CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning
2403.07300
0
0
Abstract
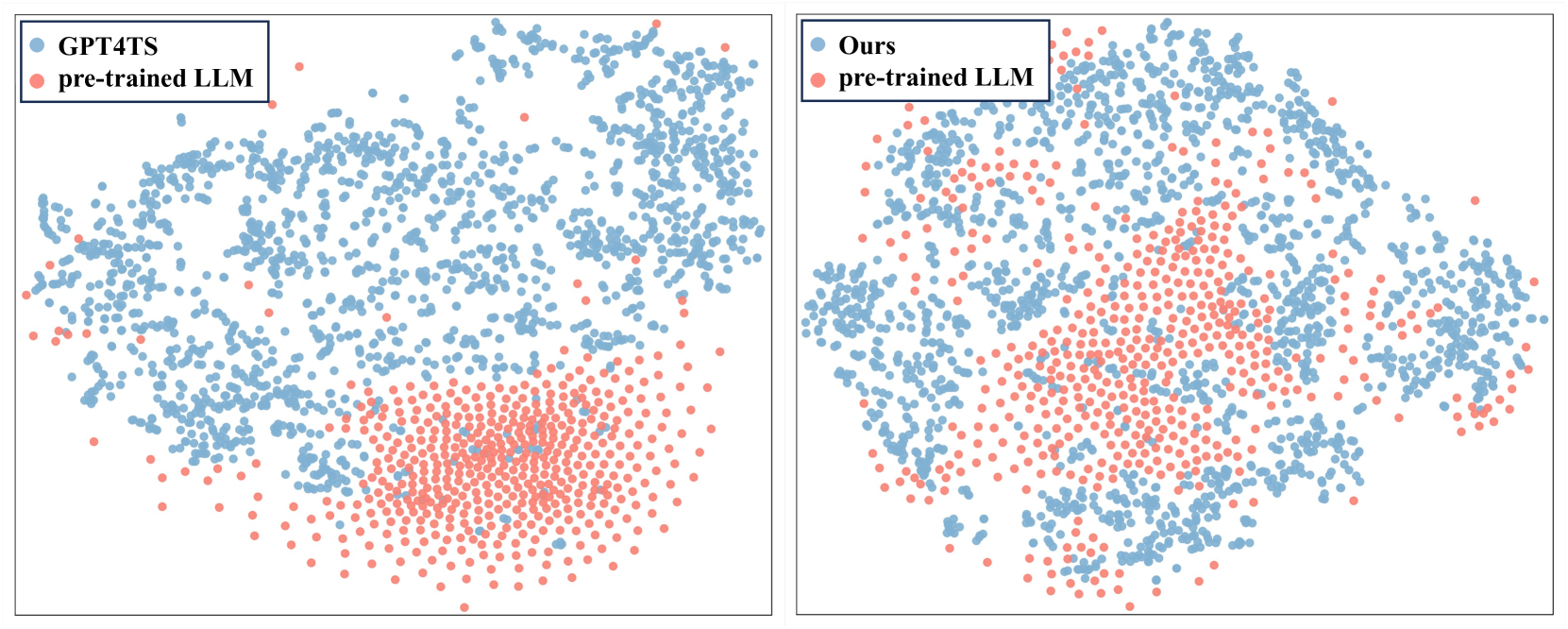
Deep learning (e.g., Transformer) has been widely and successfully used in multivariate time series forecasting (MTSF). Unlike existing methods that focus on training models from a single modal of time series input, large language models (LLMs) based MTSF methods with cross-modal text and time series input have recently shown great superiority, especially with limited temporal data. However, current LLM-based MTSF methods usually focus on adapting and fine-tuning LLMs, while neglecting the distribution discrepancy between textual and temporal input tokens, thus leading to sub-optimal performance. To address this issue, we propose a novel Cross-Modal LLM Fine-Tuning (CALF) framework for MTSF by reducing the distribution discrepancy between textual and temporal data, which mainly consists of the temporal target branch with temporal input and the textual source branch with aligned textual input. To reduce the distribution discrepancy, we develop the cross-modal match module to first align cross-modal input distributions. Additionally, to minimize the modality distribution gap in both feature and output spaces, feature regularization loss is developed to align the intermediate features between the two branches for better weight updates, while output consistency loss is introduced to allow the output representations of both branches to correspond effectively. Thanks to the modality alignment, CALF establishes state-of-the-art performance for both long-term and short-term forecasting tasks with low computational complexity, and exhibiting favorable few-shot and zero-shot abilities similar to that in LLMs. Code is available at url{https://github.com/Hank0626/LLaTA}.
Create account to get full access
Overview
- The paper presents a novel approach to time series forecasting using pre-trained large language models (LLMs) and cross-modal knowledge distillation.
- The method aims to leverage the rich semantic and contextual knowledge in LLMs to improve the generalization and performance of time series forecasting models.
- The key innovation is the use of cross-modal knowledge distillation, which transfers knowledge from the LLM to a specialized time series forecasting model.
Plain English Explanation
The researchers in this study wanted to find a way to use powerful language models, known as large language models (LLMs), to help with forecasting time series data. Time series data is information that is collected over time, like stock prices or weather patterns. Forecasting this type of data can be challenging, but the researchers thought the rich knowledge stored in LLMs could be helpful.
To do this, they developed a new method that transfers the knowledge from the LLM to a specialized time series forecasting model. This process is called "cross-modal knowledge distillation." The idea is that the LLM has learned a lot about language and the world in general, and this knowledge can be used to improve the performance of the time series forecasting model.
By combining the strengths of the LLM and the time series forecasting model, the researchers were able to create a system that can make more accurate predictions about future time series data, even for new and unfamiliar datasets. This could have important applications in fields like finance, healthcare, and climate science, where accurate forecasting is crucial.
Technical Explanation
The paper proposes a novel approach to time series forecasting that leverages the rich semantic and contextual knowledge captured in pre-trained large language models (LLMs). The key innovation is the use of cross-modal knowledge distillation, which allows the researchers to transfer knowledge from the LLM to a specialized time series forecasting model.
The proposed method, called CLAIRVOYANT, consists of three main components:
- Temporal Encoder: A transformer-based encoder that captures the temporal dependencies in the time series data.
- Cross-modal Distillation: A knowledge distillation process that transfers relevant knowledge from the pre-trained LLM to the time series forecasting model.
- Decoder: A neural network that generates the final time series forecasts.
The cross-modal distillation process is the core of the CLAIRVOYANT approach. It allows the model to leverage the broad and deep knowledge in the LLM to improve the generalization and performance of the time series forecasting model.
The researchers evaluate CLAIRVOYANT on a wide range of time series forecasting benchmarks and demonstrate significant improvements over state-of-the-art methods. They also conduct ablation studies to understand the contributions of the different components of their approach.
Critical Analysis
The paper presents a well-designed and thorough study that makes a compelling case for the effectiveness of their proposed CLAIRVOYANT approach. The cross-modal knowledge distillation technique is a clever way to harness the capabilities of pre-trained LLMs for time series forecasting, which is an important and challenging problem.
However, the paper does not address some potential limitations and areas for further research. For example, the method relies on the availability of a pre-trained LLM, which may not always be accessible or easy to fine-tune, especially for domain-specific applications. Additionally, the performance of the method on real-world, noisy, and high-dimensional time series data could be further investigated.
Overall, the CLAIRVOYANT approach is a promising step towards leveraging the power of LLMs for generalized time series forecasting, and the paper makes a valuable contribution to the field.
Conclusion
The paper introduces a novel approach called CLAIRVOYANT that uses cross-modal knowledge distillation to harness the rich semantic and contextual knowledge of pre-trained large language models (LLMs) for time series forecasting. The key innovation is the ability to effectively transfer knowledge from the LLM to a specialized time series forecasting model, enabling improved generalization and performance on a wide range of benchmarks.
This research has the potential to significantly impact fields that rely on accurate time series forecasting, such as finance, healthcare, and climate science. By combining the strengths of LLMs and specialized time series models, the CLAIRVOYANT approach represents an important step forward in the quest for more reliable and generalizable forecasting capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TimeCMA: Towards LLM-Empowered Time Series Forecasting via Cross-Modality Alignment
Chenxi Liu, Qianxiong Xu, Hao Miao, Sun Yang, Lingzheng Zhang, Cheng Long, Ziyue Li, Rui Zhao
0
0
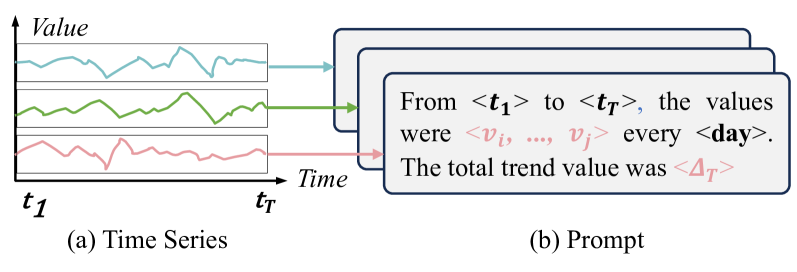
The widespread adoption of scalable mobile sensing has led to large amounts of time series data for real-world applications. A fundamental application is multivariate time series forecasting (MTSF), which aims to predict future time series values based on historical observations. Existing MTSF methods suffer from limited parameterization and small-scale training data. Recently, Large language models (LLMs) have been introduced in time series, which achieve promising forecasting performance but incur heavy computational costs. To solve these challenges, we propose TimeCMA, an LLM-empowered framework for time series forecasting with cross-modality alignment. We design a dual-modality encoding module with two branches, where the time series encoding branch extracts relatively low-quality yet pure embeddings of time series through an inverted Transformer. In addition, the LLM-empowered encoding branch wraps the same time series as prompts to obtain high-quality yet entangled prompt embeddings via a Pre-trained LLM. Then, we design a cross-modality alignment module to retrieve high-quality and pure time series embeddings from the prompt embeddings. Moreover, we develop a time series forecasting module to decode the aligned embeddings while capturing dependencies among multiple variables for forecasting. Notably, we tailor the prompt to encode sufficient temporal information into a last token and design the last token embedding storage to reduce computational costs. Extensive experiments on real data offer insight into the accuracy and efficiency of the proposed framework.
6/17/2024
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vuli'c, Anna Korhonen, Mohamed Hammad
0
0
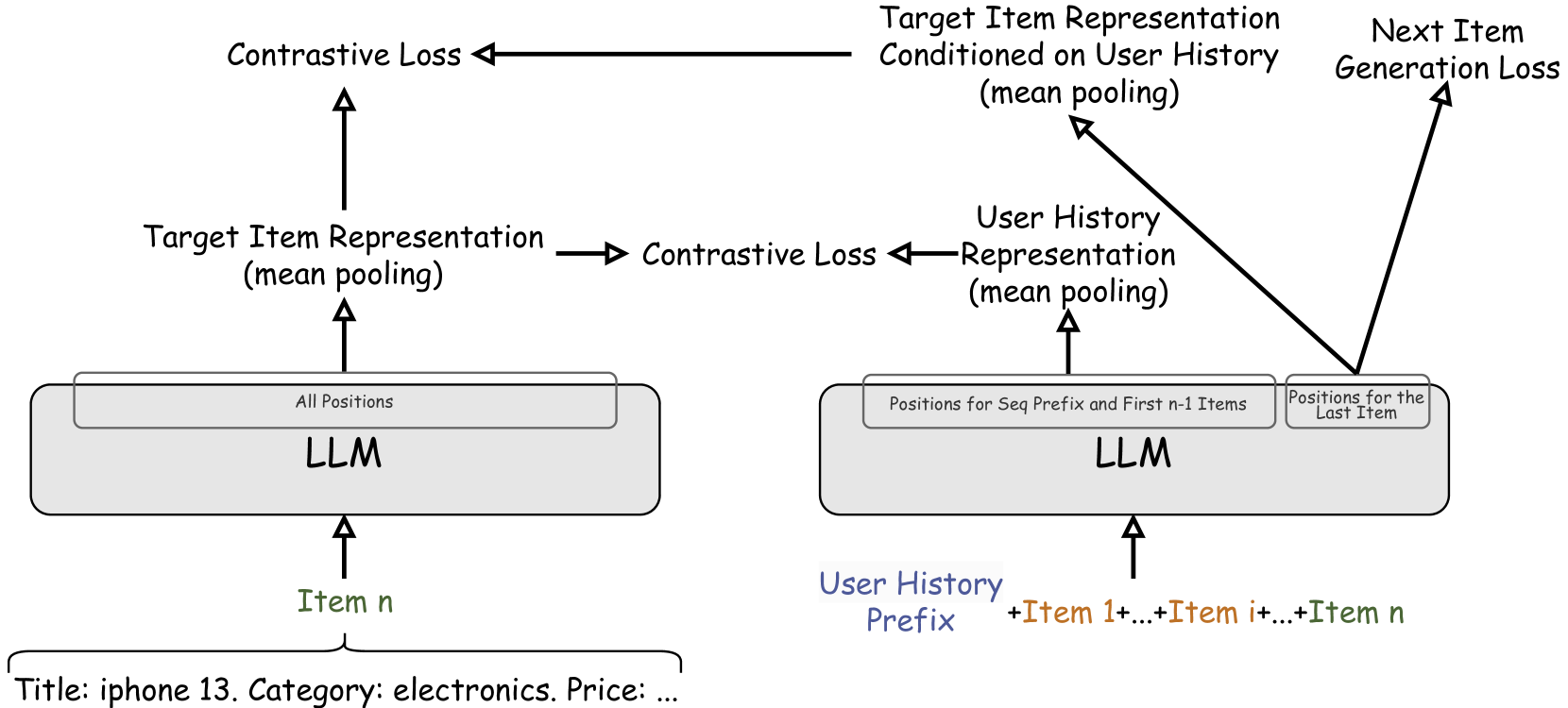
Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
5/7/2024

Text-centric Alignment for Multi-Modality Learning
Yun-Da Tsai, Ting-Yu Yen, Pei-Fu Guo, Zhe-Yan Li, Shou-De Lin
0
0
This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
5/22/2024
💬
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
Fei Zhao, Taotian Pang, Chunhui Li, Zhen Wu, Junjie Guo, Shangyu Xing, Xinyu Dai
0
0
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
5/24/2024