Camera Perspective Transformation to Bird's Eye View via Spatial Transformer Model for Road Intersection Monitoring

0

Sign in to get full access
Overview
- Presents a method to transform camera images into a bird's-eye view (BEV) perspective for monitoring road intersections
- Uses a spatial transformer network to perform the perspective transformation, coupled with a double decoder U-Net architecture
- Aims to provide a reliable and efficient way to monitor traffic and road conditions from a top-down viewpoint
Plain English Explanation
The research paper introduces a technique to convert camera images into a bird's-eye view (BEV) perspective. This is useful for monitoring road intersections, as it allows traffic and road conditions to be observed from a top-down viewpoint.
The key innovation is the use of a spatial transformer network to perform the perspective transformation. This network learns how to warp the original camera image into a BEV format, without requiring manual calibration or complex geometric calculations.
The spatial transformer network is combined with a double decoder U-Net architecture to produce the final BEV output. This allows the model to learn the transformation in an end-to-end fashion, making it efficient and easy to deploy.
By converting the camera view to a BEV, the system can provide a clear, top-down visualization of the road intersection. This enables better monitoring of traffic flow, vehicle movements, and road conditions, which is valuable for applications like traffic management and autonomous driving.
Technical Explanation
The paper proposes a method for transforming camera images into a bird's-eye view (BEV) perspective, which is useful for monitoring road intersections. The key components of the approach are:
-
Spatial Transformer Network: A neural network module that learns how to warp the input camera image into a BEV format. This is done without requiring manual calibration or complex geometric calculations, as the network learns the transformation end-to-end.
-
Double Decoder U-Net Architecture: The spatial transformer network is coupled with a U-Net-based architecture that has two decoder branches. One branch outputs the transformed BEV image, while the other branch produces a semantic segmentation of the scene.
The authors train and evaluate the model on a dataset of road intersection images, demonstrating its ability to accurately transform the perspective and provide a reliable BEV representation. The dual-output architecture allows the system to not only transform the image, but also extract semantic information about the road, vehicles, and other elements in the scene.
Critical Analysis
The paper presents a compelling approach for converting camera images to a bird's-eye view perspective, which has important applications in road intersection monitoring and autonomous driving. The use of a spatial transformer network to learn the perspective transformation is a clever and efficient solution, avoiding the need for manual calibration.
However, the paper does not extensively discuss the limitations or potential issues with the proposed method. For example, it would be valuable to know how the system performs in challenging lighting conditions, inclement weather, or with occluded views. Additionally, the authors could explore the trade-offs between the accuracy of the BEV transformation and the computational efficiency of the model.
Further research could also investigate the performance of the system in real-world deployment scenarios, such as integrating the BEV transformation with other computer vision tasks like object detection and tracking. Exploring ways to make the system more robust and adaptable to diverse road environments would also be a valuable direction for future work.
Conclusion
The paper presents a novel approach for transforming camera images into a bird's-eye view perspective, which is a crucial capability for effective road intersection monitoring. The use of a spatial transformer network and a double decoder U-Net architecture allows the system to learn the perspective transformation in an end-to-end manner, making it efficient and easy to deploy.
By providing a reliable BEV representation of the road scene, this work enables better monitoring of traffic flow, vehicle movements, and road conditions. This has important implications for applications like traffic management, infrastructure planning, and autonomous driving. The technical insights and the potential for further development make this a valuable contribution to the field of computer vision for smart transportation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Camera Perspective Transformation to Bird's Eye View via Spatial Transformer Model for Road Intersection Monitoring
Rukesh Prajapati, Amr S. El-Wakeel
Road intersection monitoring and control research often utilize bird's eye view (BEV) simulators. In real traffic settings, achieving a BEV akin to that in a simulator necessitates the deployment of drones or specific sensor mounting, which is neither feasible nor practical. Consequently, traffic intersection management remains confined to simulation environments given these constraints. In this paper, we address the gap between simulated environments and real-world implementation by introducing a novel deep-learning model that converts a single camera's perspective of a road intersection into a BEV. We created a simulation environment that closely resembles a real-world traffic junction. The proposed model transforms the vehicles into BEV images, facilitating road intersection monitoring and control model processing. Inspired by image transformation techniques, we propose a Spatial-Transformer Double Decoder-UNet (SDD-UNet) model that aims to eliminate the transformed image distortions. In addition, the model accurately estimates the vehicle's positions and enables the direct application of simulation-trained models in real-world contexts. SDD-UNet model achieves an average dice similarity coefficient (DSC) above 95% which is 40% better than the original UNet model. The mean absolute error (MAE) is 0.102 and the centroid of the predicted mask is 0.14 meters displaced, on average, indicating high accuracy.
Read more8/15/2024
↗️
0
New!DualBEV: Unifying Dual View Transformation with Probabilistic Correspondences
Peidong Li, Wancheng Shen, Qihao Huang, Dixiao Cui
Camera-based Bird's-Eye-View (BEV) perception often struggles between adopting 3D-to-2D or 2D-to-3D view transformation (VT). The 3D-to-2D VT typically employs resource-intensive Transformer to establish robust correspondences between 3D and 2D features, while the 2D-to-3D VT utilizes the Lift-Splat-Shoot (LSS) pipeline for real-time application, potentially missing distant information. To address these limitations, we propose DualBEV, a unified framework that utilizes a shared feature transformation incorporating three probabilistic measurements for both strategies. By considering dual-view correspondences in one stage, DualBEV effectively bridges the gap between these strategies, harnessing their individual strengths. Our method achieves state-of-the-art performance without Transformer, delivering comparable efficiency to the LSS approach, with 55.2% mAP and 63.4% NDS on the nuScenes test set. Code is available at url{https://github.com/PeidongLi/DualBEV}
Read more9/16/2024

0
Improved Single Camera BEV Perception Using Multi-Camera Training
Daniel Busch, Ido Freeman, Richard Meyes, Tobias Meisen
Bird's Eye View (BEV) map prediction is essential for downstream autonomous driving tasks like trajectory prediction. In the past, this was accomplished through the use of a sophisticated sensor configuration that captured a surround view from multiple cameras. However, in large-scale production, cost efficiency is an optimization goal, so that using fewer cameras becomes more relevant. But the consequence of fewer input images correlates with a performance drop. This raises the problem of developing a BEV perception model that provides a sufficient performance on a low-cost sensor setup. Although, primarily relevant for inference time on production cars, this cost restriction is less problematic on a test vehicle during training. Therefore, the objective of our approach is to reduce the aforementioned performance drop as much as possible using a modern multi-camera surround view model reduced for single-camera inference. The approach includes three features, a modern masking technique, a cyclic Learning Rate (LR) schedule, and a feature reconstruction loss for supervising the transition from six-camera inputs to one-camera input during training. Our method outperforms versions trained strictly with one camera or strictly with six-camera surround view for single-camera inference resulting in reduced hallucination and better quality of the BEV map.
Read more9/5/2024
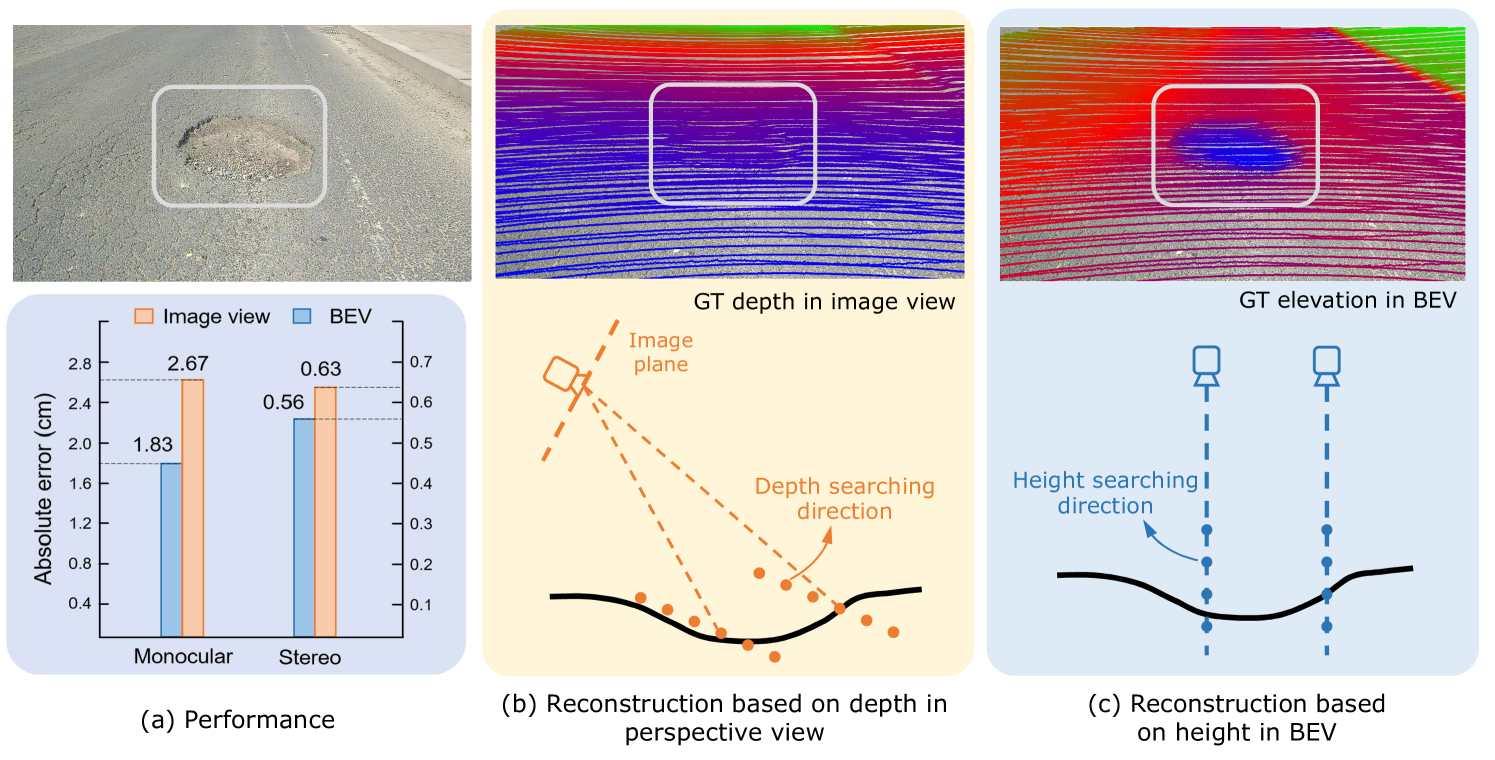
0
RoadBEV: Road Surface Reconstruction in Bird's Eye View
Tong Zhao, Lei Yang, Yichen Xie, Mingyu Ding, Masayoshi Tomizuka, Yintao Wei
Road surface conditions, especially geometry profiles, enormously affect driving performance of autonomous vehicles. Vision-based online road reconstruction promisingly captures road information in advance. Existing solutions like monocular depth estimation and stereo matching suffer from modest performance. The recent technique of Bird's-Eye-View (BEV) perception provides immense potential to more reliable and accurate reconstruction. This paper uniformly proposes two simple yet effective models for road elevation reconstruction in BEV named RoadBEV-mono and RoadBEV-stereo, which estimate road elevation with monocular and stereo images, respectively. The former directly fits elevation values based on voxel features queried from image view, while the latter efficiently recognizes road elevation patterns based on BEV volume representing correlation between left and right voxel features. Insightful analyses reveal their consistence and difference with the perspective view. Experiments on real-world dataset verify the models' effectiveness and superiority. Elevation errors of RoadBEV-mono and RoadBEV-stereo achieve 1.83 cm and 0.50 cm, respectively. Our models are promising for practical road preview, providing essential information for promoting safety and comfort of autonomous vehicles. The code is released at https://github.com/ztsrxh/RoadBEV
Read more8/9/2024