A Unified Diffusion Framework for Scene-aware Human Motion Estimation from Sparse Signals
2404.04890
0
0

Abstract
Estimating full-body human motion via sparse tracking signals from head-mounted displays and hand controllers in 3D scenes is crucial to applications in AR/VR. One of the biggest challenges to this task is the one-to-many mapping from sparse observations to dense full-body motions, which endowed inherent ambiguities. To help resolve this ambiguous problem, we introduce a new framework to combine rich contextual information provided by scenes to benefit full-body motion tracking from sparse observations. To estimate plausible human motions given sparse tracking signals and 3D scenes, we develop $text{S}^2$Fusion, a unified framework fusing underline{S}cene and sparse underline{S}ignals with a conditional difunderline{Fusion} model. $text{S}^2$Fusion first extracts the spatial-temporal relations residing in the sparse signals via a periodic autoencoder, and then produces time-alignment feature embedding as additional inputs. Subsequently, by drawing initial noisy motion from a pre-trained prior, $text{S}^2$Fusion utilizes conditional diffusion to fuse scene geometry and sparse tracking signals to generate full-body scene-aware motions. The sampling procedure of $text{S}^2$Fusion is further guided by a specially designed scene-penetration loss and phase-matching loss, which effectively regularizes the motion of the lower body even in the absence of any tracking signals, making the generated motion much more plausible and coherent. Extensive experimental results have demonstrated that our $text{S}^2$Fusion outperforms the state-of-the-art in terms of estimation quality and smoothness.
Create account to get full access
Overview
- This paper proposes a unified diffusion framework for scene-aware human motion estimation from sparse signals.
- The framework combines a VAE-based motion prior, a periodic autoencoder, and a diffusion model to generate realistic human motions that are aware of the surrounding environment.
- The model can be used for applications such as scene-aware human motion forecasting, sparse-to-dense video generation, and 3D content generation.
Plain English Explanation
The paper describes a new way to create realistic computer animations of human motion that are aware of the environment around the person. The key ideas are:
-
Using a variational autoencoder (VAE) to learn a model of typical human motion patterns. This allows the system to generate new motion sequences that look natural.
-
Incorporating a "periodic autoencoder" to model the cyclic nature of many human movements, like walking or running.
-
Combining these motion models with a diffusion model that can generate motion sequences that are aware of the surrounding 3D scene. This allows the animations to look like they are interacting with the environment in a realistic way.
The authors demonstrate that this unified framework can be used for tasks like predicting future human motions, generating dense video from sparse inputs, and creating 3D animations. The key advantage is that the motions are both natural-looking and aware of the scene context.
Technical Explanation
The paper presents a unified diffusion framework for scene-aware human motion estimation from sparse signals. The core components of the framework are:
-
VAE-based motion prior: A variational autoencoder (VAE) is used to learn a generative model of typical human motion patterns. This allows the system to synthesize new motion sequences that look natural and plausible.
-
Periodic autoencoder: To better capture the cyclic nature of many human movements, the authors incorporate a periodic autoencoder. This model can encode and decode periodic motion trajectories, such as walking or running.
-
Diffusion model: The motion prior and periodic autoencoder are combined with a diffusion model that can generate motion sequences that are conditioned on the surrounding 3D scene. This allows the system to create human motions that realistically interact with the environment.
The authors demonstrate the capabilities of this unified framework on tasks like scene-aware human motion forecasting, sparse-to-dense video generation, and 3D content generation. The key advantage is that the generated motions are both natural-looking and contextually aware.
Critical Analysis
The paper presents a compelling approach to integrating scene awareness into human motion generation. By combining VAE-based motion priors, periodic autoencoders, and diffusion models, the authors create a flexible framework that can be applied to a variety of tasks.
One potential limitation is the reliance on 3D scene information, which may not always be available in real-world applications. It would be interesting to see how the framework could be adapted to work with more sparse or incomplete scene data.
Additionally, while the authors demonstrate the framework on several tasks, more extensive evaluation and comparison to other state-of-the-art methods would help to further validate the approach.
Overall, this research represents an important step towards generating human motions that are both realistic and contextually aware, with potential applications in areas like co-speech gesture generation and high-quality 3D human generation.
Conclusion
This paper introduces a unified diffusion framework for scene-aware human motion estimation from sparse signals. By combining VAE-based motion priors, periodic autoencoders, and diffusion models, the authors create a system that can generate realistic human motions that are aware of the surrounding environment.
The framework demonstrates promising results on tasks like scene-aware motion forecasting, sparse-to-dense video generation, and 3D content creation. While there are some potential limitations, this research represents an important step towards more contextually-aware and natural-looking human motion synthesis, with applications in areas like animation, robotics, and virtual reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
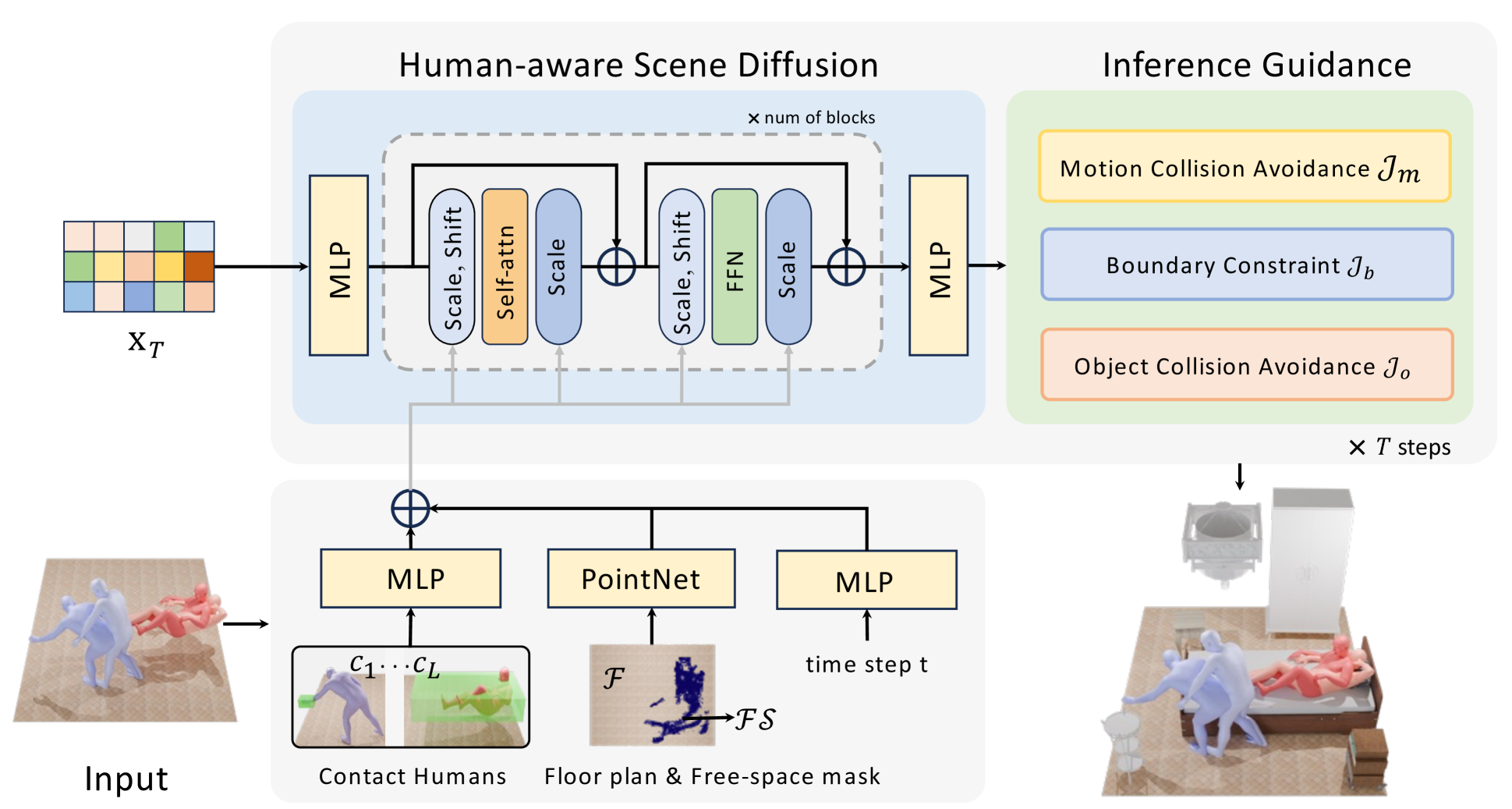
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024
🔮
Scene-aware Human Motion Forecasting via Mutual Distance Prediction
Chaoyue Xing, Wei Mao, Miaomiao Liu
0
0
In this paper, we tackle the problem of scene-aware 3D human motion forecasting. A key challenge of this task is to predict future human motions that are consistent with the scene by modeling the human-scene interactions. While recent works have demonstrated that explicit constraints on human-scene interactions can prevent the occurrence of ghost motion, they only provide constraints on partial human motion e.g., the global motion of the human or a few joints contacting the scene, leaving the rest of the motion unconstrained. To address this limitation, we propose to model the human-scene interaction with the mutual distance between the human body and the scene. Such mutual distances constrain both the local and global human motion, resulting in a whole-body motion constrained prediction. In particular, mutual distance constraints consist of two components, the signed distance of each vertex on the human mesh to the scene surface and the distance of basis scene points to the human mesh. We further introduce a global scene representation learned from a signed distance function (SDF) volume to ensure coherence between the global scene representation and the explicit constraint from the mutual distance. We develop a pipeline with two sequential steps: predicting the future mutual distances first, followed by forecasting future human motion. During training, we explicitly encourage consistency between predicted poses and mutual distances. Extensive evaluations on the existing synthetic and real datasets demonstrate that our approach consistently outperforms the state-of-the-art methods.
4/5/2024
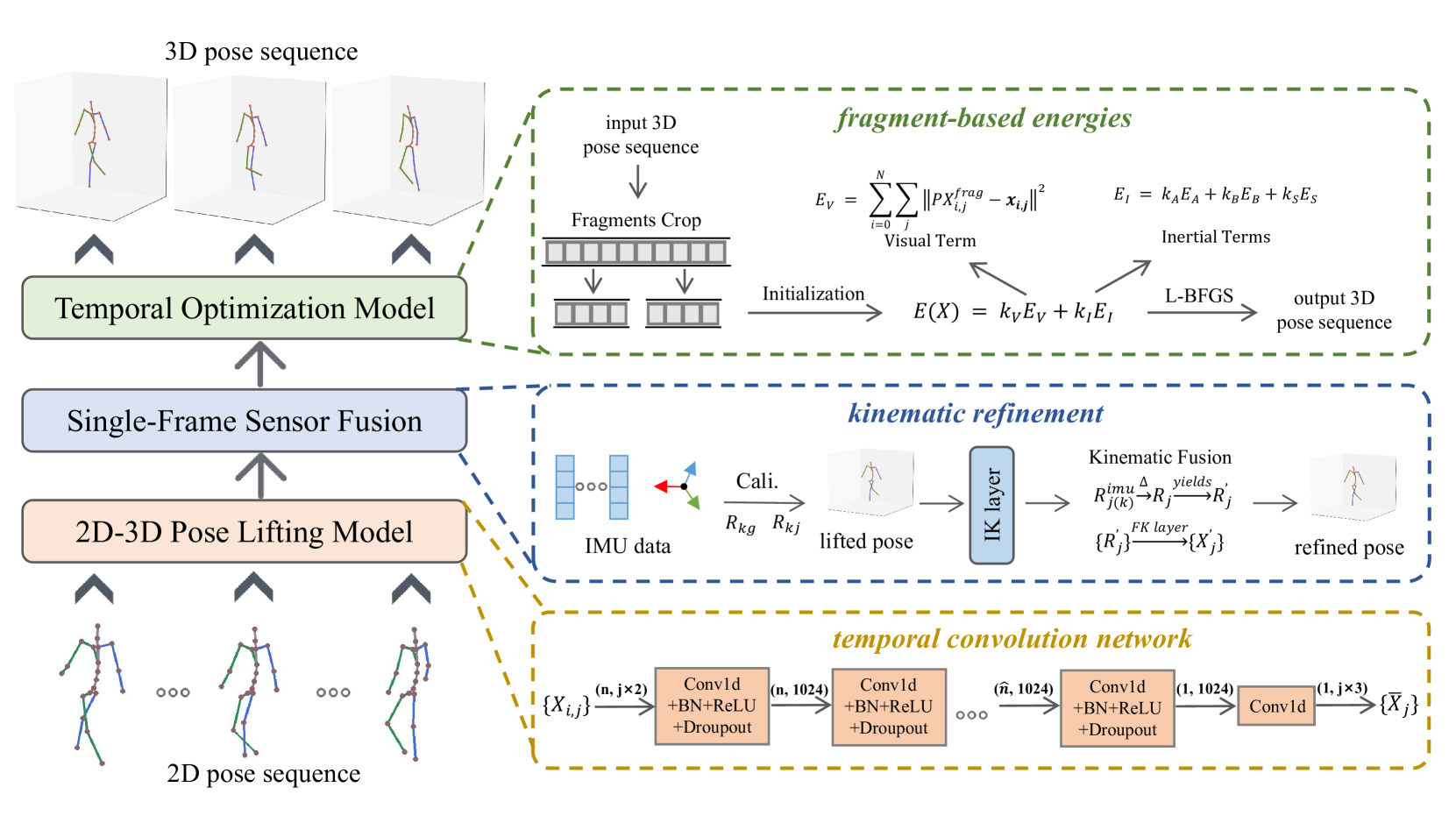
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
0
0
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
4/30/2024

Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo
0
0
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
4/23/2024