Calibrated Selective Classification
2208.12084
0
0
🏷️
Abstract
Selective classification allows models to abstain from making predictions (e.g., say I don't know) when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with uncertain uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
Create account to get full access
Overview
- Selective classification allows models to abstain from making predictions when uncertain, improving overall accuracy.
- Typical selective models may still produce high-confidence, incorrect predictions or skip low-confidence, correct predictions.
- Calibrated uncertainty estimates can be as important as accurate predictions on average.
- This paper proposes a method for rejecting inputs with unreliable uncertainty estimates to achieve selective calibration.
Plain English Explanation
Machine learning models are often asked to make predictions, like classifying an image or estimating a risk score. Sometimes, these models can be uncertain about their predictions. Selective classification allows the model to say "I don't know" when it's unsure, rather than guessing.
This can lead to better overall accuracy, since the model avoids making mistakes on uncertain inputs. However, even selective models may still produce high-confidence, incorrect predictions or skip over low-confidence, correct predictions. Providing well-calibrated uncertainty estimates - probabilities that match the true frequency of correct predictions - can be just as important as having accurate predictions on average.
Unfortunately, uncertainty estimates can be unreliable for certain inputs. This paper proposes a new approach to selective classification that addresses this issue. The key idea is to have the model also evaluate the reliability of its own uncertainty estimates, and reject inputs where the uncertainty is uncertain. This way, the model can make predictions with well-calibrated uncertainty over the distribution of accepted examples.
The paper presents a framework for training such selectively calibrated models, where a separate "selector" network is trained to improve the calibration of a base prediction model. Importantly, the training process is designed to make the model robust to distribution shifts, so it performs well even on out-of-domain data.
Technical Explanation
The paper introduces a new approach to selective classification, where the model not only predicts the target variable, but also evaluates the reliability of its own uncertainty estimates. This is achieved by training a separate "selector" network alongside the base prediction model.
The selector network is trained to identify examples where the base model's uncertainty estimates are unreliable. By rejecting these examples, the final system can make predictions with well-calibrated uncertainty over the distribution of accepted examples - a property the authors call "selective calibration."
To make the system robust to distribution shifts, the training process applies simulated input perturbations to the in-domain training data, inspired by distributionally robust optimization. This encourages the model to be more cautious about making predictions when faced with out-of-domain inputs.
The authors evaluate their approach on image classification and lung cancer risk assessment tasks, demonstrating improved selective calibration compared to baseline methods.
Critical Analysis
The paper presents a compelling approach to address the limitations of typical selective classification models. By rejecting examples with unreliable uncertainty estimates, the proposed method aims to achieve robust calibration - a desirable property not always guaranteed by existing selective models.
One potential limitation is the increased computational complexity of training the additional selector network. The authors do not provide detailed analysis of the training time or inference latency compared to simpler selective classification approaches.
Additionally, while the paper demonstrates the effectiveness of the method on specific benchmarks, further research is needed to understand its performance across a wider range of tasks and domains, especially in the face of more severe distribution shifts.
It would also be valuable to explore ways to interpret the selector network's decisions, as understanding why certain examples are rejected could provide useful insights for model development and deployment.
Overall, this research represents an interesting step forward in the field of selective classification, with the potential to produce more reliable and trustworthy machine learning systems.
Conclusion
This paper introduces a new approach to selective classification that addresses the issue of unreliable uncertainty estimates. By training a separate selector network to identify examples with uncertain uncertainties, the proposed method can make predictions with well-calibrated probabilities over the distribution of accepted examples.
The key innovation is the focus on robust calibration, which is achieved through a training strategy inspired by distributionally robust optimization. This allows the model to perform well even when faced with out-of-domain inputs, a common challenge in real-world deployment.
While the increased complexity of the model may be a consideration, the potential benefits of more reliable and trustworthy predictions make this a promising direction for future research in selective classification and uncertainty quantification for machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
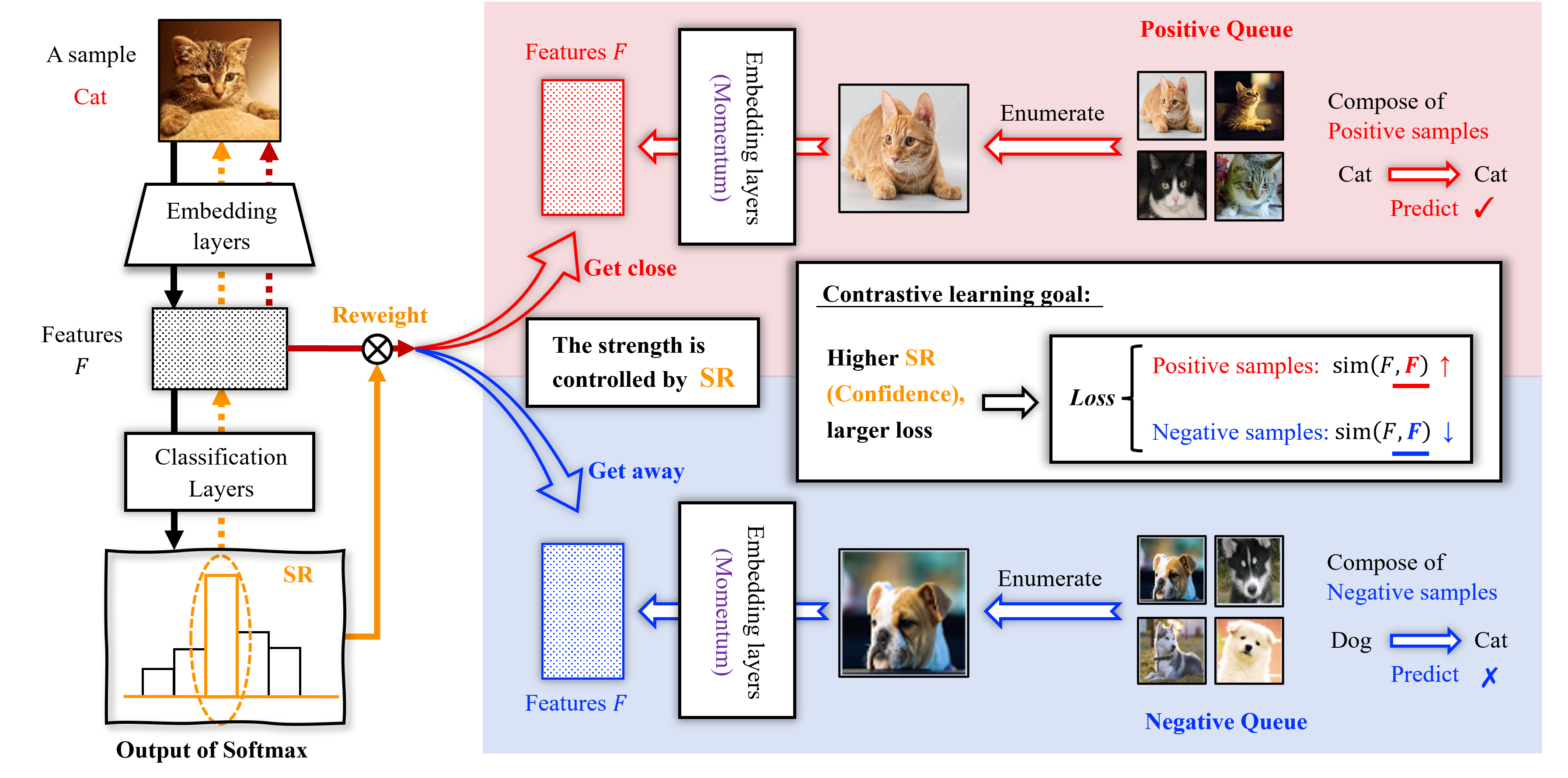
Confidence-aware Contrastive Learning for Selective Classification
Yu-Chang Wu, Shen-Huan Lyu, Haopu Shang, Xiangyu Wang, Chao Qian
0
0
Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.
6/10/2024

Conformalized Selective Regression
Anna Sokol, Nuno Moniz, Nitesh Chawla
0
0
Should prediction models always deliver a prediction? In the pursuit of maximum predictive performance, critical considerations of reliability and fairness are often overshadowed, particularly when it comes to the role of uncertainty. Selective regression, also known as the reject option, allows models to abstain from predictions in cases of considerable uncertainty. Initially proposed seven decades ago, approaches to selective regression have mostly focused on distribution-based proxies for measuring uncertainty, particularly conditional variance. However, this focus neglects the significant influence of model-specific biases on a model's performance. In this paper, we propose a novel approach to selective regression by leveraging conformal prediction, which provides grounded confidence measures for individual predictions based on model-specific biases. In addition, we propose a standardized evaluation framework to allow proper comparison of selective regression approaches. Via an extensive experimental approach, we demonstrate how our proposed approach, conformalized selective regression, demonstrates an advantage over multiple state-of-the-art baselines.
5/28/2024

Hierarchical Selective Classification
Shani Goren, Ido Galil, Ran El-Yaniv
0
0
Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces hierarchical selective classification, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as inference rules), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.
5/21/2024
🔮
Online Calibrated and Conformal Prediction Improves Bayesian Optimization
Shachi Deshpande, Charles Marx, Volodymyr Kuleshov
0
0
Accurate uncertainty estimates are important in sequential model-based decision-making tasks such as Bayesian optimization. However, these estimates can be imperfect if the data violates assumptions made by the model (e.g., Gaussianity). This paper studies which uncertainties are needed in model-based decision-making and in Bayesian optimization, and argues that uncertainties can benefit from calibration -- i.e., an 80% predictive interval should contain the true outcome 80% of the time. Maintaining calibration, however, can be challenging when the data is non-stationary and depends on our actions. We propose using simple algorithms based on online learning to provably maintain calibration on non-i.i.d. data, and we show how to integrate these algorithms in Bayesian optimization with minimal overhead. Empirically, we find that calibrated Bayesian optimization converges to better optima in fewer steps, and we demonstrate improved performance on standard benchmark functions and hyperparameter optimization tasks.
6/27/2024