Camera Motion Estimation from RGB-D-Inertial Scene Flow
2404.17251
0
0

Abstract
In this paper, we introduce a novel formulation for camera motion estimation that integrates RGB-D images and inertial data through scene flow. Our goal is to accurately estimate the camera motion in a rigid 3D environment, along with the state of the inertial measurement unit (IMU). Our proposed method offers the flexibility to operate as a multi-frame optimization or to marginalize older data, thus effectively utilizing past measurements. To assess the performance of our method, we conducted evaluations using both synthetic data from the ICL-NUIM dataset and real data sequences from the OpenLORIS-Scene dataset. Our results show that the fusion of these two sensors enhances the accuracy of camera motion estimation when compared to using only visual data.
Create account to get full access
Overview
- This paper presents a novel approach for camera motion estimation from RGB-D (color and depth) and inertial data.
- The proposed method combines scene flow, which captures the 3D motion of objects in the scene, with inertial sensor data to estimate the camera's 6-DOF (degrees of freedom) pose.
- The authors demonstrate the effectiveness of their approach on various datasets, showing improved performance compared to existing methods.
Plain English Explanation
In this research paper, the authors have developed a new way to estimate the motion and position of a camera using a combination of different types of sensor data. Typically, cameras can only capture color (RGB) and depth information, which can be used to track the 3D movement of objects in the scene, known as "scene flow." However, the authors also incorporate data from inertial sensors, such as those found in smartphones or virtual reality headsets, which provide information about the camera's orientation and acceleration.
By combining the scene flow data with the inertial sensor data, the researchers were able to more accurately estimate the camera's 6-DOF (six degrees of freedom) pose, which includes its position and orientation in 3D space. This is an important task in various applications, such as augmented reality, robotics, and virtual reality, where knowing the precise location and orientation of the camera is crucial for correctly overlaying digital content or controlling a robot's movements.
The authors tested their method on several different datasets and found that it outperformed existing approaches for camera motion estimation, demonstrating the value of their novel combination of scene flow and inertial sensor data.
Technical Explanation
The key idea behind the authors' approach is to leverage the complementary information provided by RGB-D (color and depth) data and inertial sensors to estimate the camera's 6-DOF pose. The authors first compute the scene flow, which captures the 3D motion of objects in the scene, using the RGB-D data. They then fuse this scene flow information with the inertial sensor data, which provides information about the camera's orientation and acceleration, to estimate the camera's pose.
The authors' method involves several steps:
- Extracting and aligning the RGB-D and inertial sensor data.
- Computing the scene flow from the RGB-D data using a learning-based optical flow estimation approach.
- Integrating the scene flow and inertial sensor data to estimate the camera's 6-DOF pose.
The authors evaluate their method on several publicly available datasets and compare its performance to that of existing camera motion estimation techniques. Their results show that the proposed approach outperforms the state-of-the-art methods, demonstrating the benefits of combining RGB-D and inertial sensor data for this task.
Critical Analysis
The authors provide a thorough evaluation of their proposed method, testing it on multiple datasets and comparing it to various existing approaches. However, the paper does not discuss any significant limitations or potential drawbacks of their approach.
One potential issue that could be worth exploring is the sensitivity of the method to sensor noise or calibration errors, as the performance of the camera pose estimation relies on the accuracy of both the RGB-D and inertial sensor data. Additionally, the authors do not address the computational complexity of their approach or its suitability for real-time applications, which would be an important consideration for many practical use cases.
Furthermore, the paper does not explore the broader implications of this research or discuss potential future applications beyond the specific tasks evaluated in the experiments. Expanding the discussion to consider how this work could contribute to advances in augmented reality, robotics, or virtual reality could help readers better understand the significance and broader impact of the research.
Conclusion
This paper presents a novel approach for camera motion estimation that combines RGB-D scene flow with inertial sensor data. The authors demonstrate that their method outperforms existing techniques on various datasets, highlighting the benefits of integrating multiple sensor modalities for this task.
The ability to accurately estimate a camera's 6-DOF pose is crucial for a wide range of applications, from augmented reality and robotics to virtual reality and 3D reconstruction. The authors' work represents an important step forward in this field, and their approach could have a significant impact on a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion
Haisong Liu, Tao Lu, Yihui Xu, Jia Liu, Limin Wang
0
0
In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline that splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, which consists of 2D and 3D branches with multiple bidirectional fusion connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to extract the LiDAR features, as it preserves the geometric structure of point clouds. To fuse dense image features and sparse point features, we propose a learnable operator named bidirectional camera-LiDAR fusion module (Bi-CLFM). We instantiate two types of the bidirectional fusion pipeline, one based on the pyramidal coarse-to-fine architecture (dubbed CamLiPWC), and the other one based on the recurrent all-pairs field transforms (dubbed CamLiRAFT). On FlyingThings3D, both CamLiPWC and CamLiRAFT surpass all existing methods and achieve up to a 47.9% reduction in 3D end-point-error from the best published result. Our best-performing model, CamLiRAFT, achieves an error of 4.26% on the KITTI Scene Flow benchmark, ranking 1st among all submissions with much fewer parameters. Besides, our methods have strong generalization performance and the ability to handle non-rigid motion. Code is available at https://github.com/MCG-NJU/CamLiFlow.
4/9/2024
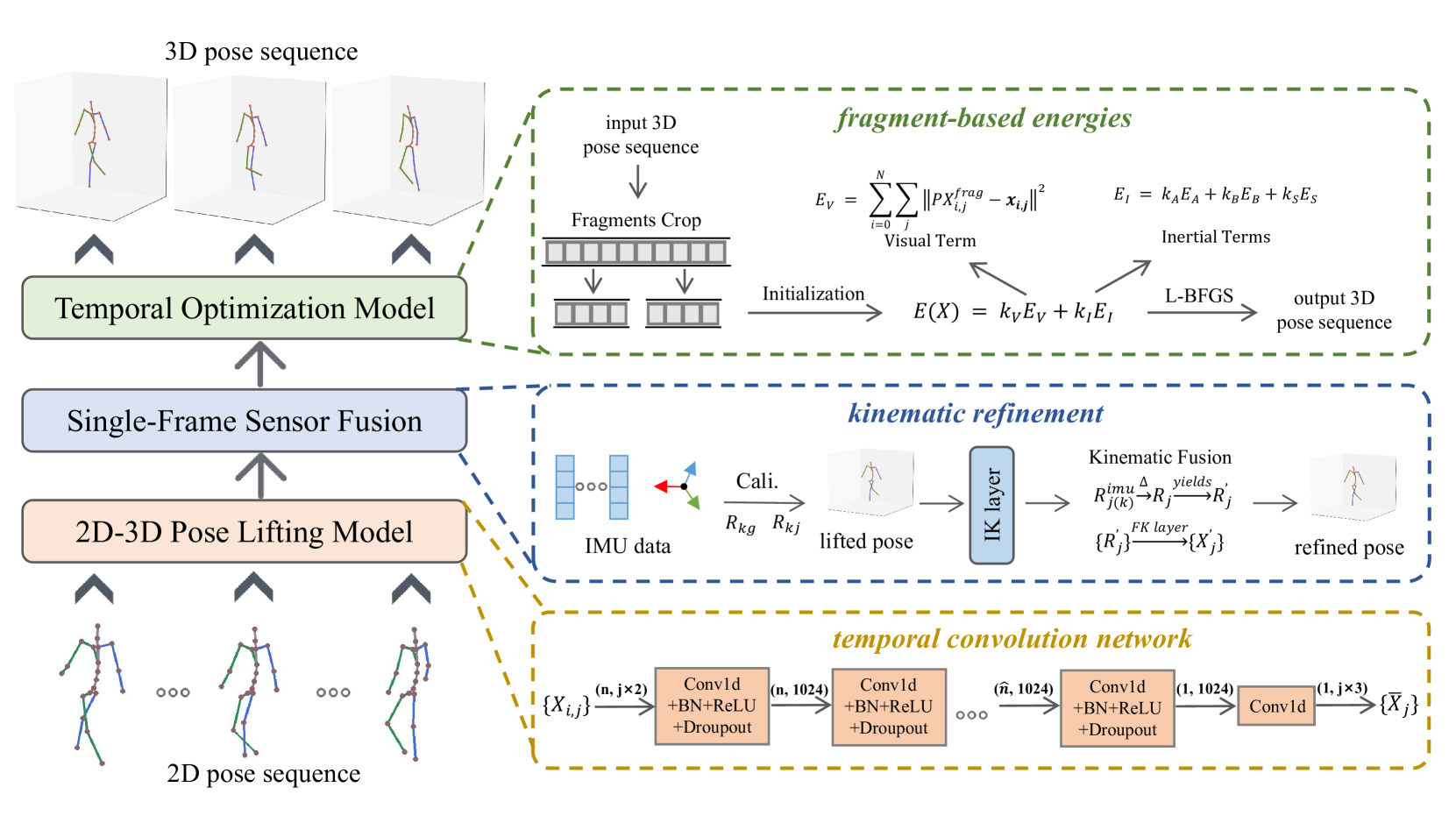
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
0
0
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
4/30/2024
💬
Physics-Based Rigid Body Object Tracking and Friction Filtering From RGB-D Videos
Rama Krishna Kandukuri, Michael Strecke, Joerg Stueckler
0
0
Physics-based understanding of object interactions from sensory observations is an essential capability in augmented reality and robotics. It enables to capture the properties of a scene for simulation and control. In this paper, we propose a novel approach for real-to-sim which tracks rigid objects in 3D from RGB-D images and infers physical properties of the objects. We use a differentiable physics simulation as state-transition model in an Extended Kalman Filter which can model contact and friction for arbitrary mesh-based shapes and in this way estimate physically plausible trajectories. We demonstrate that our approach can filter position, orientation, velocities, and concurrently can estimate the coefficient of friction of the objects. We analyze our approach on various sliding scenarios in synthetic image sequences of single objects and colliding objects. We also demonstrate and evaluate our approach on a real-world dataset. We make our novel benchmark datasets publicly available to foster future research in this novel problem setting and comparison with our method.
5/31/2024
🎯
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
Haixin Shi, Yinlin Hu, Daniel Koguciuk, Juan-Ting Lin, Mathieu Salzmann, David Ferstl
0
0
We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
5/13/2024