combine those basic elements to recognize the full, complex action.
This "component-to-composition" approach allows the system to generalize and recognize novel combinations of actions that it hasn't been explicitly trained on. So if it knows about "walking" and "holding," it can understand and identify "walking while holding" even if that specific scenario wasn't part of its training data.
This kind of flexible, compositional understanding of actions could be really useful in areas like robotics, where we want systems to be able to execute and recognize a wide range of complex behaviors, not just the specific ones they were trained on. By breaking things down into simpler building blocks, the researchers hope to enable more versatile and generalizable action recognition capabilities.
Technical Explanation
The key technical contribution of this paper is a new framework called "C2C" (Component-to-Composition) that enables zero-shot compositional action recognition. The core idea is to learn representations of individual action components (e.g., "walking," "holding") and then use these to compose representations of more complex, novel action combinations.
Specifically, the C2C architecture consists of two main modules:
- A component encoder that learns embeddings for basic action components by observing examples of them.
- A composition decoder that takes these component embeddings as input and learns to predict the representations of more complex, compositional actions.
During training, the system is exposed to examples of both individual action components and some compositions of those components. It then learns to map the component embeddings to the correct compositional representations, enabling it to generalize and recognize novel action compositions at test time.
The researchers evaluate their approach on several benchmark datasets for compositional action recognition, demonstrating significant performance improvements over prior methods that do not explicitly model the compositional structure of actions. They also conduct ablation studies to analyze the contributions of the different C2C components.
Critical Analysis
The key strength of this research is its focus on the important problem of compositional action recognition and its novel technical approach to address it. By explicitly modeling the relationship between basic action components and their compositions, the C2C framework represents a valuable step forward compared to prior methods that treated complex actions as monolithic entities.
That said, the paper does not fully explore the limitations and potential issues with this approach. For example, the experiments are conducted on relatively constrained datasets, and it's unclear how well the C2C model would scale to recognizing compositions of a much larger set of action primitives. There are also open questions about the robustness of the approach to variations in the way that component actions are combined or executed.
Additionally, the paper does not discuss potential negative societal impacts or ethical considerations around this technology. As action recognition systems become more sophisticated and capable of understanding complex behaviors, it will be important to carefully consider how these capabilities could be misused or applied in problematic ways.
Overall, while this is a technically solid and promising piece of research, there is still significant room for further development and critical analysis to fully understand the strengths, limitations, and implications of compositional action recognition approaches like C2C.
Conclusion
This paper presents a novel framework called C2C (Component-to-Composition) that enables zero-shot compositional action recognition. By learning representations of individual action components and then modeling how these can be combined, the C2C approach allows AI systems to recognize complex actions, even if they haven't been explicitly trained on those specific compositions.
The key innovation is this ability to generalize beyond the training data, which could have important applications in areas like robotics, where systems need to understand and execute a wide range of behaviors. While the current evaluation demonstrates promising results, further research is needed to fully explore the limitations and broader societal implications of this technology.
Overall, this work represents an important step forward in the quest to develop AI systems with more flexible, compositional understanding of human actions and behaviors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition
Rongchang Li, Zhenhua Feng, Tianyang Xu, Linze Li, Xiao-Jun Wu, Muhammad Awais, Sara Atito, Josef Kittler
Compositional actions consist of dynamic (verbs) and static (objects) concepts. Humans can easily recognize unseen compositions using the learned concepts. For machines, solving such a problem requires a model to recognize unseen actions composed of previously observed verbs and objects, thus requiring so-called compositional generalization ability. To facilitate this research, we propose a novel Zero-Shot Compositional Action Recognition (ZS-CAR) task. For evaluating the task, we construct a new benchmark, Something-composition (Sth-com), based on the widely used Something-Something V2 dataset. We also propose a novel Component-to-Composition (C2C) learning method to solve the new ZS-CAR task. C2C includes an independent component learning module and a composition inference module. Last, we devise an enhanced training strategy to address the challenges of component variations between seen and unseen compositions and to handle the subtle balance between learning seen and unseen actions. The experimental results demonstrate that the proposed framework significantly surpasses the existing compositional generalization methods and sets a new state-of-the-art. The new Sth-com benchmark and code are available at https://github.com/RongchangLi/ZSCAR_C2C.
Read more7/22/2024
0
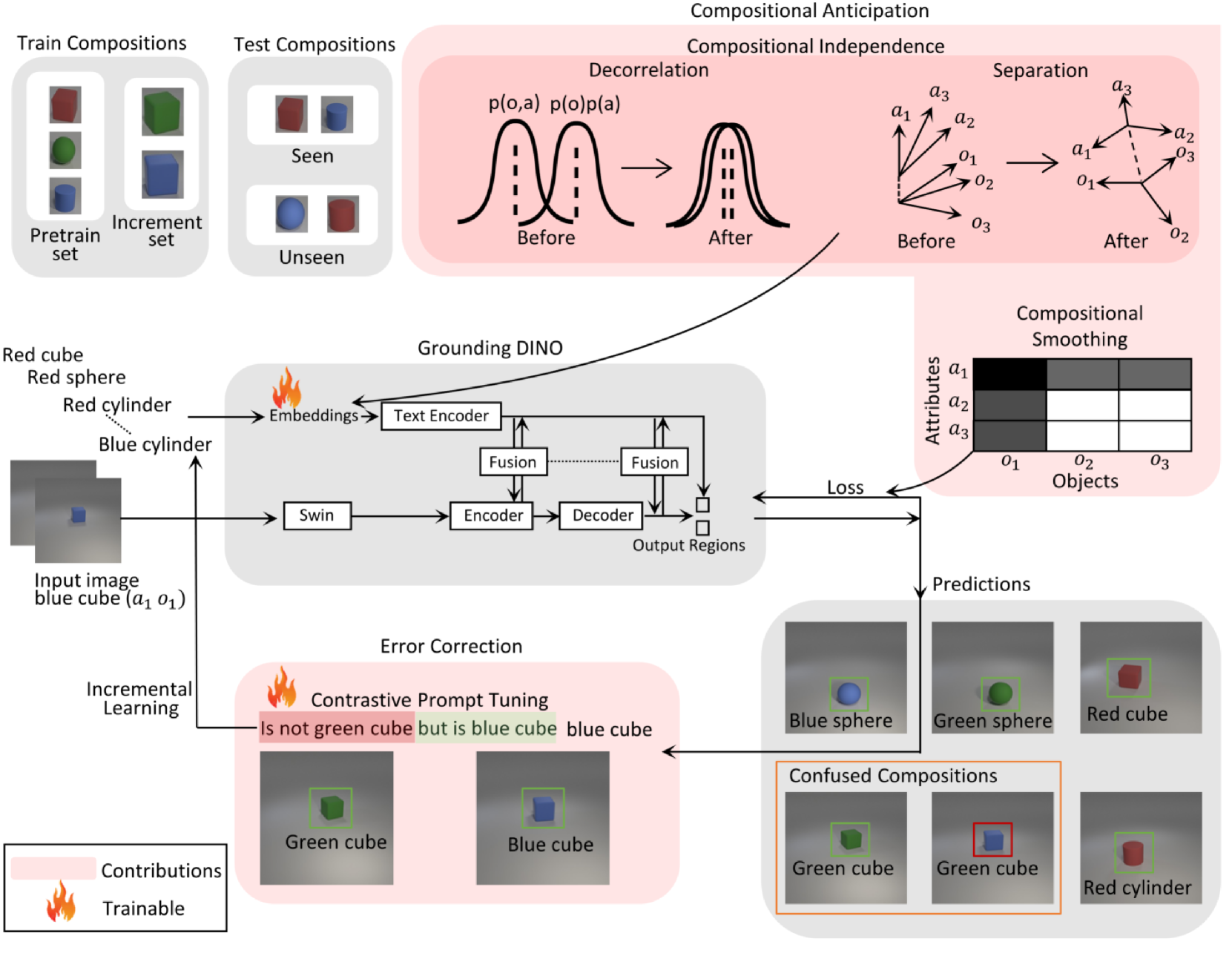
Anticipating Future Object Compositions without Forgetting
Youssef Zahran, Gertjan Burghouts, Yke Bauke Eisma
Despite the significant advancements in computer vision models, their ability to generalize to novel object-attribute compositions remains limited. Existing methods for Compositional Zero-Shot Learning (CZSL) mainly focus on image classification. This paper aims to enhance CZSL in object detection without forgetting prior learned knowledge. We use Grounding DINO and incorporate Compositional Soft Prompting (CSP) into it and extend it with Compositional Anticipation. We achieve a 70.5% improvement over CSP on the harmonic mean (HM) between seen and unseen compositions on the CLEVR dataset. Furthermore, we introduce Contrastive Prompt Tuning to incrementally address model confusion between similar compositions. We demonstrate the effectiveness of this method and achieve an increase of 14.5% in HM across the pretrain, increment, and unseen sets. Collectively, these methods provide a framework for learning various compositions with limited data, as well as improving the performance of underperforming compositions when additional data becomes available.
Read more9/4/2024
👁️
0
The impact of Compositionality in Zero-shot Multi-label action recognition for Object-based tasks
Carmela Calabrese, Stefano Berti, Giulia Pasquale, Lorenzo Natale
Addressing multi-label action recognition in videos represents a significant challenge for robotic applications in dynamic environments, especially when the robot is required to cooperate with humans in tasks that involve objects. Existing methods still struggle to recognize unseen actions or require extensive training data. To overcome these problems, we propose Dual-VCLIP, a unified approach for zero-shot multi-label action recognition. Dual-VCLIP enhances VCLIP, a zero-shot action recognition method, with the DualCoOp method for multi-label image classification. The strength of our method is that at training time it only learns two prompts, and it is therefore much simpler than other methods. We validate our method on the Charades dataset that includes a majority of object-based actions, demonstrating that -- despite its simplicity -- our method performs favorably with respect to existing methods on the complete dataset, and promising performance when tested on unseen actions. Our contribution emphasizes the impact of verb-object class-splits during robots' training for new cooperative tasks, highlighting the influence on the performance and giving insights into mitigating biases.
Read more5/15/2024

0
Contextual Interaction via Primitive-based Adversarial Training For Compositional Zero-shot Learning
Suyi Li, Chenyi Jiang, Shidong Wang, Yang Long, Zheng Zhang, Haofeng Zhang
Compositional Zero-shot Learning (CZSL) aims to identify novel compositions via known attribute-object pairs. The primary challenge in CZSL tasks lies in the significant discrepancies introduced by the complex interaction between the visual primitives of attribute and object, consequently decreasing the classification performance towards novel compositions. Previous remarkable works primarily addressed this issue by focusing on disentangling strategy or utilizing object-based conditional probabilities to constrain the selection space of attributes. Unfortunately, few studies have explored the problem from the perspective of modeling the mechanism of visual primitive interactions. Inspired by the success of vanilla adversarial learning in Cross-Domain Few-Shot Learning, we take a step further and devise a model-agnostic and Primitive-Based Adversarial training (PBadv) method to deal with this problem. Besides, the latest studies highlight the weakness of the perception of hard compositions even under data-balanced conditions. To this end, we propose a novel over-sampling strategy with object-similarity guidance to augment target compositional training data. We performed detailed quantitative analysis and retrieval experiments on well-established datasets, such as UT-Zappos50K, MIT-States, and C-GQA, to validate the effectiveness of our proposed method, and the state-of-the-art (SOTA) performance demonstrates the superiority of our approach. The code is available at https://github.com/lisuyi/PBadv_czsl.
Read more6/24/2024