Calibration of Network Confidence for Unsupervised Domain Adaptation Using Estimated Accuracy

0

Sign in to get full access
Overview
- This paper proposes a method for calibrating the confidence of machine learning models in unsupervised domain adaptation tasks.
- The goal is to improve the reliability of model predictions when applied to new, unlabeled data domains.
- The key idea is to use estimated model accuracy on the target domain to recalibrate the model's confidence scores.
Plain English Explanation
In machine learning, models are often trained on one dataset (the "source" domain) and then applied to a different dataset (the "target" domain). This can lead to a domain shift where the model's predictions become less reliable on the new data.
To address this, the researchers developed a technique to calibrate the model's confidence scores based on an estimated accuracy on the target domain. This helps the model provide more accurate and trustworthy predictions when used on the new, unlabeled data.
The main steps are:
- Train the model on the source domain data.
- Estimate the model's accuracy on the target domain using an unsupervised domain adaptation method.
- Use the estimated accuracy to recalibrate the model's confidence scores so they better reflect the true reliability of the predictions.
By doing this, the model can provide better-calibrated confidence estimates when applied to the new target domain, which is important for many real-world applications where the model's reliability needs to be well-understood.
Technical Explanation
The paper starts by discussing the problem of domain shift in machine learning, where models trained on one dataset may perform poorly when applied to a different dataset. This is a common challenge in unsupervised domain adaptation tasks, where the target domain lacks labeled data.
To address this, the researchers propose a novel method called Confidence Calibration for Unsupervised Domain Adaptation (CC-UDA). The key idea is to leverage an estimated accuracy on the target domain to recalibrate the model's confidence scores.
The CC-UDA method works as follows:
- Train a base classifier on the source domain data using standard supervised learning techniques.
- Use an unsupervised domain adaptation algorithm, such as Importance Weighted Group Accuracy Estimation (IW-GAE), to estimate the model's accuracy on the target domain.
- Recalibrate the model's confidence scores using the estimated target domain accuracy, ensuring the confidence estimates better reflect the true reliability of the predictions.
The researchers evaluated CC-UDA on several standard unsupervised domain adaptation benchmarks and found that it outperformed existing confidence calibration methods, leading to more reliable model predictions on the target domain.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed CC-UDA method, including comparisons to several baseline approaches. The authors acknowledge some limitations, such as the reliance on the accuracy estimation method (IW-GAE) and the potential for the calibration process to introduce additional bias.
One potential concern is the generalizability of the approach, as the performance may be sensitive to the specific characteristics of the source and target domains. The researchers could have explored the method's robustness to different types of domain shifts or data distributions.
Additionally, the paper does not discuss potential societal impacts or ethical considerations, which could be important given the widespread use of machine learning models in decision-making contexts.
Conclusion
This paper introduces a novel technique for confidence calibration in unsupervised domain adaptation, which helps improve the reliability of model predictions when applied to new, unlabeled data domains. By leveraging an estimated target domain accuracy, the CC-UDA method can recalibrate the model's confidence scores to better reflect the true reliability of the predictions.
The proposed approach demonstrates promising results on standard benchmarks and could have significant practical applications in a wide range of domains, such as medical imaging, autonomous driving, and financial risk assessment, where model reliability is crucial. Further research could explore the method's robustness and consider potential societal implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibration of Network Confidence for Unsupervised Domain Adaptation Using Estimated Accuracy
Coby Penso, Jacob Goldberger
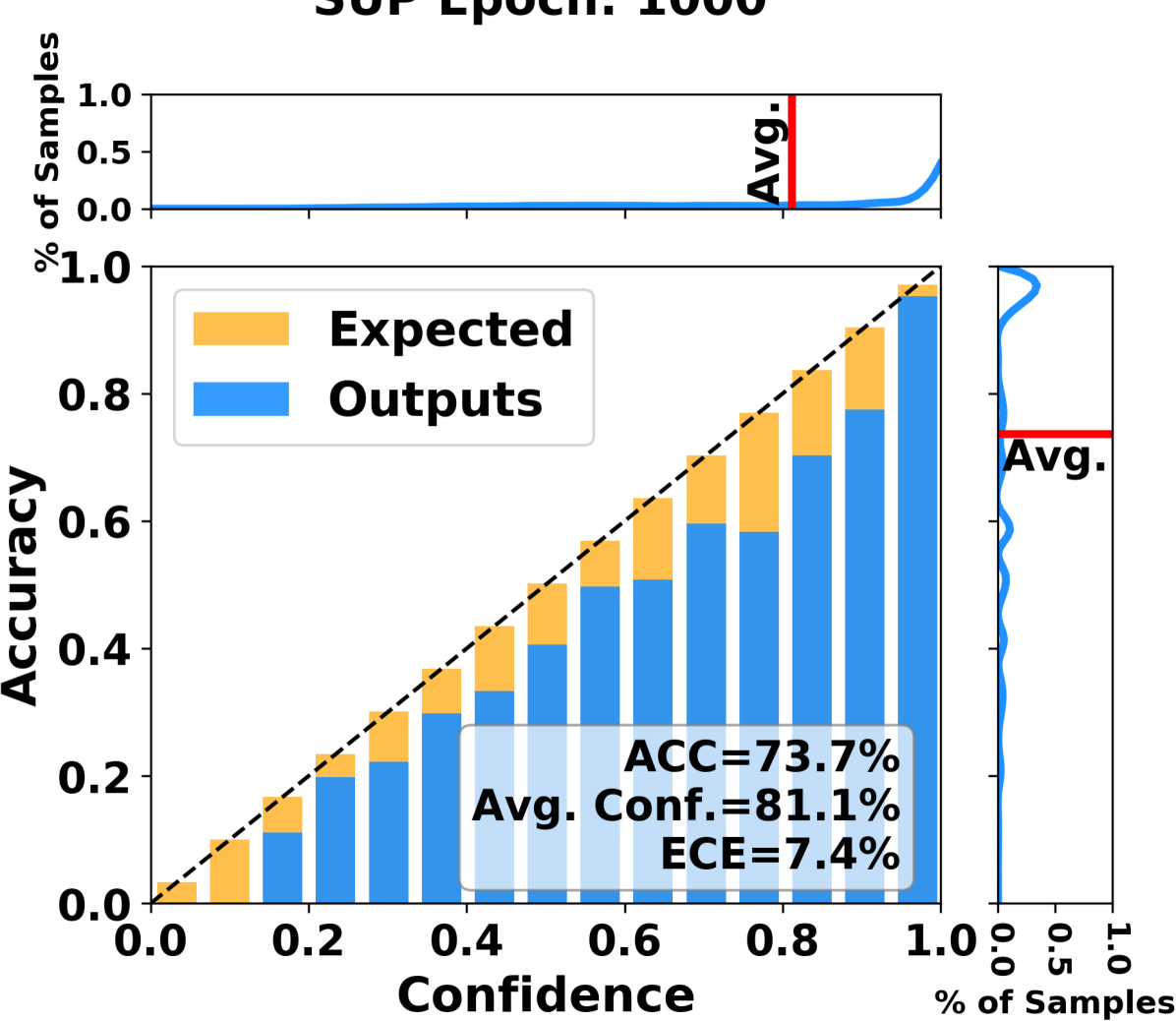
This study addresses the problem of calibrating network confidence while adapting a model that was originally trained on a source domain to a target domain using unlabeled samples from the target domain. The absence of labels from the target domain makes it impossible to directly calibrate the adapted network on the target domain. To tackle this challenge, we introduce a calibration procedure that relies on estimating the network's accuracy on the target domain. The network accuracy is first computed on the labeled source data and then is modified to represent the actual accuracy of the model on the target domain. The proposed algorithm calibrates the prediction confidence directly in the target domain by minimizing the disparity between the estimated accuracy and the computed confidence. The experimental results show that our method significantly outperforms existing methods, which rely on importance weighting, across several standard datasets.
Read more9/9/2024
0
Towards Calibrated Deep Clustering Network
Yuheng Jia, Jianhong Cheng, Hui Liu, Junhui Hou
Deep clustering has exhibited remarkable performance; however, the over-confidence problem, i.e., the estimated confidence for a sample belonging to a particular cluster greatly exceeds its actual prediction accuracy, has been overlooked in prior research. To tackle this critical issue, we pioneer the development of a calibrated deep clustering framework. Specifically, we propose a novel dual-head (calibration head and clustering head) deep clustering model that can effectively calibrate the estimated confidence and the actual accuracy. The calibration head adjusts the overconfident predictions of the clustering head, generating prediction confidence that match the model learning status. Then, the clustering head dynamically select reliable high-confidence samples estimated by the calibration head for pseudo-label self-training. Additionally, we introduce an effective network initialization strategy that enhances both training speed and network robustness. The effectiveness of the proposed calibration approach and initialization strategy are both endorsed with solid theoretical guarantees. Extensive experiments demonstrate the proposed calibrated deep clustering model not only surpasses state-of-the-art deep clustering methods by 10 times in terms of expected calibration error but also significantly outperforms them in terms of clustering accuracy.
Read more6/4/2024
🎯
0
IW-GAE: Importance Weighted Group Accuracy Estimation for Improved Calibration and Model Selection in Unsupervised Domain Adaptation
Taejong Joo, Diego Klabjan
Distribution shifts pose significant challenges for model calibration and model selection tasks in the unsupervised domain adaptation problem -- a scenario where the goal is to perform well in a distribution shifted domain without labels. In this work, we tackle difficulties coming from distribution shifts by developing a novel importance weighted group accuracy estimator. Specifically, we present a new perspective of addressing the model calibration and model selection tasks by estimating the group accuracy. Then, we formulate an optimization problem for finding an importance weight that leads to an accurate group accuracy estimation with theoretical analyses. Our extensive experiments show that our approach improves state-of-the-art performances by 22% in the model calibration task and 14% in the model selection task.
Read more7/18/2024

0
Source-Free Domain-Invariant Performance Prediction
Ekaterina Khramtsova, Mahsa Baktashmotlagh, Guido Zuccon, Xi Wang, Mathieu Salzmann
Accurately estimating model performance poses a significant challenge, particularly in scenarios where the source and target domains follow different data distributions. Most existing performance prediction methods heavily rely on the source data in their estimation process, limiting their applicability in a more realistic setting where only the trained model is accessible. The few methods that do not require source data exhibit considerably inferior performance. In this work, we propose a source-free approach centred on uncertainty-based estimation, using a generative model for calibration in the absence of source data. We establish connections between our approach for unsupervised calibration and temperature scaling. We then employ a gradient-based strategy to evaluate the correctness of the calibrated predictions. Our experiments on benchmark object recognition datasets reveal that existing source-based methods fall short with limited source sample availability. Furthermore, our approach significantly outperforms the current state-of-the-art source-free and source-based methods, affirming its effectiveness in domain-invariant performance estimation.
Read more8/7/2024