Cameras as Rays: Pose Estimation via Ray Diffusion
2402.14817
0
0
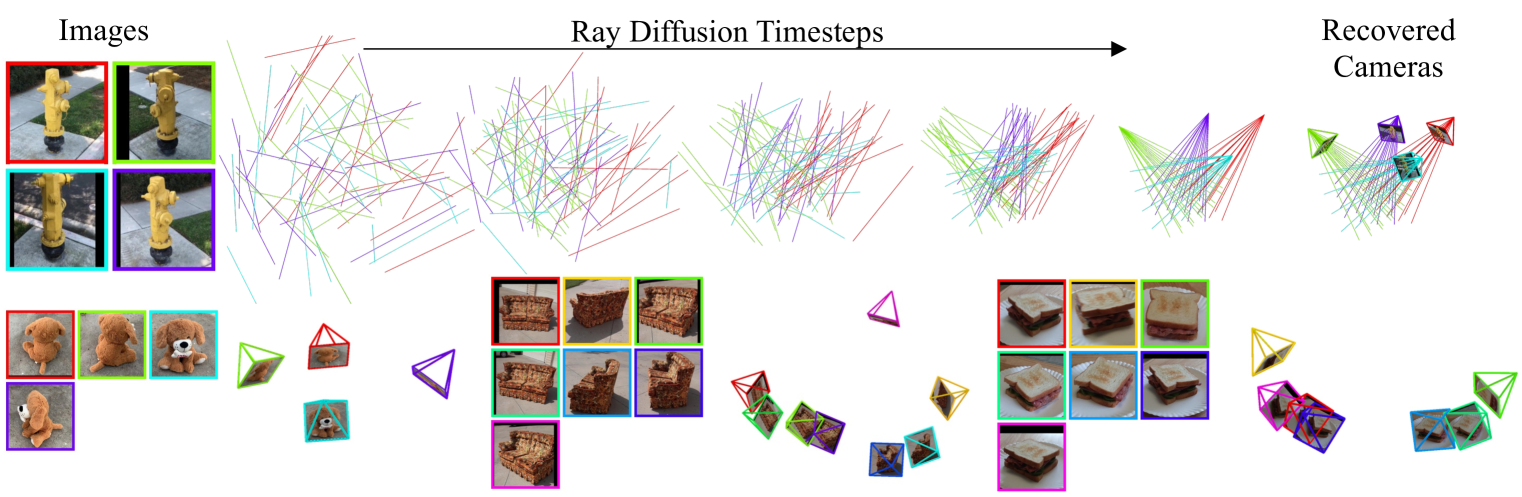
Abstract
Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparsely sampled views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
Create account to get full access
Overview
- This paper presents a novel approach to camera pose estimation by representing cameras as rays and modeling their diffusion through space.
- The proposed method, called "Cameras as Rays: Pose Estimation via Ray Diffusion," aims to improve the accuracy and robustness of camera pose estimation, which is a fundamental task in computer vision and augmented reality applications.
- The authors leverage the concept of ray diffusion to model the propagation of camera rays and solve for the optimal camera poses.
Plain English Explanation
Cameras work by capturing light rays that bounce off objects in the world and enter the camera lens. The Cameras as Rays approach treats each camera as a source of these light rays, and models how these rays diffuse or spread out through the 3D space around the camera.
By understanding how the camera rays behave, the researchers can then figure out the precise position and orientation (pose) of the camera in the 3D scene. This is a crucial step for applications like augmented reality, where virtual objects need to be seamlessly integrated into the real-world view.
The key insight is that the diffusion of the camera rays contains valuable information about the camera's pose. By analyzing this diffusion process, the researchers can accurately estimate the camera's position and orientation, even in challenging scenarios with occlusions or moving objects.
Technical Explanation
The core of the "Cameras as Rays" approach is to model each camera as a set of rays emanating from the camera center and diffusing through the 3D space. The researchers leverage the concept of ray diffusion, where the rays are treated as particles that spread out over time according to a diffusion equation.
By observing the diffusion of the camera rays and how they interact with the 3D scene, the algorithm can then solve for the optimal camera pose that best explains the observed ray diffusion. This is formulated as an optimization problem, where the goal is to find the camera pose that minimizes the difference between the observed ray diffusion and the predicted ray diffusion based on the camera model.
The researchers demonstrate the effectiveness of their approach on a variety of structure-from-motion and SLAM benchmarks, showing improved performance compared to traditional feature-based methods.
Critical Analysis
The "Cameras as Rays" approach offers a novel and promising perspective on camera pose estimation, leveraging the rich information contained in the diffusion of camera rays. By moving away from the traditional feature-based methods, the researchers have demonstrated the potential for more robust and accurate pose estimation, even in challenging scenarios.
However, the paper does not address potential limitations of the approach, such as its sensitivity to noise or its performance in highly dynamic environments. Additionally, the computational complexity of the ray diffusion optimization may limit its scalability to large-scale applications.
Further research is needed to explore the boundaries of this technique, investigate its robustness to various real-world conditions, and potentially combine it with other complementary methods to create a more comprehensive pose estimation framework.
Conclusion
The "Cameras as Rays" approach presents a novel and promising direction for camera pose estimation, leveraging the rich information contained in the diffusion of camera rays. By modeling cameras as sources of light rays and analyzing their propagation through the 3D scene, the researchers have demonstrated improved accuracy and robustness compared to traditional feature-based methods.
This work has the potential to significantly impact applications such as augmented reality, where accurate camera pose estimation is crucial for seamlessly integrating virtual content into the real world. As the field of computer vision continues to evolve, techniques like "Cameras as Rays" may pave the way for more sophisticated and reliable 3D perception and scene understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Object Pose Estimation via the Aggregation of Diffusion Features
Tianfu Wang, Guosheng Hu, Hongguang Wang
0
0
Estimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. Our code is released at https://github.com/Tianfu18/diff-feats-pose.
6/4/2024

Generative Lifting of Multiview to 3D from Unknown Pose: Wrapping NeRF inside Diffusion
Xin Yuan, Rana Hanocka, Michael Maire
0
0
We cast multiview reconstruction from unknown pose as a generative modeling problem. From a collection of unannotated 2D images of a scene, our approach simultaneously learns both a network to predict camera pose from 2D image input, as well as the parameters of a Neural Radiance Field (NeRF) for the 3D scene. To drive learning, we wrap both the pose prediction network and NeRF inside a Denoising Diffusion Probabilistic Model (DDPM) and train the system via the standard denoising objective. Our framework requires the system accomplish the task of denoising an input 2D image by predicting its pose and rendering the NeRF from that pose. Learning to denoise thus forces the system to concurrently learn the underlying 3D NeRF representation and a mapping from images to camera extrinsic parameters. To facilitate the latter, we design a custom network architecture to represent pose as a distribution, granting implicit capacity for discovering view correspondences when trained end-to-end for denoising alone. This technique allows our system to successfully build NeRFs, without pose knowledge, for challenging scenes where competing methods fail. At the conclusion of training, our learned NeRF can be extracted and used as a 3D scene model; our full system can be used to sample novel camera poses and generate novel-view images.
6/12/2024

DiffCalib: Reformulating Monocular Camera Calibration as Diffusion-Based Dense Incident Map Generation
Xiankang He, Guangkai Xu, Bo Zhang, Hao Chen, Ying Cui, Dongyan Guo
0
0
Monocular camera calibration is a key precondition for numerous 3D vision applications. Despite considerable advancements, existing methods often hinge on specific assumptions and struggle to generalize across varied real-world scenarios, and the performance is limited by insufficient training data. Recently, diffusion models trained on expansive datasets have been confirmed to maintain the capability to generate diverse, high-quality images. This success suggests a strong potential of the models to effectively understand varied visual information. In this work, we leverage the comprehensive visual knowledge embedded in pre-trained diffusion models to enable more robust and accurate monocular camera intrinsic estimation. Specifically, we reformulate the problem of estimating the four degrees of freedom (4-DoF) of camera intrinsic parameters as a dense incident map generation task. The map details the angle of incidence for each pixel in the RGB image, and its format aligns well with the paradigm of diffusion models. The camera intrinsic then can be derived from the incident map with a simple non-learning RANSAC algorithm during inference. Moreover, to further enhance the performance, we jointly estimate a depth map to provide extra geometric information for the incident map estimation. Extensive experiments on multiple testing datasets demonstrate that our model achieves state-of-the-art performance, gaining up to a 40% reduction in prediction errors. Besides, the experiments also show that the precise camera intrinsic and depth maps estimated by our pipeline can greatly benefit practical applications such as 3D reconstruction from a single in-the-wild image.
5/27/2024
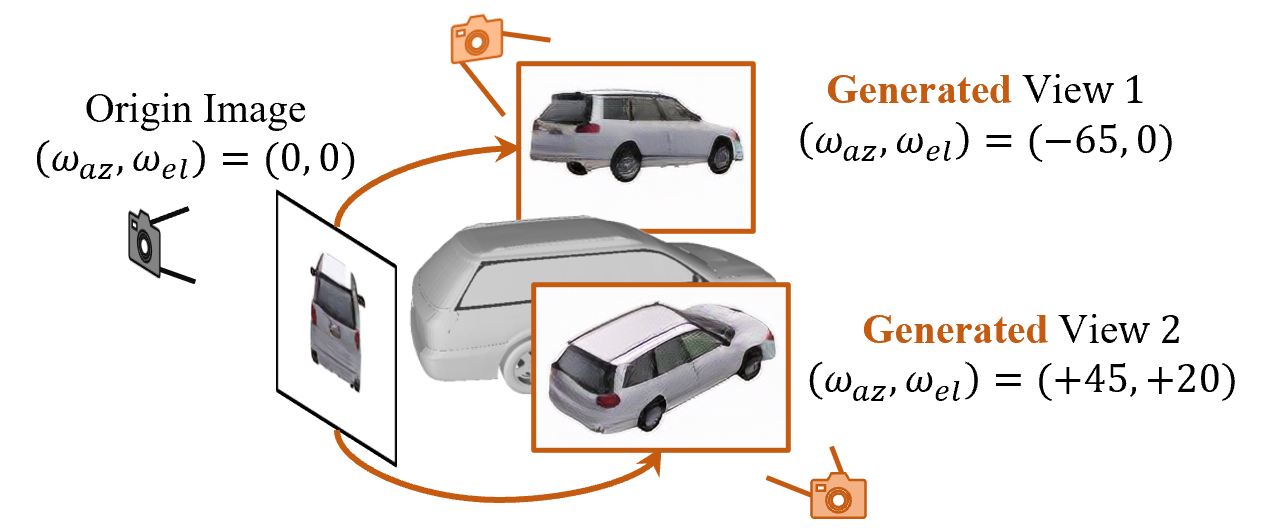
Learning a Category-level Object Pose Estimator without Pose Annotations
Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
0
0
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
4/9/2024