The impact of Compositionality in Zero-shot Multi-label action recognition for Object-based tasks

0
👁️
Sign in to get full access
Overview
- Addresses the challenge of multi-label action recognition in videos for robotic applications
- Proposes Dual-VCLIP, a unified approach for zero-shot multi-label action recognition
- Enhances VCLIP, a zero-shot action recognition method, with the DualCoOp method for multi-label image classification
- Validates the method on the Charades dataset, showing promising performance on unseen actions
Plain English Explanation
Robots working in dynamic environments with humans need to be able to recognize and understand multiple actions happening at the same time. Existing methods still struggle to recognize actions they haven't seen before or require a lot of training data.
To address these problems, the researchers developed Dual-VCLIP, a new approach that combines two existing techniques. VCLIP is a method for recognizing actions without needing to train on them beforehand (zero-shot learning). DualCoOp is a way to classify multiple labels in an image. By bringing these two ideas together, Dual-VCLIP can recognize multiple actions in a video, even if it hasn't seen those actions before.
The key advantage of Dual-VCLIP is that it only needs to learn two "prompts" (short descriptions) during training, making it much simpler than other multi-label action recognition methods. The researchers tested it on a dataset of everyday household activities involving objects, and found that despite its simplicity, Dual-VCLIP performed well compared to other approaches, especially at recognizing new, unseen actions.
This work highlights the importance of how robots are trained on verbs (actions) and objects when learning new cooperative tasks with humans. The way these elements are split up during training can significantly impact the robot's performance and help address biases.
Technical Explanation
The core innovation of Dual-VCLIP is that it combines two existing techniques - VCLIP, a zero-shot action recognition method, and DualCoOp, a multi-label image classification approach - into a unified framework for zero-shot multi-label action recognition.
VCLIP works by learning a joint embedding space between visual inputs and text descriptions, allowing it to recognize actions it hasn't been explicitly trained on. DualCoOp builds on this by learning two separate embeddings - one for verbs and one for objects - and using them together to classify multiple labels in an image.
Dual-VCLIP adopts this dual-embedding approach from DualCoOp and applies it to the zero-shot action recognition task of VCLIP. This allows the model to recognize multiple, previously unseen actions in video frames, simply by learning two prompts during training: one for verbs and one for objects.
The researchers evaluate Dual-VCLIP on the Charades dataset, which contains a variety of everyday household activities involving interactions with objects. They show that despite its relative simplicity, Dual-VCLIP performs on par with or better than existing methods on the full dataset, and demonstrates promising performance on unseen actions.
Critical Analysis
The paper makes a valuable contribution by addressing the challenge of multi-label action recognition, which is crucial for real-world robotic applications. By building on top of VCLIP and DualCoOp, the authors have developed a conceptually simple yet effective approach.
One limitation mentioned in the paper is that the model's performance can be sensitive to the specific way the verb and object classes are split during training, as this can introduce biases. The authors provide some insights into mitigating these biases, but further research may be needed to fully understand and address this issue.
Additionally, while the Charades dataset provides a relevant testbed, it would be interesting to see how Dual-VCLIP performs on a wider range of datasets and real-world robotic scenarios. Evaluating the model's generalization capabilities and robustness to different types of actions and environments could be valuable areas for future work.
Overall, the Dual-VCLIP method represents a promising step forward in zero-shot multi-label action recognition, and the insights around verb-object class splits could have broader implications for how robots are trained to cooperate with humans in dynamic, object-centric tasks.
Conclusion
The Dual-VCLIP approach proposed in this paper addresses the important challenge of multi-label action recognition for robotic applications in dynamic environments. By combining the strengths of VCLIP and DualCoOp, the authors have developed a simple yet effective method for recognizing multiple, previously unseen actions in video frames.
The key contribution of this work is the insight that the way verbs and objects are split during training can significantly impact the model's performance and help mitigate biases. This has important implications for how robots are trained to collaborate with humans in complex, real-world tasks involving interactions with objects.
While further research is needed to fully understand the limitations and generalization capabilities of Dual-VCLIP, this paper represents a valuable step forward in advancing the state of the art in zero-shot multi-label action recognition for robotic applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
The impact of Compositionality in Zero-shot Multi-label action recognition for Object-based tasks
Carmela Calabrese, Stefano Berti, Giulia Pasquale, Lorenzo Natale
Addressing multi-label action recognition in videos represents a significant challenge for robotic applications in dynamic environments, especially when the robot is required to cooperate with humans in tasks that involve objects. Existing methods still struggle to recognize unseen actions or require extensive training data. To overcome these problems, we propose Dual-VCLIP, a unified approach for zero-shot multi-label action recognition. Dual-VCLIP enhances VCLIP, a zero-shot action recognition method, with the DualCoOp method for multi-label image classification. The strength of our method is that at training time it only learns two prompts, and it is therefore much simpler than other methods. We validate our method on the Charades dataset that includes a majority of object-based actions, demonstrating that -- despite its simplicity -- our method performs favorably with respect to existing methods on the complete dataset, and promising performance when tested on unseen actions. Our contribution emphasizes the impact of verb-object class-splits during robots' training for new cooperative tasks, highlighting the influence on the performance and giving insights into mitigating biases.
Read more5/15/2024

0
C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition
Rongchang Li, Zhenhua Feng, Tianyang Xu, Linze Li, Xiao-Jun Wu, Muhammad Awais, Sara Atito, Josef Kittler
Compositional actions consist of dynamic (verbs) and static (objects) concepts. Humans can easily recognize unseen compositions using the learned concepts. For machines, solving such a problem requires a model to recognize unseen actions composed of previously observed verbs and objects, thus requiring so-called compositional generalization ability. To facilitate this research, we propose a novel Zero-Shot Compositional Action Recognition (ZS-CAR) task. For evaluating the task, we construct a new benchmark, Something-composition (Sth-com), based on the widely used Something-Something V2 dataset. We also propose a novel Component-to-Composition (C2C) learning method to solve the new ZS-CAR task. C2C includes an independent component learning module and a composition inference module. Last, we devise an enhanced training strategy to address the challenges of component variations between seen and unseen compositions and to handle the subtle balance between learning seen and unseen actions. The experimental results demonstrate that the proposed framework significantly surpasses the existing compositional generalization methods and sets a new state-of-the-art. The new Sth-com benchmark and code are available at https://github.com/RongchangLi/ZSCAR_C2C.
Read more7/22/2024
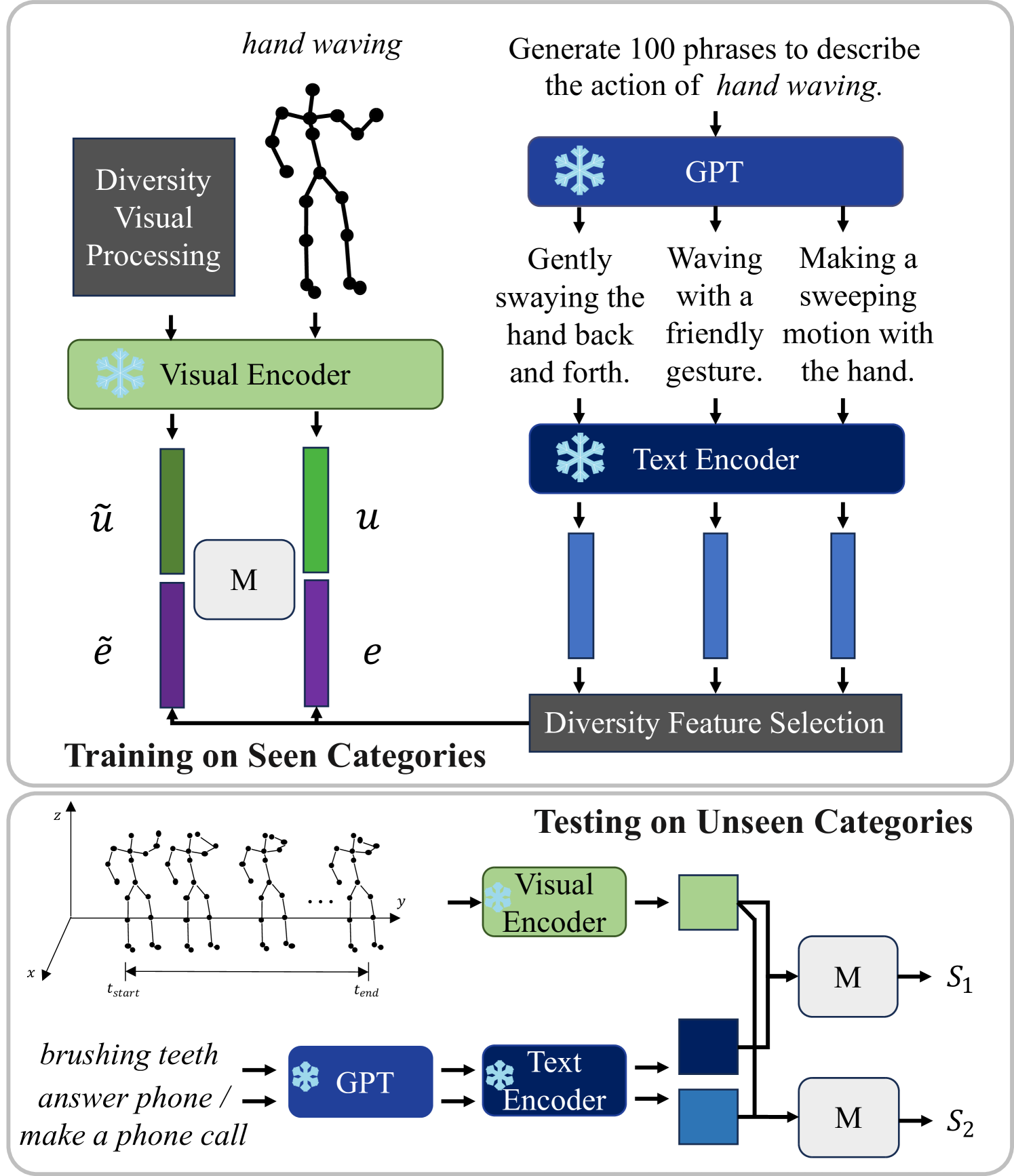
0
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024

0
Open Vocabulary Multi-Label Video Classification
Rohit Gupta, Mamshad Nayeem Rizve, Jayakrishnan Unnikrishnan, Ashish Tawari, Son Tran, Mubarak Shah, Benjamin Yao, Trishul Chilimbi
Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
Read more7/15/2024