Safeguarding AI Agents: Developing and Analyzing Safety Architectures

0
🤖
Sign in to get full access
Overview
- Large language model-powered AI agents have demonstrated impressive capabilities in various applications
- However, these agents also come with inherent risks, including potential for unsafe or biased actions, vulnerability to adversarial attacks, lack of transparency, and tendency to generate hallucinations
- As AI agents become more prevalent, implementing effective safety protocols is increasingly important, especially for AI systems that collaborate with human teams
Plain English Explanation
Artificial intelligence (AI) agents powered by large language models have shown they can be very good at certain tasks, like writing and analysis. But these AI agents also have some risks. They could make unsafe or unfair decisions, be tricked by attackers, be hard to understand, and sometimes make up information that isn't real (hallucinations).
As AI agents become more common, especially in important areas like healthcare or finance, it's crucial to have good safety measures in place. This paper looks at three different ways to make AI agents safer and more reliable, especially when they're working together with humans. The researchers tested these approaches against some risky situations to see how well they could prevent harm.
The goal is to help create AI systems that are safe and trustworthy, so they can be used responsibly in the real world. This work contributes to the ongoing effort to develop robust safeguards for AI agents and ensure they're used in a way that benefits society.
Technical Explanation
The paper proposes and evaluates three frameworks to enhance safety protocols for AI agent systems:
-
LLM-powered input-output filter: This framework uses a large language model to analyze the inputs and outputs of the AI agent, looking for potential safety issues or biased content. It can block or modify problematic information before it's acted upon.
-
Safety agent integrated within the system: This is an additional AI agent that continuously monitors the primary AI agent's actions and decisions, intervening if it detects anything unsafe or unethical.
-
Hierarchical delegation-based system with embedded safety checks: In this approach, the primary AI agent delegates certain tasks to a hierarchy of subordinate AI agents, each with their own set of safety checks built-in. This creates multiple layers of oversight and security.
The researchers implemented these frameworks and tested them against a range of unsafe agentic use cases. They evaluated the effectiveness of each approach in mitigating the risks associated with AI agent deployment, such as harmful actions, biased outputs, and adversarial attacks.
Critical Analysis
The paper acknowledges that while these safety frameworks can significantly enhance the security of AI agent systems, they may not be able to completely eliminate all risks. There may still be edge cases or unforeseen scenarios where the AI agents could behave in unpredictable or unsafe ways.
Additionally, the researchers note that the implementation and effectiveness of these frameworks may vary depending on the specific AI agent system, the complexity of the task domain, and the potential for adversarial attacks. Further research and testing would be necessary to understand the limitations and edge cases of each approach.
It would also be valuable to explore how these safety frameworks could be adapted or combined to create even more robust and comprehensive safeguards for AI systems, especially as the technology continues to advance and become more prevalent in critical applications.
Conclusion
This paper presents a valuable contribution to the ongoing effort to create safe and reliable AI applications, particularly in automated operations. The proposed safety frameworks provide a solid foundation for developing robust guardrails to ensure the responsible use of AI agents in real-world applications.
As AI agents become more ubiquitous, the implementation of effective safety protocols will be crucial to mitigate the inherent risks associated with these systems. The insights and approaches outlined in this paper offer a promising path forward for enhancing the safety and security of AI-powered systems, ultimately paving the way for the responsible and beneficial deployment of these technologies in various industries and sectors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Safeguarding AI Agents: Developing and Analyzing Safety Architectures
Ishaan Domkundwar, Mukunda N S, Ishaan Bhola
AI agents, specifically powered by large language models, have demonstrated exceptional capabilities in various applications where precision and efficacy are necessary. However, these agents come with inherent risks, including the potential for unsafe or biased actions, vulnerability to adversarial attacks, lack of transparency, and tendency to generate hallucinations. As AI agents become more prevalent in critical sectors of the industry, the implementation of effective safety protocols becomes increasingly important. This paper addresses the critical need for safety measures in AI systems, especially ones that collaborate with human teams. We propose and evaluate three frameworks to enhance safety protocols in AI agent systems: an LLM-powered input-output filter, a safety agent integrated within the system, and a hierarchical delegation-based system with embedded safety checks. Our methodology involves implementing these frameworks and testing them against a set of unsafe agentic use cases, providing a comprehensive evaluation of their effectiveness in mitigating risks associated with AI agent deployment. We conclude that these frameworks can significantly strengthen the safety and security of AI agent systems, minimizing potential harmful actions or outputs. Our work contributes to the ongoing effort to create safe and reliable AI applications, particularly in automated operations, and provides a foundation for developing robust guardrails to ensure the responsible use of AI agents in real-world applications.
Read more9/16/2024

0
Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations
Chen Chen, Ziyao Liu, Weifeng Jiang, Si Qi Goh, Kwok-Yan Lam
AI Safety is an emerging area of critical importance to the safe adoption and deployment of AI systems. With the rapid proliferation of AI and especially with the recent advancement of Generative AI (or GAI), the technology ecosystem behind the design, development, adoption, and deployment of AI systems has drastically changed, broadening the scope of AI Safety to address impacts on public safety and national security. In this paper, we propose a novel architectural framework for understanding and analyzing AI Safety; defining its characteristics from three perspectives: Trustworthy AI, Responsible AI, and Safe AI. We provide an extensive review of current research and advancements in AI safety from these perspectives, highlighting their key challenges and mitigation approaches. Through examples from state-of-the-art technologies, particularly Large Language Models (LLMs), we present innovative mechanism, methodologies, and techniques for designing and testing AI safety. Our goal is to promote advancement in AI safety research, and ultimately enhance people's trust in digital transformation.
Read more9/14/2024
🤖
0
Security of AI Agents
Yifeng He, Ethan Wang, Yuyang Rong, Zifei Cheng, Hao Chen
The study and development of AI agents have been boosted by large language models. AI agents can function as intelligent assistants and complete tasks on behalf of their users with access to tools and the ability to execute commands in their environments, Through studying and experiencing the workflow of typical AI agents, we have raised several concerns regarding their security. These potential vulnerabilities are not addressed by the frameworks used to build the agents, nor by research aimed at improving the agents. In this paper, we identify and describe these vulnerabilities in detail from a system security perspective, emphasizing their causes and severe effects. Furthermore, we introduce defense mechanisms corresponding to each vulnerability with meticulous design and experiments to evaluate their viability. Altogether, this paper contextualizes the security issues in the current development of AI agents and delineates methods to make AI agents safer and more reliable.
Read more6/21/2024
2
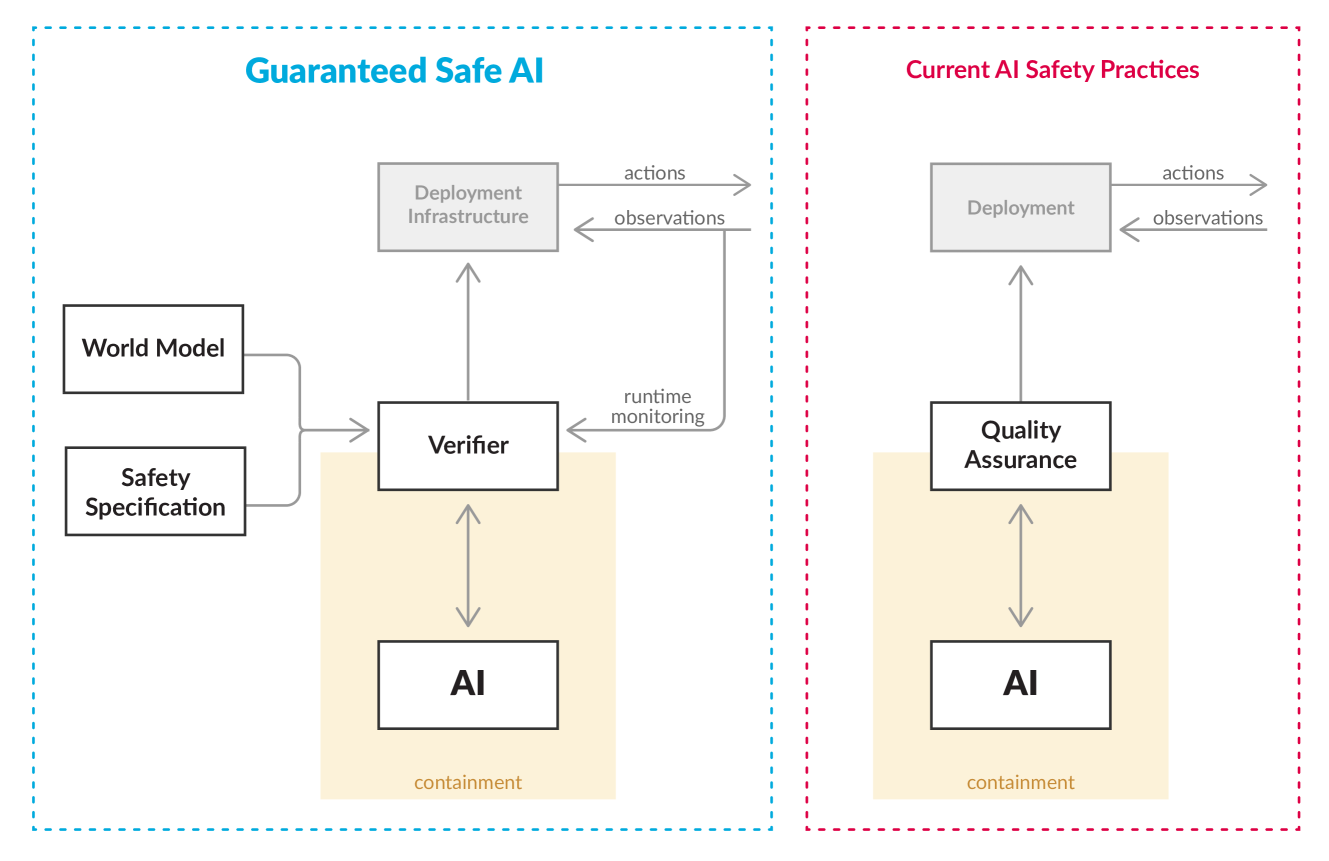
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Read more7/9/2024