Hierarchical Selective Classification
2405.11533
0
0

Abstract
Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces hierarchical selective classification, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as inference rules), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.
Create account to get full access
Overview
- This paper introduces a novel approach called Hierarchical Selective Classification (HSC) for making accurate and reliable predictions in scenarios where the test distribution may differ from the training distribution.
- HSC leverages the hierarchical structure of the problem to make selective predictions, only outputting a label when the model is confident in its prediction.
- The authors demonstrate the effectiveness of HSC on various real-world tasks, including Hierarchical Insights Exploiting Structural Similarities for Reliable 3D Reconstruction, Diagonal Hierarchical Consistency Learning for Semi-Supervised Medical Image Segmentation, and Exploring Beyond Logits: Hierarchical Dynamic Labeling-Based Selective Prediction.
Plain English Explanation
In machine learning, there are often situations where the data used to train a model (the training distribution) is different from the data the model is applied to in the real world (the test distribution). This can lead to the model making inaccurate predictions.
The Hierarchical Selective Classification (HSC) approach introduced in this paper aims to address this problem. HSC takes advantage of the fact that many real-world problems have a hierarchical structure, meaning the classes are organized in a tree-like fashion. For example, in a task of classifying animals, the top-level classes might be "mammals", "birds", "reptiles", etc., with more specific sub-classes underneath.
HSC uses this hierarchical structure to make selective predictions, where the model only provides a prediction when it is confident in its output. If the model is uncertain, it will refrain from making a prediction and instead indicate that it doesn't have enough information to decide. This helps the model avoid making incorrect predictions, which can be especially important in high-stakes applications.
The authors show that HSC outperforms other selective classification methods on a variety of real-world tasks, including Selective Prediction for Semantic Segmentation Under Distribution Shifts, Selective Classification Under Distribution Shifts, and the examples mentioned in the overview.
Technical Explanation
The key innovation of Hierarchical Selective Classification (HSC) is its ability to leverage the hierarchical structure of the problem to make selective predictions. The authors introduce a set of hierarchical selective inference rules that guide the model's decision-making process.
These inference rules define how the model should navigate the class hierarchy to determine whether to make a prediction or abstain. The rules take into account the model's confidence in its predictions at each level of the hierarchy, as well as the potential consequences of making an incorrect prediction.
The authors formulate the HSC problem as an optimization task, where the goal is to maximize the number of correct predictions while minimizing the number of abstentions. They propose several algorithms to solve this optimization problem, including a greedy approach and a dynamic programming-based method.
The effectiveness of HSC is demonstrated on a variety of real-world tasks, including image classification, semantic segmentation, and 3D reconstruction. The results show that HSC can significantly outperform traditional selective classification methods, especially in scenarios with distribution shifts between the training and test data.
Critical Analysis
The authors provide a thorough analysis of the limitations and potential issues with HSC. One key concern is the computational complexity of the optimization algorithms, which can be challenging for large-scale problems with deep hierarchies. The authors address this by proposing efficient approximation methods, but further research may be needed to improve the scalability of HSC.
Another potential issue is the reliance on accurate hierarchical structure information, which may not always be available or easy to obtain. The authors suggest that HSC could be extended to handle cases where the hierarchy is not fully known or is learned from data, but more work is needed in this direction.
Additionally, the authors acknowledge that the performance of HSC is heavily dependent on the quality of the underlying machine learning models used for the task. If the base models are not well-calibrated or fail to capture the relevant features, the selective inference rules may not be effective.
Overall, the Hierarchical Selective Classification approach is a promising and innovative technique for improving the reliability of machine learning models in the face of distribution shifts. The authors have provided a solid theoretical foundation and demonstrated the practical benefits of HSC on a range of applications. However, further research is needed to address the challenges and limitations identified in the paper.
Conclusion
The Hierarchical Selective Classification (HSC) approach introduced in this paper offers a novel way to improve the reliability and accuracy of machine learning models, particularly in scenarios where the test distribution differs from the training distribution. By leveraging the hierarchical structure of the problem and selectively making predictions, HSC can avoid making incorrect predictions and maintain high performance even in the presence of distribution shifts.
The authors have demonstrated the effectiveness of HSC on a variety of real-world tasks, showcasing its potential to have a significant impact in fields where reliable and trustworthy predictions are crucial, such as medical diagnosis, autonomous systems, and high-stakes decision-making. While there are still some challenges to address, the insights and techniques presented in this paper represent an important step forward in the development of more robust and reliable machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
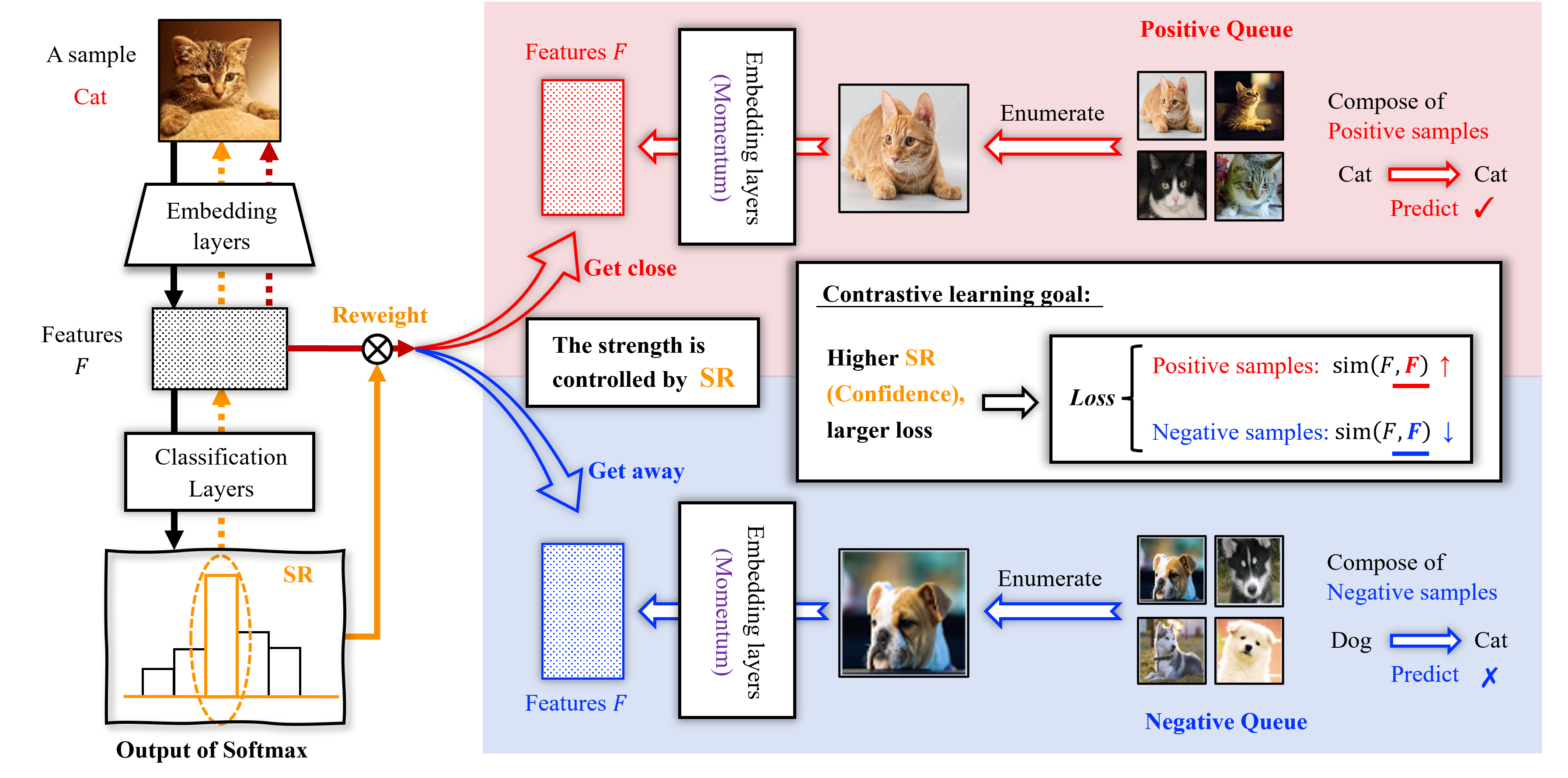
Confidence-aware Contrastive Learning for Selective Classification
Yu-Chang Wu, Shen-Huan Lyu, Haopu Shang, Xiangyu Wang, Chao Qian
0
0
Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.
6/10/2024
🏷️
Selective Classification Under Distribution Shifts
Hengyue Liang, Le Peng, Ju Sun
0
0
In selective classification (SC), a classifier abstains from making predictions that are likely to be wrong to avoid excessive errors. To deploy imperfect classifiers -- imperfect either due to intrinsic statistical noise of data or for robustness issue of the classifier or beyond -- in high-stakes scenarios, SC appears to be an attractive and necessary path to follow. Despite decades of research in SC, most previous SC methods still focus on the ideal statistical setting only, i.e., the data distribution at deployment is the same as that of training, although practical data can come from the wild. To bridge this gap, in this paper, we propose an SC framework that takes into account distribution shifts, termed generalized selective classification, that covers label-shifted (or out-of-distribution) and covariate-shifted samples, in addition to typical in-distribution samples, the first of its kind in the SC literature. We focus on non-training-based confidence-score functions for generalized SC on deep learning (DL) classifiers and propose two novel margin-based score functions. Through extensive analysis and experiments, we show that our proposed score functions are more effective and reliable than the existing ones for generalized SC on a variety of classification tasks and DL classifiers.
5/9/2024
🏷️
Calibrated Selective Classification
Adam Fisch, Tommi Jaakkola, Regina Barzilay
0
0
Selective classification allows models to abstain from making predictions (e.g., say I don't know) when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with uncertain uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
6/24/2024

Learning Hierarchical Semantic Classification by Grounding on Consistent Image Segmentations
Seulki Park, Youren Zhang, Stella X. Yu, Sara Beery, Jonathan Huang
0
0
Hierarchical semantic classification requires the prediction of a taxonomy tree instead of a single flat level of the tree, where both accuracies at individual levels and consistency across levels matter. We can train classifiers for individual levels, which has accuracy but not consistency, or we can train only the finest level classification and infer higher levels, which has consistency but not accuracy. Our key insight is that hierarchical recognition should not be treated as multi-task classification, as each level is essentially a different task and they would have to compromise with each other, but be grounded on image segmentations that are consistent across semantic granularities. Consistency can in fact improve accuracy. We build upon recent work on learning hierarchical segmentation for flat-level recognition, and extend it to hierarchical recognition. It naturally captures the intuition that fine-grained recognition requires fine image segmentation whereas coarse-grained recognition requires coarse segmentation; they can all be integrated into one recognition model that drives fine-to-coarse internal visual parsing.Additionally, we introduce a Tree-path KL Divergence loss to enforce consistent accurate predictions across levels. Our extensive experimentation and analysis demonstrate our significant gains on predicting an accurate and consistent taxonomy tree.
6/18/2024