Selective Classification Under Distribution Shifts
2405.05160
0
0
🏷️
Abstract
In selective classification (SC), a classifier abstains from making predictions that are likely to be wrong to avoid excessive errors. To deploy imperfect classifiers -- imperfect either due to intrinsic statistical noise of data or for robustness issue of the classifier or beyond -- in high-stakes scenarios, SC appears to be an attractive and necessary path to follow. Despite decades of research in SC, most previous SC methods still focus on the ideal statistical setting only, i.e., the data distribution at deployment is the same as that of training, although practical data can come from the wild. To bridge this gap, in this paper, we propose an SC framework that takes into account distribution shifts, termed generalized selective classification, that covers label-shifted (or out-of-distribution) and covariate-shifted samples, in addition to typical in-distribution samples, the first of its kind in the SC literature. We focus on non-training-based confidence-score functions for generalized SC on deep learning (DL) classifiers and propose two novel margin-based score functions. Through extensive analysis and experiments, we show that our proposed score functions are more effective and reliable than the existing ones for generalized SC on a variety of classification tasks and DL classifiers.
Create account to get full access
Overview
- Selective classification (SC) is a technique that allows classifiers to abstain from making predictions that are likely to be wrong, avoiding excessive errors.
- SC is important for deploying imperfect classifiers (due to data noise, robustness issues, or other factors) in high-stakes scenarios.
- However, most previous SC methods focus on the ideal statistical setting where the deployment data distribution is the same as the training data, which is often not the case in practice.
Plain English Explanation
Selective classification (SC) is a way for machine learning models to avoid making predictions that are likely to be wrong. This is important when using imperfect models, which can happen due to statistical noise in the data or issues with the robustness of the model itself. By allowing the model to abstain from making predictions in cases where it is not confident, SC can help deploy these imperfect models in high-stakes scenarios where accuracy is critical.
However, most previous SC methods have only worked well in the ideal scenario where the data the model sees during deployment is exactly the same as the data it was trained on. In reality, real-world data can be quite different from the training data, a phenomenon known as distribution shift. This paper proposes a new SC framework that can handle these more realistic distribution shifts, including label shifts (where the classes in the deployment data are different from the training data) and covariate shifts (where the input features are different).
Technical Explanation
This paper introduces a new framework for "generalized selective classification" that can handle distribution shifts in the deployment data, going beyond previous SC methods that assumed the training and deployment data were the same.
The key innovations are:
- Extending the SC problem formulation to cover not just the typical "in-distribution" samples, but also label-shifted (out-of-distribution) and covariate-shifted samples.
- Proposing two new margin-based confidence score functions that the model can use to determine when to abstain from making a prediction, which are shown to be more effective and reliable than existing methods.
The authors extensively analyze their proposed approach and demonstrate its advantages over prior work on a variety of deep learning classification tasks with distribution shifts.
Critical Analysis
The paper makes an important contribution by addressing the real-world issue of distribution shift, which is a major challenge for deploying machine learning models in practice. By extending selective classification to handle more realistic deployment scenarios, this work helps bridge the gap between the ideal statistical assumptions often made in research and the messy reality of practical data.
However, the paper does not explore some potential limitations or edge cases. For example, it is not clear how the proposed confidence score functions would perform under extreme distributional shifts, or how sensitive they are to hyperparameter choices. Additionally, the experiments are mostly on standard benchmark datasets, so further validation on real-world high-stakes applications would be valuable.
Overall, this is a well-executed piece of research that takes an important step forward, but there are still opportunities to further refine and expand the generalized selective classification framework to make it even more robust and useful in practice.
Conclusion
This paper presents a new framework for "generalized selective classification" that can handle distribution shifts in the deployment data, going beyond previous selective classification methods. By proposing novel confidence score functions and experimentally validating their effectiveness, the authors have made a valuable contribution to the field of machine learning deployment in real-world, high-stakes scenarios. While there are still opportunities to further improve and expand this work, this research represents an important step towards making imperfect classifiers more reliable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Hierarchical Selective Classification
Shani Goren, Ido Galil, Ran El-Yaniv
0
0
Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces hierarchical selective classification, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as inference rules), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.
5/21/2024
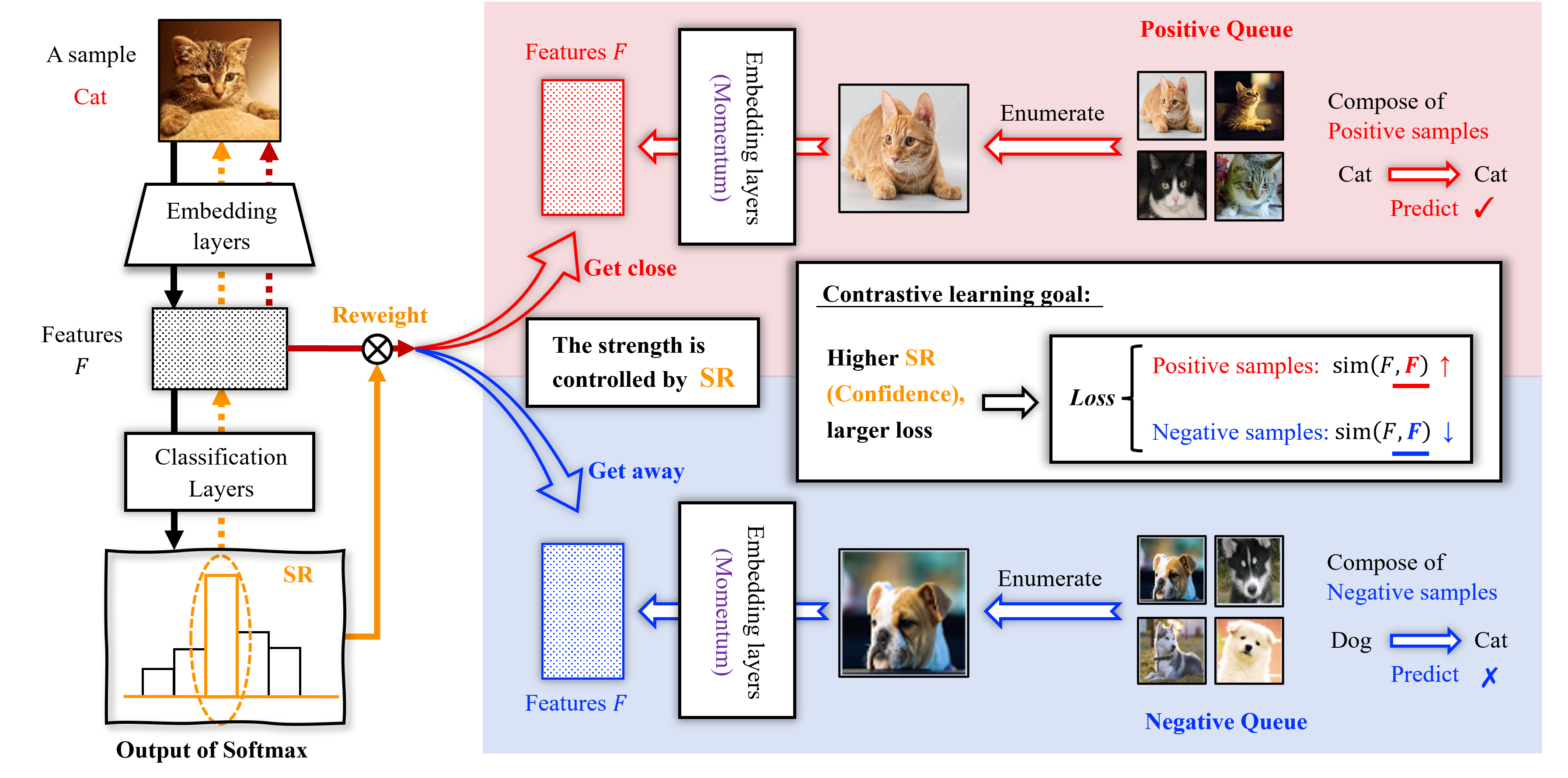
Confidence-aware Contrastive Learning for Selective Classification
Yu-Chang Wu, Shen-Huan Lyu, Haopu Shang, Xiangyu Wang, Chao Qian
0
0
Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.
6/10/2024
🏷️
Calibrated Selective Classification
Adam Fisch, Tommi Jaakkola, Regina Barzilay
0
0
Selective classification allows models to abstain from making predictions (e.g., say I don't know) when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with uncertain uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
6/24/2024

Supervised Algorithmic Fairness in Distribution Shifts: A Survey
Minglai Shao, Dong Li, Chen Zhao, Xintao Wu, Yujie Lin, Qin Tian
0
0
Supervised fairness-aware machine learning under distribution shifts is an emerging field that addresses the challenge of maintaining equitable and unbiased predictions when faced with changes in data distributions from source to target domains. In real-world applications, machine learning models are often trained on a specific dataset but deployed in environments where the data distribution may shift over time due to various factors. This shift can lead to unfair predictions, disproportionately affecting certain groups characterized by sensitive attributes, such as race and gender. In this survey, we provide a summary of various types of distribution shifts and comprehensively investigate existing methods based on these shifts, highlighting six commonly used approaches in the literature. Additionally, this survey lists publicly available datasets and evaluation metrics for empirical studies. We further explore the interconnection with related research fields, discuss the significant challenges, and identify potential directions for future studies.
5/7/2024