Towards Calibrated Deep Clustering Network

0
Sign in to get full access
Overview
- This paper proposes a deep clustering network that aims to produce well-calibrated probability estimates for each cluster assignment.
- The key ideas include using a temperature-scaled softmax activation, a calibration loss, and a novel training strategy to improve the calibration of the model's cluster probability outputs.
- The proposed method is evaluated on several real-world datasets and demonstrates improvements in clustering performance and probability calibration compared to baseline deep clustering approaches.
Plain English Explanation
Deep learning models are often used for clustering, which groups similar data points together. However, these models can sometimes be overconfident in their cluster assignments, meaning they provide probability estimates that are not well-aligned with the true likelihood of each assignment being correct.
The researchers in this paper introduce a new deep clustering network design that is focused on improving the calibration of the model's cluster probability outputs. This means making the model's probability estimates more accurately reflect the true likelihood of each cluster assignment.
The key innovations include:
- Using a "temperature-scaled" softmax activation to adjust the sharpness of the probability estimates.
- Adding a "calibration loss" term to the training objective to directly encourage well-calibrated probabilities.
- Developing a novel training strategy that alternates between optimizing the clustering performance and the calibration.
By incorporating these techniques, the proposed deep clustering network is able to produce more reliable and trustworthy probability estimates for its cluster assignments, which can be important for real-world applications where uncertainty quantification is crucial.
The method is evaluated on several benchmark datasets and shows improvements in both clustering accuracy and probability calibration compared to baseline deep clustering approaches.
Technical Explanation
The key technical contributions of this paper are:
-
Temperature-Scaled Softmax: The researchers use a temperature-scaled softmax activation function in the final layer of the deep clustering network. This allows the model to adjust the "sharpness" of the probability estimates, which can improve calibration.
-
Calibration Loss: In addition to the standard clustering loss, the researchers introduce a calibration loss term that encourages the model's probability outputs to match the empirical cluster assignment frequencies. This helps align the model's confidence with the true likelihood of each cluster assignment.
-
Alternating Training Strategy: The training procedure alternates between optimizing the clustering performance (using the standard clustering loss) and optimizing the calibration (using the calibration loss). This novel training strategy helps the model learn well-calibrated probabilities without sacrificing clustering accuracy.
The proposed deep clustering network is evaluated on several real-world datasets, including image recognition and text classification tasks. The results demonstrate that the method outperforms baseline deep clustering approaches in terms of both clustering performance and probability calibration.
Critical Analysis
The paper presents a compelling approach to improving the calibration of deep clustering models, which is an important but often overlooked aspect of these systems. The proposed techniques, including the temperature-scaled softmax and the calibration loss, seem well-justified and effective based on the experimental results.
However, the paper does not discuss the potential limitations or caveats of the method. For example, it is unclear how the approach would scale to very large-scale clustering problems or how sensitive the performance is to the hyperparameter settings. Additionally, the paper does not provide much insight into the underlying reasons why the proposed method is able to achieve better calibration compared to the baselines.
Further research could explore the theoretical properties of the calibration loss and the alternating training strategy, as well as investigate the method's robustness and generalizability to a wider range of clustering scenarios. Incorporating the proposed techniques into other deep learning models, such as generative models or reinforcement learning agents, could also be an interesting direction for future work.
Conclusion
This paper introduces a novel deep clustering network design that focuses on improving the calibration of the model's cluster probability outputs. By incorporating a temperature-scaled softmax, a calibration loss, and an alternating training strategy, the proposed method is able to produce more reliable and trustworthy probability estimates for its cluster assignments.
The experimental results demonstrate the effectiveness of the approach, with the deep clustering network outperforming baseline methods in terms of both clustering accuracy and probability calibration. This work represents an important step towards developing deep learning models that can provide meaningful uncertainty quantification, which is crucial for many real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Calibrated Deep Clustering Network
Yuheng Jia, Jianhong Cheng, Hui Liu, Junhui Hou
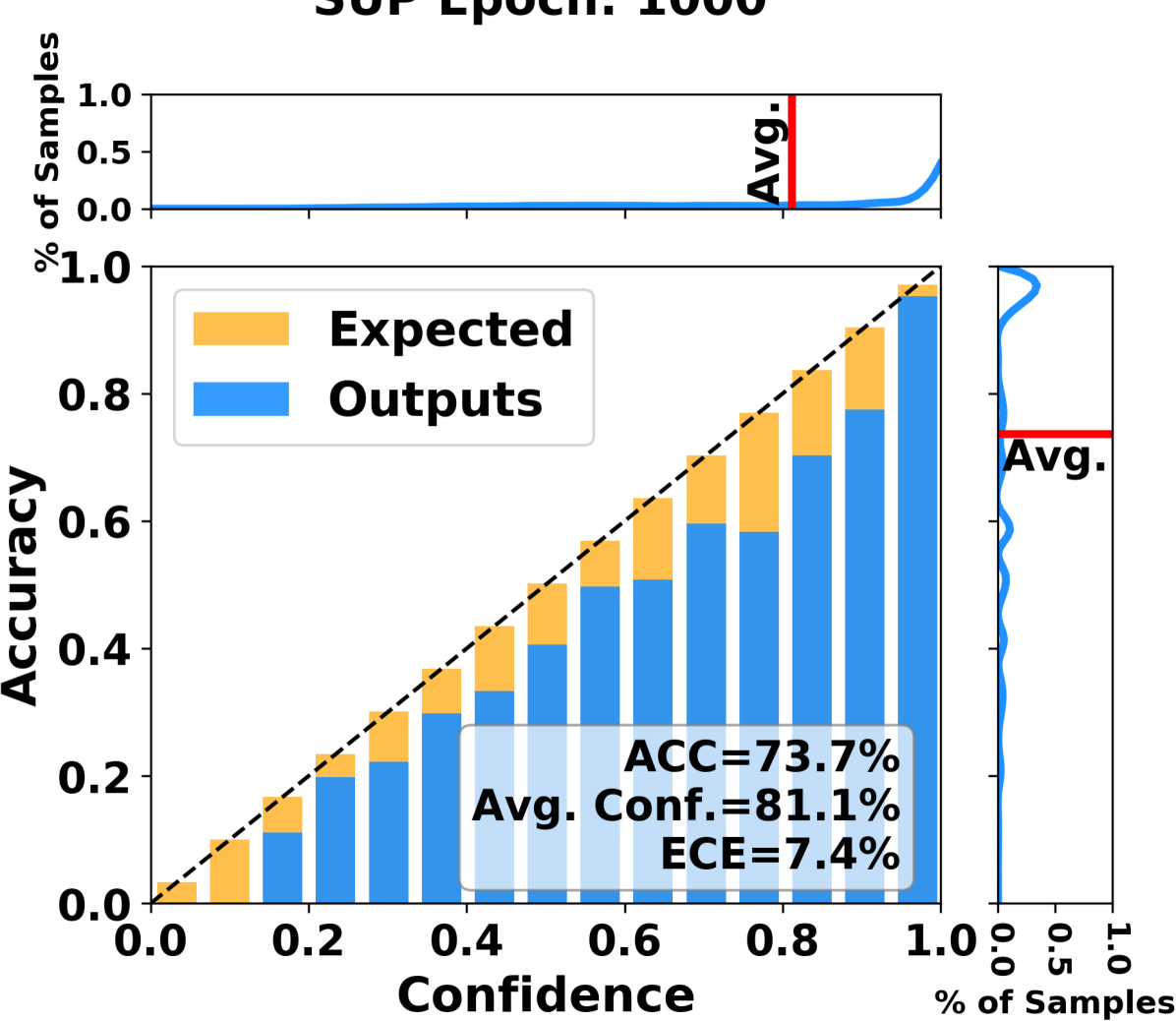
Deep clustering has exhibited remarkable performance; however, the over-confidence problem, i.e., the estimated confidence for a sample belonging to a particular cluster greatly exceeds its actual prediction accuracy, has been overlooked in prior research. To tackle this critical issue, we pioneer the development of a calibrated deep clustering framework. Specifically, we propose a novel dual-head (calibration head and clustering head) deep clustering model that can effectively calibrate the estimated confidence and the actual accuracy. The calibration head adjusts the overconfident predictions of the clustering head, generating prediction confidence that match the model learning status. Then, the clustering head dynamically select reliable high-confidence samples estimated by the calibration head for pseudo-label self-training. Additionally, we introduce an effective network initialization strategy that enhances both training speed and network robustness. The effectiveness of the proposed calibration approach and initialization strategy are both endorsed with solid theoretical guarantees. Extensive experiments demonstrate the proposed calibrated deep clustering model not only surpasses state-of-the-art deep clustering methods by 10 times in terms of expected calibration error but also significantly outperforms them in terms of clustering accuracy.
Read more6/4/2024

0
Calibration of Network Confidence for Unsupervised Domain Adaptation Using Estimated Accuracy
Coby Penso, Jacob Goldberger
This study addresses the problem of calibrating network confidence while adapting a model that was originally trained on a source domain to a target domain using unlabeled samples from the target domain. The absence of labels from the target domain makes it impossible to directly calibrate the adapted network on the target domain. To tackle this challenge, we introduce a calibration procedure that relies on estimating the network's accuracy on the target domain. The network accuracy is first computed on the labeled source data and then is modified to represent the actual accuracy of the model on the target domain. The proposed algorithm calibrates the prediction confidence directly in the target domain by minimizing the disparity between the estimated accuracy and the computed confidence. The experimental results show that our method significantly outperforms existing methods, which rely on importance weighting, across several standard datasets.
Read more9/9/2024
🤿
0
Calibration in Deep Learning: A Survey of the State-of-the-Art
Cheng Wang
Calibrating deep neural models plays an important role in building reliable, robust AI systems in safety-critical applications. Recent work has shown that modern neural networks that possess high predictive capability are poorly calibrated and produce unreliable model predictions. Though deep learning models achieve remarkable performance on various benchmarks, the study of model calibration and reliability is relatively underexplored. Ideal deep models should have not only high predictive performance but also be well calibrated. There have been some recent advances in calibrating deep models. In this survey, we review the state-of-the-art calibration methods and their principles for performing model calibration. First, we start with the definition of model calibration and explain the root causes of model miscalibration. Then we introduce the key metrics that can measure this aspect. It is followed by a summary of calibration methods that we roughly classify into four categories: post-hoc calibration, regularization methods, uncertainty estimation, and composition methods. We also cover recent advancements in calibrating large models, particularly large language models (LLMs). Finally, we discuss some open issues, challenges, and potential directions.
Read more5/13/2024

0
Cautious Calibration in Binary Classification
Mari-Liis Allikivi, Joonas Jarve, Meelis Kull
Being cautious is crucial for enhancing the trustworthiness of machine learning systems integrated into decision-making pipelines. Although calibrated probabilities help in optimal decision-making, perfect calibration remains unattainable, leading to estimates that fluctuate between under- and overconfidence. This becomes a critical issue in high-risk scenarios, where even occasional overestimation can lead to extreme expected costs. In these scenarios, it is important for each predicted probability to lean towards underconfidence, rather than just achieving an average balance. In this study, we introduce the novel concept of cautious calibration in binary classification. This approach aims to produce probability estimates that are intentionally underconfident for each predicted probability. We highlight the importance of this approach in a high-risk scenario and propose a theoretically grounded method for learning cautious calibration maps. Through experiments, we explore and compare our method to various approaches, including methods originally not devised for cautious calibration but applicable in this context. We show that our approach is the most consistent in providing cautious estimates. Our work establishes a strong baseline for further developments in this novel framework.
Read more8/12/2024