C3LLM: Conditional Multimodal Content Generation Using Large Language Models

0
Sign in to get full access
Overview
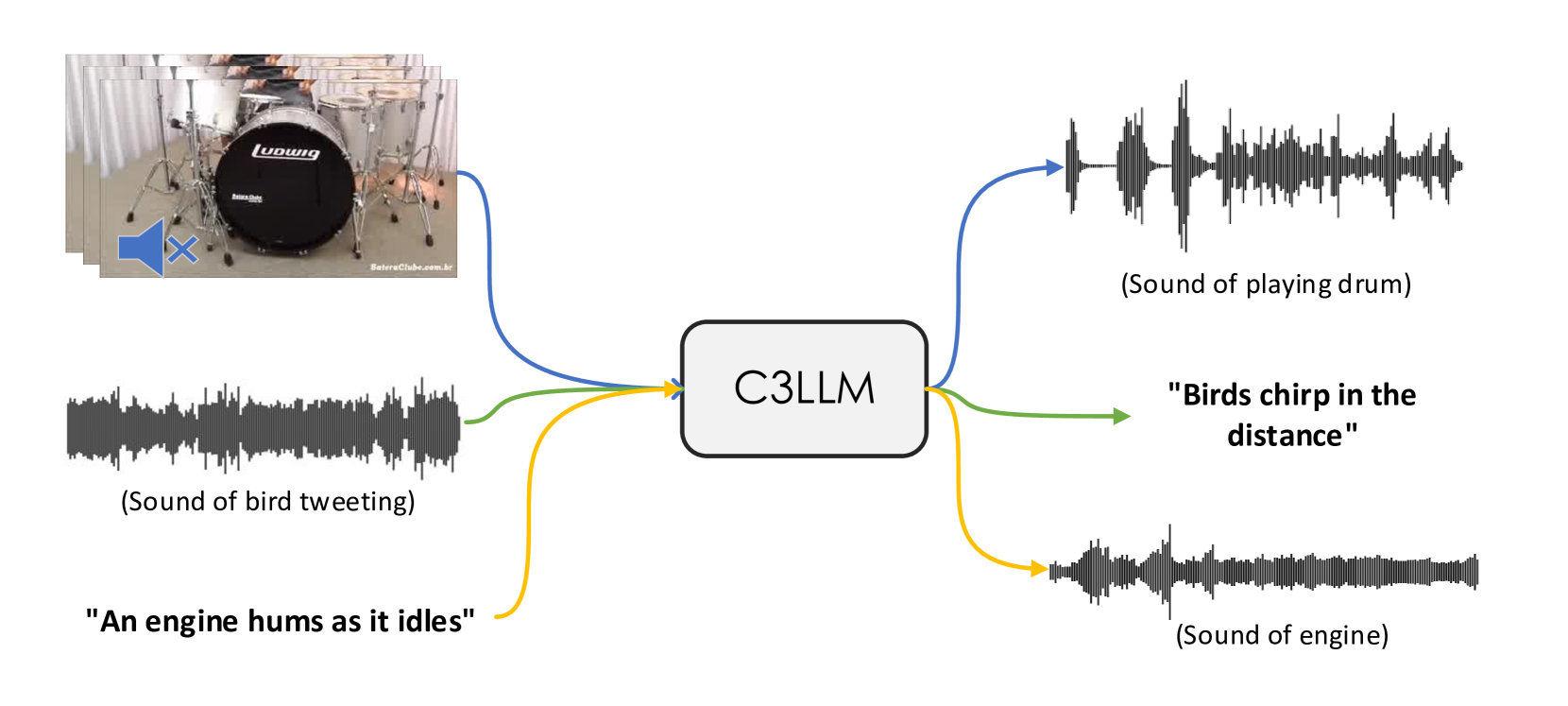
- The paper presents C3LLM, a framework for conditional multimodal content generation using large language models.
- C3LLM enables the generation of multimodal content like images, text, and other modalities conditioned on various inputs.
- The system leverages large language models as the foundation and extends them to handle multimodal generation.
Plain English Explanation
The researchers have developed a system called C3LLM that can create different types of content, like images and text, based on specific inputs or instructions. This system is built on top of large language models, which are advanced AI models trained on vast amounts of text data.
By building on these powerful language models, the C3LLM framework is able to generate multimodal content - meaning it can produce not just text, but also images, audio, and other types of media. The key innovation is that the system can create this content in a "conditional" way, where the output is tailored to the specific inputs or instructions provided.
For example, you could give C3LLM a written prompt describing a scene, and it would generate an image matching that description. Or you could provide it with some initial text, and it would continue generating additional text or even create accompanying visuals. The system aims to make it easier to produce diverse, high-quality content in a more controlled and customized way.
Technical Explanation
The C3LLM framework builds on the capabilities of large language models to enable conditional multimodal content generation. The key innovations include:
- Multimodal Conditioning: C3LLM can accept various types of input modalities, such as text, images, and even structured data, and use these to condition the generation of output across different modalities.
- Modular Architecture: The system has a modular design, with separate components for encoding input, generating output, and fusing the modalities, allowing for flexible combinations and customization.
- Prompt Engineering: The paper explores techniques for engineering prompts that can effectively guide the multimodal generation process, leveraging the language understanding of the underlying large language model.
Through a series of experiments, the researchers demonstrate C3LLM's ability to generate diverse outputs, including images, text, and even 3D models, conditioned on various input combinations. The results highlight the potential of large language models as a foundation for advancing multimodal content generation capabilities.
Critical Analysis
The C3LLM paper presents a promising approach to leveraging large language models for conditional multimodal content generation. However, some potential limitations and areas for further research are worth considering:
- Generalization and Scalability: While the experiments demonstrate the versatility of the C3LLM framework, it's unclear how well the system would scale to handle more complex or diverse inputs and outputs. Further research is needed to assess the generalization capabilities of the approach.
- Multimodal Alignment and Coherence: Ensuring that the generated multimodal content is well-aligned and coherent remains a challenge. The paper briefly mentions techniques for prompt engineering, but more work may be required to consistently produce high-quality, semantically aligned outputs.
- Ethical Considerations: As with any powerful content generation system, there are potential ethical concerns around the misuse of such technology, such as the generation of harmful or misleading content. Addressing these issues should be a priority in further development of the C3LLM framework.
Overall, the C3LLM paper represents an exciting step forward in the field of multimodal content generation and highlights the potential of large language models as a foundation for advanced multimedia creation tools. Continued research and careful consideration of the system's limitations and societal implications will be crucial for realizing the full potential of this technology.
Conclusion
The C3LLM framework demonstrates how large language models can be leveraged to enable conditional multimodal content generation. By allowing users to provide various types of input to guide the generation process, C3LLM opens up new possibilities for creating diverse, customized multimedia content.
While the paper highlights the technical advancements and experimental successes of the system, it also raises important questions about the ethical considerations and scalability challenges that must be addressed as this technology continues to evolve. As large language models and multimodal generation systems become more powerful and accessible, it will be crucial to ensure they are developed and deployed responsibly, with a focus on maximizing their benefits while mitigating potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
C3LLM: Conditional Multimodal Content Generation Using Large Language Models
Zixuan Wang, Qinkai Duan, Yu-Wing Tai, Chi-Keung Tang
We introduce C3LLM (Conditioned-on-Three-Modalities Large Language Models), a novel framework combining three tasks of video-to-audio, audio-to-text, and text-to-audio together. C3LLM adapts the Large Language Model (LLM) structure as a bridge for aligning different modalities, synthesizing the given conditional information, and making multimodal generation in a discrete manner. Our contributions are as follows. First, we adapt a hierarchical structure for audio generation tasks with pre-trained audio codebooks. Specifically, we train the LLM to generate audio semantic tokens from the given conditions, and further use a non-autoregressive transformer to generate different levels of acoustic tokens in layers to better enhance the fidelity of the generated audio. Second, based on the intuition that LLMs were originally designed for discrete tasks with the next-word prediction method, we use the discrete representation for audio generation and compress their semantic meanings into acoustic tokens, similar to adding acoustic vocabulary to LLM. Third, our method combines the previous tasks of audio understanding, video-to-audio generation, and text-to-audio generation together into one unified model, providing more versatility in an end-to-end fashion. Our C3LLM achieves improved results through various automated evaluation metrics, providing better semantic alignment compared to previous methods.
Read more5/28/2024

0
LLMs Meet Multimodal Generation and Editing: A Survey
Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, Jifeng Dai, Yong Zhang, Wei Xue, Qifeng Liu, Yike Guo, Qifeng Chen
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on multimodal understanding. This survey elaborates on multimodal generation and editing across various domains, comprising image, video, 3D, and audio. Specifically, we summarize the notable advancements with milestone works in these fields and categorize these studies into LLM-based and CLIP/T5-based methods. Then, we summarize the various roles of LLMs in multimodal generation and exhaustively investigate the critical technical components behind these methods and the multimodal datasets utilized in these studies. Additionally, we dig into tool-augmented multimodal agents that can leverage existing generative models for human-computer interaction. Lastly, we discuss the advancements in the generative AI safety field, investigate emerging applications, and discuss future prospects. Our work provides a systematic and insightful overview of multimodal generation and processing, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
Read more6/11/2024

0
A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Read more4/3/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024