CamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model

0

Sign in to get full access
Overview
- This paper, "CamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model," presents a novel approach for generating panoramic images from a single input image without the need for a camera.
- The authors leverage the power of diffusion models, a type of generative AI, to transform a standard image into a high-quality 360-degree panorama.
- This method eliminates the requirement for specialized camera hardware, making panoramic image creation more accessible and scalable.
Plain English Explanation
The paper introduces a new technique called "CamFreeDiff" that can take a regular 2D image and turn it into a 360-degree panoramic image. Typically, creating a panorama would require using a specialized camera that can capture a wide field of view. However, the researchers found a way to do this without needing a special camera.
Instead, they use a type of machine learning model called a "diffusion model." Diffusion models are a powerful AI technology that can generate new images from scratch or transform existing images in sophisticated ways. In this case, the diffusion model is able to take a standard 2D photo and extrapolate it outwards to create a complete 360-degree panoramic view.
This is a significant advancement because it makes it much easier for anyone to create panoramic images. Before, you'd need an expensive panoramic camera. Now, you can just use a normal photo and let the AI do the rest. This could open up new applications and use cases for panoramic imagery, since the barrier to entry has been greatly reduced.
Technical Explanation
The key innovation of "CamFreeDiff" is its use of a conditional diffusion model to perform the image-to-panorama transformation. Diffusion models work by learning to reverse a process of gradually adding noise to an image until it becomes completely random. By learning this reverse process, the model can then generate new images from scratch or manipulate existing ones.
In this case, the researchers trained the diffusion model to take a standard 2D image as input and generate the corresponding 360-degree panoramic view as output. This is accomplished by training the model on a large dataset of panoramic images along with their constituent 2D images.
The model architecture consists of a U-Net-based diffusion network that progressively refines the 2D image into the final panorama. Various techniques are employed to improve the coherence and quality of the generated panoramas, such as incorporating spherical priors and attention mechanisms.
Extensive experiments demonstrate the effectiveness of the CamFreeDiff approach. It is able to generate high-fidelity panoramas from single input images, outperforming previous state-of-the-art methods that relied on specialized camera setups. The model also exhibits strong generalization capabilities, handling a diverse range of scenes and image types.
Critical Analysis
One key limitation of the CamFreeDiff approach is that it requires a substantial training dataset of panoramic images paired with their 2D counterparts. Acquiring such a dataset may be challenging, especially for more niche or specialized panoramic applications.
Additionally, while the model demonstrates impressive performance, there may be inherent challenges in fully capturing the 3D spatial relationships and visual continuity of a panoramic scene from a single 2D input. Further research may be needed to address potential distortions or inconsistencies in the generated panoramas.
It is also worth considering the potential privacy and security implications of this technology. The ability to easily generate panoramic views from standard photographs could raise concerns about surveillance and the unauthorized capture of sensitive environments.
Overall, the CamFreeDiff method represents a significant advancement in panoramic image generation, but continued research and thoughtful deployment will be necessary to address its limitations and ethical considerations.
Conclusion
The CamFreeDiff paper introduces a novel approach for generating panoramic images from single 2D input images using a conditional diffusion model. This eliminates the need for specialized camera hardware, making panoramic image creation more accessible and scalable.
The technical innovations demonstrated in this work, such as the use of spherical priors and attention mechanisms, contribute to the generation of high-quality, coherent panoramas. While the method has some limitations, it represents an important step forward in the field of computational photography and has the potential to unlock new applications and use cases for panoramic imagery.
As the field of generative AI continues to advance, techniques like CamFreeDiff will likely play an increasingly important role in transforming how we create and interact with visual media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model
Xiaoding Yuan, Shitao Tang, Kejie Li, Alan Yuille, Peng Wang
This paper introduces Camera-free Diffusion (CamFreeDiff) model for 360-degree image outpainting from a single camera-free image and text description. This method distinguishes itself from existing strategies, such as MVDiffusion, by eliminating the requirement for predefined camera poses. Instead, our model incorporates a mechanism for predicting homography directly within the multi-view diffusion framework. The core of our approach is to formulate camera estimation by predicting the homography transformation from the input view to a predefined canonical view. The homography provides point-level correspondences between the input image and targeting panoramic images, allowing connections enforced by correspondence-aware attention in a fully differentiable manner. Qualitative and quantitative experimental results demonstrate our model's strong robustness and generalization ability for 360-degree image outpainting in the challenging context of camera-free inputs.
Read more7/11/2024

0
SpotDiffusion: A Fast Approach For Seamless Panorama Generation Over Time
Stanislav Frolov, Brian B. Moser, Andreas Dengel
Generating high-resolution images with generative models has recently been made widely accessible by leveraging diffusion models pre-trained on large-scale datasets. Various techniques, such as MultiDiffusion and SyncDiffusion, have further pushed image generation beyond training resolutions, i.e., from square images to panorama, by merging multiple overlapping diffusion paths or employing gradient descent to maintain perceptual coherence. However, these methods suffer from significant computational inefficiencies due to generating and averaging numerous predictions, which is required in practice to produce high-quality and seamless images. This work addresses this limitation and presents a novel approach that eliminates the need to generate and average numerous overlapping denoising predictions. Our method shifts non-overlapping denoising windows over time, ensuring that seams in one timestep are corrected in the next. This results in coherent, high-resolution images with fewer overall steps. We demonstrate the effectiveness of our approach through qualitative and quantitative evaluations, comparing it with MultiDiffusion, SyncDiffusion, and StitchDiffusion. Our method offers several key benefits, including improved computational efficiency and faster inference times while producing comparable or better image quality.
Read more7/23/2024
0
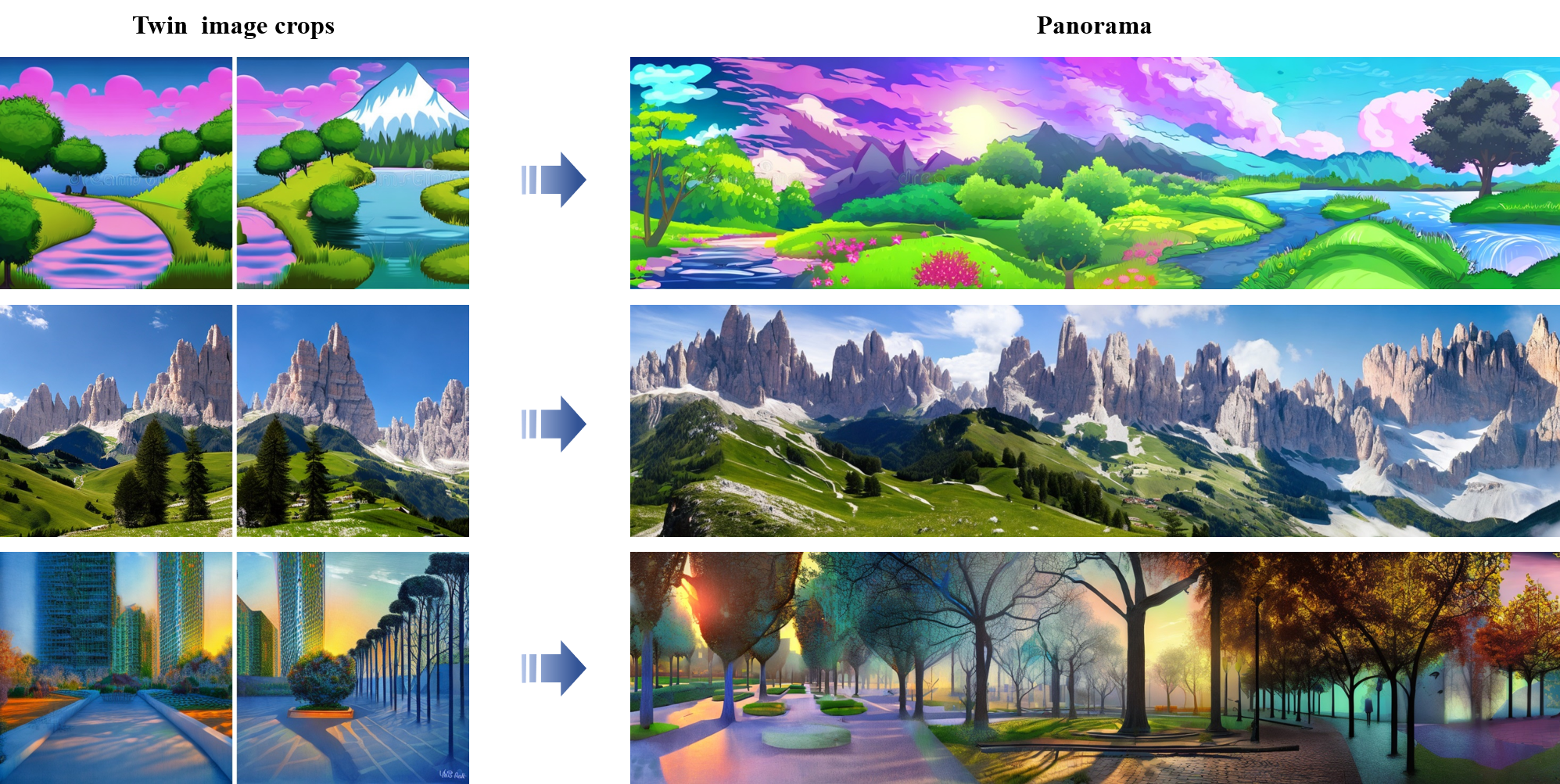
TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models
Teng Zhou, Yongchuan Tang
Diffusion models have emerged as effective tools for generating diverse and high-quality content. However, their capability in high-resolution image generation, particularly for panoramic images, still faces challenges such as visible seams and incoherent transitions. In this paper, we propose TwinDiffusion, an optimized framework designed to address these challenges through two key innovations: the Crop Fusion for quality enhancement and the Cross Sampling for efficiency optimization. We introduce a training-free optimizing stage to refine the similarity of adjacent image areas, as well as an interleaving sampling strategy to yield dynamic patches during the cropping process. A comprehensive evaluation is conducted to compare TwinDiffusion with the prior works, considering factors including coherence, fidelity, compatibility, and efficiency. The results demonstrate the superior performance of our approach in generating seamless and coherent panoramas, setting a new standard in quality and efficiency for panoramic image generation.
Read more7/9/2024
0
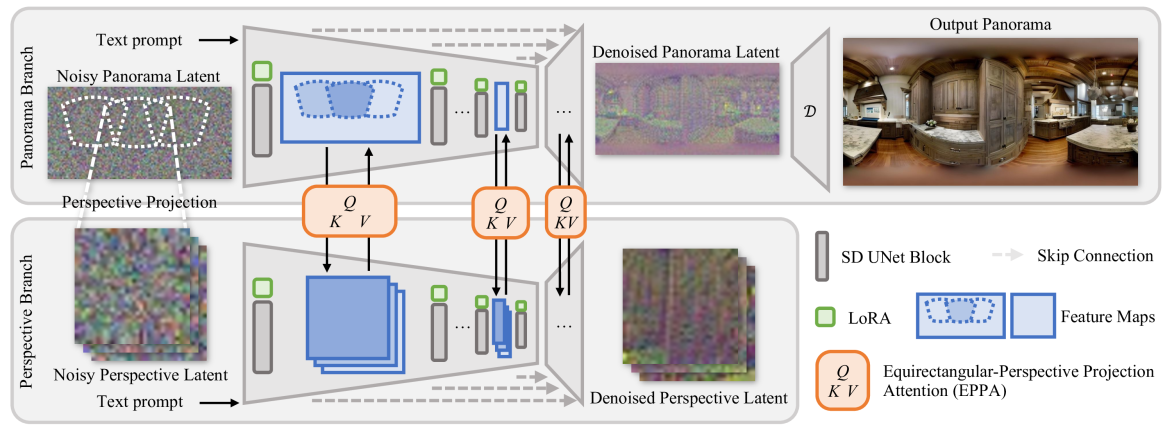
Taming Stable Diffusion for Text to 360{deg} Panorama Image Generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, Jianfei Cai
Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
Read more4/12/2024