CaLM: Contrasting Large and Small Language Models to Verify Grounded Generation
2406.05365
0
0

Abstract
Grounded generation aims to equip language models (LMs) with the ability to produce more credible and accountable responses by accurately citing verifiable sources. However, existing methods, by either feeding LMs with raw or preprocessed materials, remain prone to errors. To address this, we introduce CaLM, a novel verification framework. CaLM leverages the insight that a robust grounded response should be consistent with information derived solely from its cited sources. Our framework empowers smaller LMs, which rely less on parametric memory and excel at processing relevant information given a query, to validate the output of larger LMs. Larger LM responses that closely align with the smaller LMs' output, which relies exclusively on cited documents, are verified. Responses showing discrepancies are iteratively refined through a feedback loop. Experiments on three open-domain question-answering datasets demonstrate significant performance gains of 1.5% to 7% absolute average without any required model fine-tuning.
Create account to get full access
Overview
- This paper explores the use of large and small language models to verify the truthfulness and groundedness of generated text.
- The researchers contrast the capabilities of different-sized models to understand how language model size affects the ability to generate grounded and truthful content.
- The paper investigates the potential for small language models to assist large language models in verifying the reliability of their own outputs.
Plain English Explanation
The paper examines how the size of language models, which are AI systems trained on large amounts of text data, can impact their ability to generate truthful and well-grounded content. Large language models are very powerful and can produce highly fluent text, but they may struggle to ensure the content is fully factual and consistent with the real world.
In contrast, smaller language models have more limited capabilities but may be better able to identify when the outputs of larger models are inaccurate or lack appropriate grounding in reality. The researchers explore whether these smaller models can be used to help larger models verify the truthfulness and groundedness of their own generated text.
By understanding the tradeoffs between large and small language models, the researchers aim to develop techniques that can [improve the reliability and linguistic calibration of long-form text generation.
Technical Explanation
The paper contrasts the capabilities of large and small language models to investigate how model size affects the ability to generate grounded and truthful content. The researchers design experiments to evaluate the performance of different-sized models on tasks that require reasoning about factual information and generating text that is consistent with the real world.
The experiments include prompting the models to answer questions that test their knowledge and to generate longer passages of text on a variety of topics. The researchers analyze the outputs to assess the models' understanding of the prompts, their factual accuracy, and the overall coherence and grounding of the generated text.
The results suggest that while large language models excel at producing fluent and coherent text, they can sometimes generate content that is factually inaccurate or lacks appropriate grounding. In contrast, smaller models may be more adept at identifying when the outputs of larger models are unreliable or implausible.
Based on these findings, the paper explores the potential for using smaller models to assist larger models in verifying the truthfulness and groundedness of their own outputs. This could help improve the overall reliability and linguistic calibration of long-form text generation.
Critical Analysis
The paper provides a thoughtful exploration of the trade-offs between large and small language models, but it also acknowledges several limitations and areas for further research. For example, the experiments are conducted on a relatively small set of prompts and topics, so the generalizability of the findings may be limited.
Additionally, the paper does not delve deeply into the specific architectural or training differences between the large and small models that may contribute to their divergent performance characteristics. Further research could investigate these underlying factors in more detail.
The researchers also note that their proposed approach of using smaller models to assist larger models in verifying output reliability is still a nascent idea that requires more extensive testing and development. Practical implementation challenges, such as integrating the two model types effectively, would need to be addressed.
Overall, the paper offers valuable insights into the nuanced interplay between model size, factual grounding, and text generation capabilities. However, continued research and experimentation will be necessary to fully realize the potential of this approach for improving the reliability and trustworthiness of large language models.
Conclusion
This paper provides an insightful comparison of large and small language models, highlighting how model size can impact the ability to generate truthful and well-grounded text. The researchers explore the potential for smaller models to assist larger models in verifying the reliability of their own outputs, which could lead to significant improvements in the linguistic calibration and groundedness of long-form text generation.
While the paper acknowledges several limitations and areas for further research, it represents an important step towards developing more robust and trustworthy language AI systems that can better serve the needs of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
New!How Well Do Large Language Models Truly Ground?
Hyunji Lee, Sejune Joo, Chaeeun Kim, Joel Jang, Doyoung Kim, Kyoung-Woon On, Minjoon Seo
0
0
To reduce issues like hallucinations and lack of control in Large Language Models (LLMs), a common method is to generate responses by grounding on external contexts given as input, known as knowledge-augmented models. However, previous research often narrowly defines grounding as just having the correct answer, which does not ensure the reliability of the entire response. To overcome this, we propose a stricter definition of grounding: a model is truly grounded if it (1) fully utilizes the necessary knowledge from the provided context, and (2) stays within the limits of that knowledge. We introduce a new dataset and a grounding metric to evaluate model capability under the definition. We perform experiments across 25 LLMs of different sizes and training methods and provide insights into factors that influence grounding performance. Our findings contribute to a better understanding of how to improve grounding capabilities and suggest an area of improvement toward more reliable and controllable LLM applications.
7/2/2024
💬
Effective Large Language Model Adaptation for Improved Grounding and Citation Generation
Xi Ye, Ruoxi Sun, Sercan O. Arik, Tomas Pfister
0
0
Large language models (LLMs) have achieved remarkable advancements in natural language understanding and generation. However, one major issue towards their widespread deployment in the real world is that they can generate hallucinated answers that are not factual. Towards this end, this paper focuses on improving LLMs by grounding their responses in retrieved passages and by providing citations. We propose a new framework, AGREE, Adaptation for GRounding EnhancEment, that improves the grounding from a holistic perspective. Our framework tunes LLMs to selfground the claims in their responses and provide accurate citations to retrieved documents. This tuning on top of the pre-trained LLMs requires well-grounded responses (with citations) for paired queries, for which we introduce a method that can automatically construct such data from unlabeled queries. The selfgrounding capability of tuned LLMs further grants them a test-time adaptation (TTA) capability that can actively retrieve passages to support the claims that have not been grounded, which iteratively improves the responses of LLMs. Across five datasets and two LLMs, our results show that the proposed tuningbased AGREE framework generates superior grounded responses with more accurate citations compared to prompting-based approaches and post-hoc citing-based approaches
4/4/2024
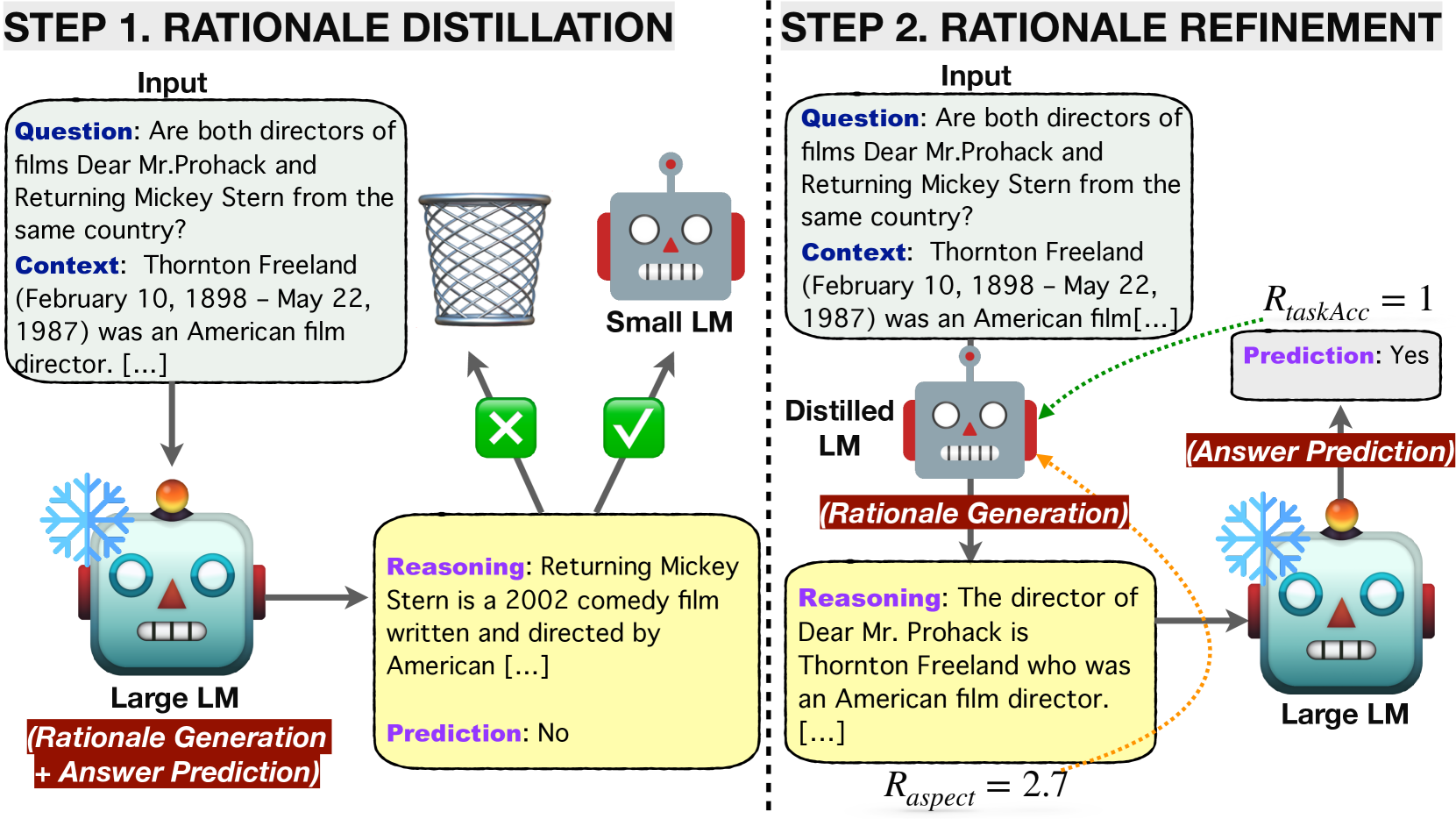
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024