Can a Bayesian Oracle Prevent Harm from an Agent?

0

Sign in to get full access
Overview
- Can a Bayesian Oracle prevent an AI agent from causing harm?
- Examines the feasibility of a "safe-by-design" AI system that can reliably prevent an agent from taking harmful actions.
- Investigates whether a powerful Bayesian Oracle can accurately predict an agent's behavior and intervene to avoid negative outcomes.
Plain English Explanation
The paper explores the idea of a "safe-by-design" AI system - one that can reliably prevent an AI agent from taking harmful actions. The key question is whether a powerful Bayesian Oracle, a system that can make highly accurate predictions about the agent's behavior, could intervene to avoid negative outcomes.
The researchers examine this by modeling an AI agent with a specific goal or task, and a Bayesian Oracle that can observe the agent's internal state and predict its actions. The Oracle's role is to intervene and block the agent from taking harmful actions that would violate certain safety constraints.
The paper investigates whether this Bayesian Oracle approach can effectively ensure the agent remains "safe" and avoids causing harm, even in complex environments where the agent's goals may conflict with the safety constraints. It considers the practical challenges and limitations of this approach in real-world deployment scenarios.
Technical Explanation
The paper models an AI agent with a specific objective function, operating in an environment with certain "safety constraints" that define harmful or undesirable actions. Alongside the agent, the researchers introduce a powerful "Bayesian Oracle" that can observe the agent's full internal state and use this to make highly accurate predictions about the agent's future behavior.
The Oracle's role is to intervene when the agent is predicted to take an action that would violate the safety constraints, blocking that action and preventing the agent from causing harm. The researchers analyze the feasibility of this approach, examining the Oracle's ability to reliably predict the agent's behavior and the trade-offs involved in different intervention strategies.
The analysis considers factors such as the complexity of the agent's objective function, the nature of the safety constraints, and the inherent uncertainty in predicting an agent's actions. The paper explores edge cases and failure modes where the Oracle may struggle to prevent harmful outcomes, even with complete information about the agent's internal state.
Critical Analysis
The paper raises important questions about the feasibility of "safe-by-design" AI systems that can reliably prevent an agent from causing harm. While the Bayesian Oracle approach seems promising in theory, the analysis highlights several practical challenges and limitations:
- The Oracle's predictive capabilities may break down in highly complex environments where the agent's objectives are not well-defined or are in tension with the safety constraints.
- There are inherent uncertainties in predicting an agent's behavior, even with complete information about its internal state, which could lead to failures in the Oracle's intervention.
- The paper does not address the significant technical and ethical challenges in developing a Bayesian Oracle with the necessary capabilities, or the risks of such a powerful system itself.
The researchers acknowledge that the Bayesian Oracle approach may not be a complete solution to the AI safety problem, and that further research is needed to explore alternative frameworks for ensuring the safe deployment of advanced AI systems.
Conclusion
This paper offers a thought-provoking exploration of the idea of a "safe-by-design" AI system, using a Bayesian Oracle to predict and prevent an agent from causing harm. While the concept has merit, the analysis highlights the significant practical challenges and limitations in reliably implementing such an approach.
The findings underscore the complexity and nuance involved in developing AI systems that can remain safe and beneficial, even in the face of unpredictable agent behavior and evolving environmental factors. As the field of AI continues to advance, this research contributes to the ongoing dialogue around responsible development and deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can a Bayesian Oracle Prevent Harm from an Agent?
Yoshua Bengio, Michael K. Cohen, Nikolay Malkin, Matt MacDermott, Damiano Fornasiere, Pietro Greiner, Younesse Kaddar
Is there a way to design powerful AI systems based on machine learning methods that would satisfy probabilistic safety guarantees? With the long-term goal of obtaining a probabilistic guarantee that would apply in every context, we consider estimating a context-dependent bound on the probability of violating a given safety specification. Such a risk evaluation would need to be performed at run-time to provide a guardrail against dangerous actions of an AI. Noting that different plausible hypotheses about the world could produce very different outcomes, and because we do not know which one is right, we derive bounds on the safety violation probability predicted under the true but unknown hypothesis. Such bounds could be used to reject potentially dangerous actions. Our main results involve searching for cautious but plausible hypotheses, obtained by a maximization that involves Bayesian posteriors over hypotheses. We consider two forms of this result, in the iid case and in the non-iid case, and conclude with open problems towards turning such theoretical results into practical AI guardrails.
Read more8/26/2024
2
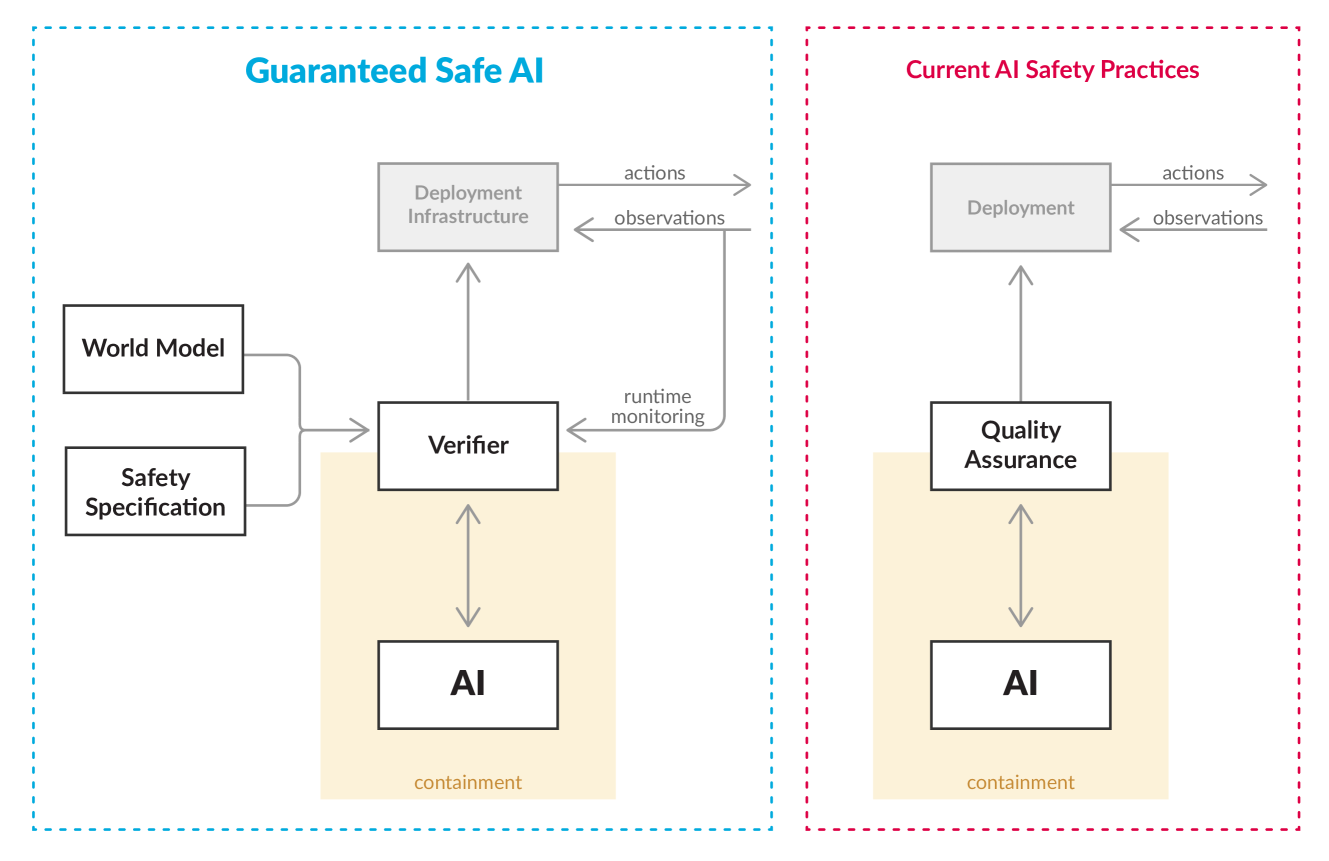
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Read more7/9/2024

0
Information-Theoretic Safe Bayesian Optimization
Alessandro G. Bottero, Carlos E. Luis, Julia Vinogradska, Felix Berkenkamp, Jan Peters
We consider a sequential decision making task, where the goal is to optimize an unknown function without evaluating parameters that violate an a~priori unknown (safety) constraint. A common approach is to place a Gaussian process prior on the unknown functions and allow evaluations only in regions that are safe with high probability. Most current methods rely on a discretization of the domain and cannot be directly extended to the continuous case. Moreover, the way in which they exploit regularity assumptions about the constraint introduces an additional critical hyperparameter. In this paper, we propose an information-theoretic safe exploration criterion that directly exploits the GP posterior to identify the most informative safe parameters to evaluate. The combination of this exploration criterion with a well known Bayesian optimization acquisition function yields a novel safe Bayesian optimization selection criterion. Our approach is naturally applicable to continuous domains and does not require additional explicit hyperparameters. We theoretically analyze the method and show that we do not violate the safety constraint with high probability and that we learn about the value of the safe optimum up to arbitrary precision. Empirical evaluations demonstrate improved data-efficiency and scalability.
Read more5/13/2024
🤖
0
Safeguarding AI Agents: Developing and Analyzing Safety Architectures
Ishaan Domkundwar, Mukunda N S, Ishaan Bhola
AI agents, specifically powered by large language models, have demonstrated exceptional capabilities in various applications where precision and efficacy are necessary. However, these agents come with inherent risks, including the potential for unsafe or biased actions, vulnerability to adversarial attacks, lack of transparency, and tendency to generate hallucinations. As AI agents become more prevalent in critical sectors of the industry, the implementation of effective safety protocols becomes increasingly important. This paper addresses the critical need for safety measures in AI systems, especially ones that collaborate with human teams. We propose and evaluate three frameworks to enhance safety protocols in AI agent systems: an LLM-powered input-output filter, a safety agent integrated within the system, and a hierarchical delegation-based system with embedded safety checks. Our methodology involves implementing these frameworks and testing them against a set of unsafe agentic use cases, providing a comprehensive evaluation of their effectiveness in mitigating risks associated with AI agent deployment. We conclude that these frameworks can significantly strengthen the safety and security of AI agent systems, minimizing potential harmful actions or outputs. Our work contributes to the ongoing effort to create safe and reliable AI applications, particularly in automated operations, and provides a foundation for developing robust guardrails to ensure the responsible use of AI agents in real-world applications.
Read more9/16/2024