Calibrating Transformers via Sparse Gaussian Processes

0
🔎
Sign in to get full access
Overview
- Transformers have achieved great success in various prediction tasks, but ensuring their uncertainty is well-calibrated remains a challenge.
- The paper proposes Sparse Gaussian Process attention (SGPA), a method that performs Bayesian inference in the output space of multi-head attention blocks to calibrate the uncertainty of Transformer models.
- SGPA-based Transformers achieve competitive predictive accuracy while improving in-distribution calibration and out-of-distribution robustness and detection.
Plain English Explanation
Transformer models have become incredibly powerful at tasks like natural language processing, speech recognition, and computer vision. However, as these models are used in more safety-critical applications, it's important that they can provide reliable estimates of their own uncertainty.
The key idea behind the SGPA method is to replace the standard "dot-product" operation in Transformer attention with a more principled "kernel" function. This allows the model to perform Bayesian inference, which means it can quantify how confident it is in its predictions. The researchers use a technique called "sparse Gaussian processes" to make this Bayesian inference computationally efficient.
The result is that SGPA-based Transformers not only maintain strong predictive performance, but also provide much better calibrated uncertainty estimates. This means the model is better able to identify when it's unsure about its predictions, which is crucial for safety-critical applications like self-driving cars or medical diagnosis. By improving both accuracy and uncertainty quantification, SGPA helps make Transformer models more reliable and trustworthy.
Technical Explanation
The paper proposes Sparse Gaussian Process attention (SGPA), a novel approach to calibrate the uncertainty of Transformer models. SGPA replaces the standard scaled dot-product operation in the multi-head attention (MHA) blocks of Transformers with a valid symmetric kernel function.
This kernel-based attention mechanism allows SGPA to perform Bayesian inference directly in the output space of the MHA blocks. The researchers use sparse Gaussian process (SGP) techniques to approximate the posterior processes of the MHA outputs, enabling efficient uncertainty quantification.
Experiments on a range of prediction tasks across text, images, and graphs demonstrate that SGPA-based Transformers achieve competitive predictive performance while significantly improving both in-distribution calibration and out-of-distribution robustness and detection. This is a crucial advancement, as ensuring well-calibrated uncertainty is essential for deploying Transformer models in safety-critical applications.
Critical Analysis
The paper provides a compelling approach to addressing the challenge of uncertainty quantification in Transformer models. By reformulating the attention mechanism using a kernel function and sparse Gaussian processes, the authors have developed a principled way to estimate model uncertainty.
One potential limitation is the computational overhead introduced by the SGP approximation, which may impact the inference speed of SGPA-based Transformers. Additionally, the paper does not explore the scalability of the SGPA approach to very large Transformer models or datasets.
Further research could investigate ways to strike a better balance between the uncertainty quantification benefits of SGPA and its computational efficiency. Exploring alternative approximation techniques or ways to selectively apply the SGPA module within a larger Transformer architecture may yield promising avenues for improvement.
Overall, the SGPA method represents an important step forward in making Transformer models more reliable and trustworthy, particularly for safety-critical applications. The critical analysis encourages readers to think carefully about the trade-offs and consider how the ideas could be further refined and extended.
Conclusion
The Sparse Gaussian Process attention (SGPA) method proposed in this paper is a significant advancement in ensuring well-calibrated uncertainty estimation for Transformer models. By replacing the standard attention mechanism with a kernel-based approach and leveraging sparse Gaussian processes, SGPA-based Transformers achieve strong predictive performance while noticeably improving in-distribution calibration and out-of-distribution robustness.
This is a crucial development, as the widespread adoption of Transformers in safety-critical domains, such as self-driving cars and medical diagnosis, requires reliable uncertainty quantification. The SGPA approach represents an important step towards making Transformer models more trustworthy and suitable for real-world applications where the ability to identify and communicate uncertainty is paramount.
While the paper highlights some potential areas for further optimization, the core ideas behind SGPA demonstrate the value of rethinking fundamental Transformer components to address emerging challenges in the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Calibrating Transformers via Sparse Gaussian Processes
Wenlong Chen, Yingzhen Li
Transformer models have achieved profound success in prediction tasks in a wide range of applications in natural language processing, speech recognition and computer vision. Extending Transformer's success to safety-critical domains requires calibrated uncertainty estimation which remains under-explored. To address this, we propose Sparse Gaussian Process attention (SGPA), which performs Bayesian inference directly in the output space of multi-head attention blocks (MHAs) in transformer to calibrate its uncertainty. It replaces the scaled dot-product operation with a valid symmetric kernel and uses sparse Gaussian processes (SGP) techniques to approximate the posterior processes of MHA outputs. Empirically, on a suite of prediction tasks on text, images and graphs, SGPA-based Transformers achieve competitive predictive accuracy, while noticeably improving both in-distribution calibration and out-of-distribution robustness and detection.
Read more7/10/2024

0
Self-Attention through Kernel-Eigen Pair Sparse Variational Gaussian Processes
Yingyi Chen, Qinghua Tao, Francesco Tonin, Johan A. K. Suykens
While the great capability of Transformers significantly boosts prediction accuracy, it could also yield overconfident predictions and require calibrated uncertainty estimation, which can be commonly tackled by Gaussian processes (GPs). Existing works apply GPs with symmetric kernels under variational inference to the attention kernel; however, omitting the fact that attention kernels are in essence asymmetric. Moreover, the complexity of deriving the GP posteriors remains high for large-scale data. In this work, we propose Kernel-Eigen Pair Sparse Variational Gaussian Processes (KEP-SVGP) for building uncertainty-aware self-attention where the asymmetry of attention kernels is tackled by Kernel SVD (KSVD) and a reduced complexity is acquired. Through KEP-SVGP, i) the SVGP pair induced by the two sets of singular vectors from KSVD w.r.t. the attention kernel fully characterizes the asymmetry; ii) using only a small set of adjoint eigenfunctions from KSVD, the derivation of SVGP posteriors can be based on the inversion of a diagonal matrix containing singular values, contributing to a reduction in time complexity; iii) an evidence lower bound is derived so that variational parameters and network weights can be optimized with it. Experiments verify our excellent performances and efficiency on in-distribution, distribution-shift and out-of-distribution benchmarks.
Read more5/29/2024

0
Diffusion Transformer Captures Spatial-Temporal Dependencies: A Theory for Gaussian Process Data
Hengyu Fu, Zehao Dou, Jiawei Guo, Mengdi Wang, Minshuo Chen
Diffusion Transformer, the backbone of Sora for video generation, successfully scales the capacity of diffusion models, pioneering new avenues for high-fidelity sequential data generation. Unlike static data such as images, sequential data consists of consecutive data frames indexed by time, exhibiting rich spatial and temporal dependencies. These dependencies represent the underlying dynamic model and are critical to validate the generated data. In this paper, we make the first theoretical step towards bridging diffusion transformers for capturing spatial-temporal dependencies. Specifically, we establish score approximation and distribution estimation guarantees of diffusion transformers for learning Gaussian process data with covariance functions of various decay patterns. We highlight how the spatial-temporal dependencies are captured and affect learning efficiency. Our study proposes a novel transformer approximation theory, where the transformer acts to unroll an algorithm. We support our theoretical results by numerical experiments, providing strong evidence that spatial-temporal dependencies are captured within attention layers, aligning with our approximation theory.
Read more7/24/2024
0
Graph Convolutions Enrich the Self-Attention in Transformers!
Jeongwhan Choi, Hyowon Wi, Jayoung Kim, Yehjin Shin, Kookjin Lee, Nathaniel Trask, Noseong Park
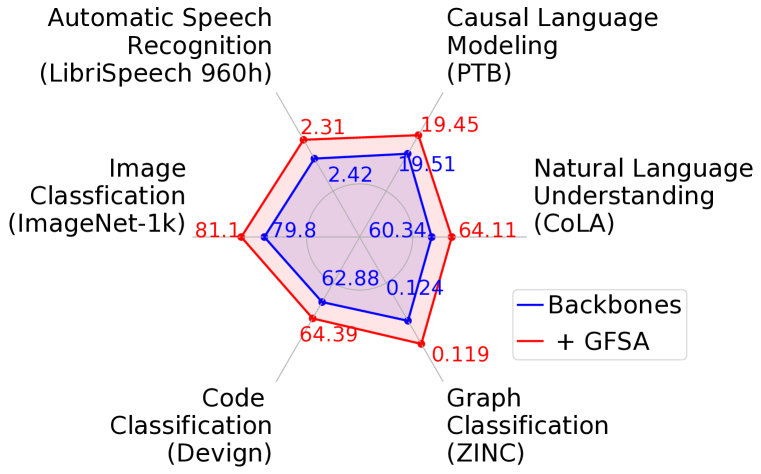
Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose a graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph regression, speech recognition, and code classification.
Read more6/3/2024