TimeCMA: Towards LLM-Empowered Time Series Forecasting via Cross-Modality Alignment
2406.01638
0
0
Abstract
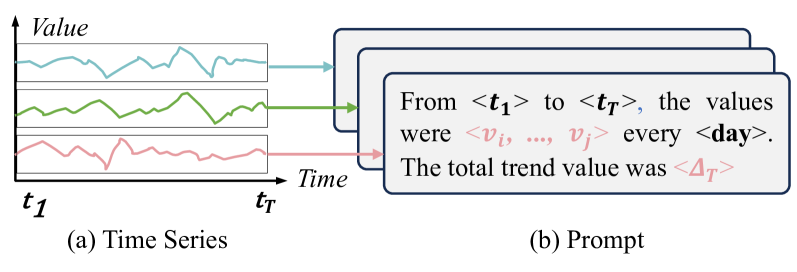
The widespread adoption of scalable mobile sensing has led to large amounts of time series data for real-world applications. A fundamental application is multivariate time series forecasting (MTSF), which aims to predict future time series values based on historical observations. Existing MTSF methods suffer from limited parameterization and small-scale training data. Recently, Large language models (LLMs) have been introduced in time series, which achieve promising forecasting performance but incur heavy computational costs. To solve these challenges, we propose TimeCMA, an LLM-empowered framework for time series forecasting with cross-modality alignment. We design a dual-modality encoding module with two branches, where the time series encoding branch extracts relatively low-quality yet pure embeddings of time series through an inverted Transformer. In addition, the LLM-empowered encoding branch wraps the same time series as prompts to obtain high-quality yet entangled prompt embeddings via a Pre-trained LLM. Then, we design a cross-modality alignment module to retrieve high-quality and pure time series embeddings from the prompt embeddings. Moreover, we develop a time series forecasting module to decode the aligned embeddings while capturing dependencies among multiple variables for forecasting. Notably, we tailor the prompt to encode sufficient temporal information into a last token and design the last token embedding storage to reduce computational costs. Extensive experiments on real data offer insight into the accuracy and efficiency of the proposed framework.
Create account to get full access
Overview
- This paper introduces TimeCMA, a novel approach that leverages large language models (LLMs) to enhance time series forecasting performance.
- The key idea is to align the representations of time series data and textual information through cross-modality alignment, enabling LLMs to provide valuable insights and improve forecasting accuracy.
- The paper presents extensive experiments on various benchmark datasets, demonstrating the effectiveness of TimeCMA in outperforming state-of-the-art time series forecasting models.
Plain English Explanation
The paper discusses a new technique called TimeCMA that aims to improve time series forecasting, which is the process of predicting future values based on historical data. Time series forecasting is a crucial task in many industries, such as finance, healthcare, and supply chain management.
The researchers behind TimeCMA noticed that large language models (LLMs), such as GPT-3, have become incredibly powerful at processing and understanding natural language. They hypothesized that if they could find a way to connect the information in time series data (e.g., stock prices, weather patterns, or production numbers) with the knowledge and reasoning capabilities of LLMs, they could potentially enhance the accuracy of time series forecasting.
To achieve this, the researchers developed a method called "cross-modality alignment," which bridges the gap between the numerical time series data and the text-based representations used by LLMs. By aligning these two different types of information, the LLM can leverage its understanding of language and concepts to inform and improve the time series forecasting process.
Through extensive experiments on various benchmark datasets, the researchers demonstrated that TimeCMA outperforms other state-of-the-art time series forecasting models. This suggests that the integration of LLMs and cross-modality alignment can be a powerful approach for enhancing the performance of time series forecasting, with potential applications in a wide range of industries and domains.
Technical Explanation
The paper introduces a novel approach called TimeCMA (link to AutoTiES paper) that leverages the power of large language models (LLMs) to improve time series forecasting. The key idea is to align the representations of time series data and textual information through cross-modality alignment (link to CALF paper), enabling LLMs to provide valuable insights and enhance forecasting accuracy.
The TimeCMA architecture consists of three main components:
- A time series encoder that transforms the input time series data into a latent representation.
- A cross-modality alignment module that aligns the time series latent representation with the text-based representations of the LLM.
- A forecasting head that generates the final time series predictions based on the aligned representations.
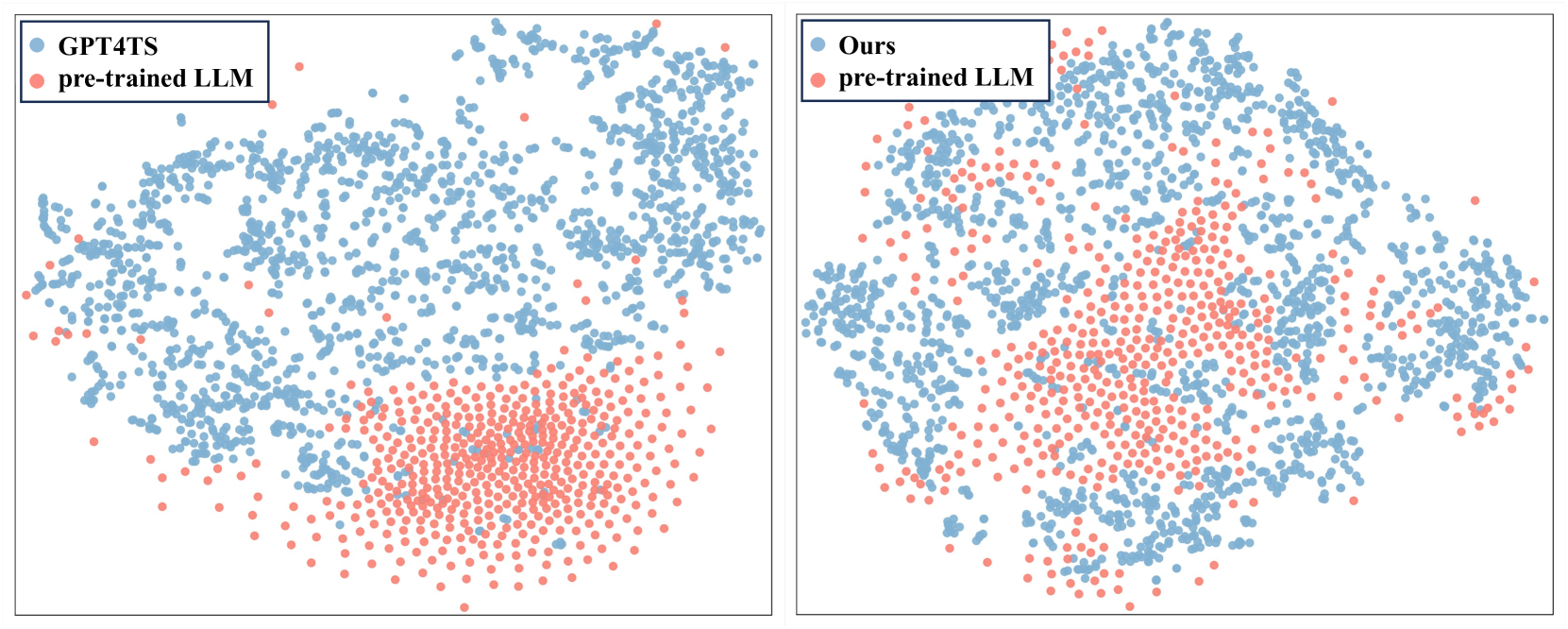
The cross-modality alignment module is a crucial component of TimeCMA, as it bridges the gap between the numerical time series data and the text-based representations used by LLMs. This alignment allows the LLM to leverage its understanding of language, concepts, and reasoning to improve the time series forecasting process.
The researchers evaluated TimeCMA on various benchmark time series forecasting datasets, including link to MultiCast paper and link to Time-FFL paper. The results demonstrate that TimeCMA outperforms state-of-the-art time series forecasting models, highlighting the effectiveness of integrating LLMs and cross-modality alignment for enhancing time series forecasting performance.
Critical Analysis
The paper presents a promising approach for leveraging large language models to improve time series forecasting, but it also acknowledges several limitations and areas for further research:
-
Interpretability: While TimeCMA demonstrates strong empirical performance, the inner workings of the cross-modality alignment module and the specific mechanisms by which the LLM contributes to the forecasting process are not fully explored. Improving the interpretability of the model could help users understand and trust the forecasting decisions.
-
Robustness and Generalization: The paper focuses on evaluating TimeCMA on standard benchmark datasets, but real-world time series data can be noisy, incomplete, or subject to concept drift. Further research is needed to assess the model's robustness and ability to generalize to more challenging, real-world time series forecasting scenarios.
-
Computational Efficiency: Integrating large language models can be computationally intensive, which may limit the practical deployment of TimeCMA, especially in resource-constrained environments. Exploring ways to improve the computational efficiency of the approach could enhance its practicality.
-
Multivariate Forecasting: The current version of TimeCMA focuses on univariate time series forecasting. Extending the approach to handle multivariate time series data, where multiple related variables are forecasted simultaneously, could further broaden its applicability.
Overall, the TimeCMA approach represents an exciting step forward in the integration of large language models and time series forecasting. However, the identified limitations and areas for further research suggest that there is still room for improvement and refinement to make the technique more robust, interpretable, and efficient for real-world deployment.
Conclusion
The paper introduces TimeCMA, a novel approach that leverages large language models (LLMs) to enhance the performance of time series forecasting. By aligning the representations of time series data and textual information through cross-modality alignment, TimeCMA enables LLMs to provide valuable insights and improve forecasting accuracy.
The extensive experiments conducted on various benchmark datasets demonstrate the effectiveness of TimeCMA, as it outperforms state-of-the-art time series forecasting models. This suggests that the integration of LLMs and cross-modality alignment can be a promising direction for advancing the field of time series forecasting, with potential applications in diverse industries and domains.
While TimeCMA shows promising results, the paper also highlights areas for further research, such as improving the interpretability of the model, assessing its robustness and generalization, and exploring ways to enhance computational efficiency. Addressing these challenges can contribute to the development of more robust, practical, and widely applicable time series forecasting solutions that leverage the power of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning
Peiyuan Liu, Hang Guo, Tao Dai, Naiqi Li, Jigang Bao, Xudong Ren, Yong Jiang, Shu-Tao Xia
0
0
Deep learning (e.g., Transformer) has been widely and successfully used in multivariate time series forecasting (MTSF). Unlike existing methods that focus on training models from a single modal of time series input, large language models (LLMs) based MTSF methods with cross-modal text and time series input have recently shown great superiority, especially with limited temporal data. However, current LLM-based MTSF methods usually focus on adapting and fine-tuning LLMs, while neglecting the distribution discrepancy between textual and temporal input tokens, thus leading to sub-optimal performance. To address this issue, we propose a novel Cross-Modal LLM Fine-Tuning (CALF) framework for MTSF by reducing the distribution discrepancy between textual and temporal data, which mainly consists of the temporal target branch with temporal input and the textual source branch with aligned textual input. To reduce the distribution discrepancy, we develop the cross-modal match module to first align cross-modal input distributions. Additionally, to minimize the modality distribution gap in both feature and output spaces, feature regularization loss is developed to align the intermediate features between the two branches for better weight updates, while output consistency loss is introduced to allow the output representations of both branches to correspond effectively. Thanks to the modality alignment, CALF establishes state-of-the-art performance for both long-term and short-term forecasting tasks with low computational complexity, and exhibiting favorable few-shot and zero-shot abilities similar to that in LLMs. Code is available at url{https://github.com/Hank0626/LLaTA}.
5/24/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
💬
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
Foundation models of time series have not been fully developed due to the limited availability of time series corpora and the underexploration of scalable pre-training. Based on the similar sequential formulation of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, the inherent autoregressive property and decoder-only architecture of LLMs have not been fully considered, resulting in insufficient utilization of LLM abilities. To further exploit the general-purpose token transition and multi-step generation ability of large language models, we propose AutoTimes to repurpose LLMs as autoregressive time series forecasters, which independently projects time series segments into the embedding space and autoregressively generates future predictions with arbitrary lengths. Compatible with any decoder-only LLMs, the consequent forecaster exhibits the flexibility of the lookback length and scalability of the LLM size. Further, we formulate time series as prompts, extending the context for prediction beyond the lookback window, termed in-context forecasting. By adopting textual timestamps as position embeddings, AutoTimes integrates multimodality for multivariate scenarios. Empirically, AutoTimes achieves state-of-the-art with 0.1% trainable parameters and over 5 times training/inference speedup compared to advanced LLM-based forecasters.
5/24/2024
📈
Time-FFM: Towards LM-Empowered Federated Foundation Model for Time Series Forecasting
Qingxiang Liu, Xu Liu, Chenghao Liu, Qingsong Wen, Yuxuan Liang
0
0
Unlike natural language processing and computer vision, the development of Foundation Models (FMs) for time series forecasting is blocked due to data scarcity. While recent efforts are focused on building such FMs by unlocking the potential of language models (LMs) for time series analysis, dedicated parameters for various downstream forecasting tasks need training, which hinders the common knowledge sharing across domains. Moreover, data owners may hesitate to share the access to local data due to privacy concerns and copyright protection, which makes it impossible to simply construct a FM on cross-domain training instances. To address these issues, we propose Time-FFM, a Federated Foundation Model for Time series forecasting by leveraging pretrained LMs. Specifically, we begin by transforming time series into the modality of text tokens. To bootstrap LMs for time series reasoning, we propose a prompt adaption module to determine domain-customized prompts dynamically instead of artificially. Given the data heterogeneity across domains, we design a personalized federated training strategy by learning global encoders and local prediction heads. Our comprehensive experiments indicate that Time-FFM outperforms state-of-the-arts and promises effective few-shot and zero-shot forecaster.
5/28/2024