Can Developers Prompt? A Controlled Experiment for Code Documentation Generation

0
🛸
Sign in to get full access
Overview
- Large language models (LLMs) have great potential to automate tedious development tasks like creating and maintaining code documentation.
- However, it's unclear how effectively developers can prompt LLMs to generate concise and useful documentation.
- The study reports on an experiment with 20 professionals and 30 computer science students tasked with generating code documentation for two Python functions.
- The experimental group used ad-hoc prompts in a ChatGPT-like Visual Studio Code extension, while the control group used a predefined few-shot prompt.
Plain English Explanation
The paper explores whether developers can effectively use large language models (LLMs) to automate the creation of code documentation. This is an important task, as maintaining detailed and accurate documentation is crucial for software development but can be time-consuming.
The researchers conducted an experiment to see how well developers could generate useful documentation by prompting an LLM-powered tool. They had two groups - one that could freely enter their own prompts, and one that used a predefined prompt. The goal was to see if the flexibility of ad-hoc prompting led to better results than a standardized approach.
The findings suggest that both professionals and students struggled to craft effective prompts. Students especially found the documentation generated from their own prompts to be less readable, concise, and helpful compared to the predefined prompt. Some professionals had more success by including the keyword "Docstring" in their prompts.
Overall, the participants recognized the LLM tool as a support system to iteratively refine the documentation, rather than expecting perfect outputs. The research highlights the need to better understand the prompting skills and preferences of developers for this type of task, and how to best support them.
Technical Explanation
The researchers conducted a controlled experiment to assess how effectively developers can prompt large language models (LLMs) to generate useful code documentation. They recruited 20 professional developers and 30 computer science students, and tasked them with creating documentation for two Python functions.
The experimental group used a ChatGPT-like extension of Visual Studio Code, where they could freely enter ad-hoc prompts to generate the documentation. The control group used a predefined few-shot prompt to complete the same task.
The results revealed that both professionals and students struggled to apply effective prompt engineering techniques. Students in particular perceived the documentation generated from their own prompts as significantly less readable, concise, and helpful compared to the documentation from the prepared prompt.
Some professionals were able to produce higher quality documentation by including the keyword "Docstring" in their ad-hoc prompts. However, participants in both groups rarely considered the output to be perfect, and instead viewed the LLM tool as a support system to iteratively refine the documentation.
The study highlights the need for further research to understand the prompting skills and preferences of developers for tasks like code documentation generation. It also suggests that developers may require additional support and guidance in formulating effective prompts, especially for less experienced users.
Critical Analysis
The paper provides valuable insights into the challenges developers face when trying to leverage large language models (LLMs) to automate code documentation tasks. The controlled experiment design and inclusion of both professional developers and computer science students offer a nuanced perspective on the issue.
One limitation of the study is the relatively small sample sizes, especially for the professional developer group. Expanding the participant pool could help confirm and further explore the observed trends.
Additionally, the paper does not delve deeply into the specific prompt engineering techniques that were successful or unsuccessful. More detailed analysis of the prompts used and their impact on the quality of the generated documentation could provide more actionable guidance for developers.
The researchers also acknowledge that their study focused on a narrow set of tasks and programming languages. Expanding the scope to explore a wider range of development activities and technologies could uncover additional insights and challenges.
Despite these limitations, the paper raises important questions about the role of LLMs in automating software engineering tasks and the support developers may need to effectively leverage these powerful tools. Encouraging critical thinking and further research in this area is crucial as the use of LLMs in software development continues to evolve.
Conclusion
This study sheds light on the potential and limitations of using large language models (LLMs) to automate the creation of code documentation. While LLMs hold great promise for streamlining tedious development tasks, the findings suggest that developers, especially less experienced ones, may struggle to craft effective prompts to generate high-quality documentation.
The research highlights the need for further exploration of the prompting skills and preferences of developers, as well as the development of tools and guidance to support them in leveraging LLMs for specific software engineering tasks. As the use of LLMs in software development continues to grow, understanding how to best integrate these technologies into the workflow of developers will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Can Developers Prompt? A Controlled Experiment for Code Documentation Generation
Hans-Alexander Kruse, Tim Puhlfur{ss}, Walid Maalej
Large language models (LLMs) bear great potential for automating tedious development tasks such as creating and maintaining code documentation. However, it is unclear to what extent developers can effectively prompt LLMs to create concise and useful documentation. We report on a controlled experiment with 20 professionals and 30 computer science students tasked with code documentation generation for two Python functions. The experimental group freely entered ad-hoc prompts in a ChatGPT-like extension of Visual Studio Code, while the control group executed a predefined few-shot prompt. Our results reveal that professionals and students were unaware of or unable to apply prompt engineering techniques. Especially students perceived the documentation produced from ad-hoc prompts as significantly less readable, less concise, and less helpful than documentation from prepared prompts. Some professionals produced higher quality documentation by just including the keyword Docstring in their ad-hoc prompts. While students desired more support in formulating prompts, professionals appreciated the flexibility of ad-hoc prompting. Participants in both groups rarely assessed the output as perfect. Instead, they understood the tools as support to iteratively refine the documentation. Further research is needed to understand which prompting skills and preferences developers have and which support they need for certain tasks.
Read more8/2/2024

0
Prompts Are Programs Too! Understanding How Developers Build Software Containing Prompts
Jenny T. Liang, Melissa Lin, Nikitha Rao, Brad A. Myers
The introduction of generative pre-trained models, like GPT-4, has introduced a phenomenon known as prompt engineering, whereby model users repeatedly write and revise prompts while trying to achieve a task. Using these AI models for intelligent features in software applications require using APIs that are controlled through developer-written prompts. These prompts have powered AI experiences in popular software products, potentially reaching millions of users. Despite the growing impact of prompt-powered software, little is known about its development process and its relationship to programming. In this work, we argue that some forms of prompts are programs, and that the development of prompts is a distinct phenomenon in programming. We refer to this phenomenon as prompt programming. To this end, we develop an understanding of prompt programming using Straussian grounded theory through interviews with 20 developers engaged in prompt development across a variety of contexts, models, domains, and prompt complexities. Through this study, we contribute 14 observations about prompt programming. For example, rather than building mental models of code, prompt programmers develop mental models of the FM's behavior on the prompt and its unique qualities by interacting with the model. While prior research has shown that experts have well-formed mental models, we find that prompt programmers who have developed dozens of prompts, each with many iterations, still struggle to develop reliable mental models. This contributes to a rapid and unsystematic development process. Taken together, our observations indicate that prompt programming is significantly different from traditional software development, motivating the creation of tools to support prompt programming. Our findings have implications for software engineering practitioners, educators, and researchers.
Read more9/20/2024

0
How Beginning Programmers and Code LLMs (Mis)read Each Other
Sydney Nguyen, Hannah McLean Babe, Yangtian Zi, Arjun Guha, Carolyn Jane Anderson, Molly Q Feldman
Generative AI models, specifically large language models (LLMs), have made strides towards the long-standing goal of text-to-code generation. This progress has invited numerous studies of user interaction. However, less is known about the struggles and strategies of non-experts, for whom each step of the text-to-code problem presents challenges: describing their intent in natural language, evaluating the correctness of generated code, and editing prompts when the generated code is incorrect. This paper presents a large-scale controlled study of how 120 beginning coders across three academic institutions approach writing and editing prompts. A novel experimental design allows us to target specific steps in the text-to-code process and reveals that beginners struggle with writing and editing prompts, even for problems at their skill level and when correctness is automatically determined. Our mixed-methods evaluation provides insight into student processes and perceptions with key implications for non-expert Code LLM use within and outside of education.
Read more7/9/2024
0
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
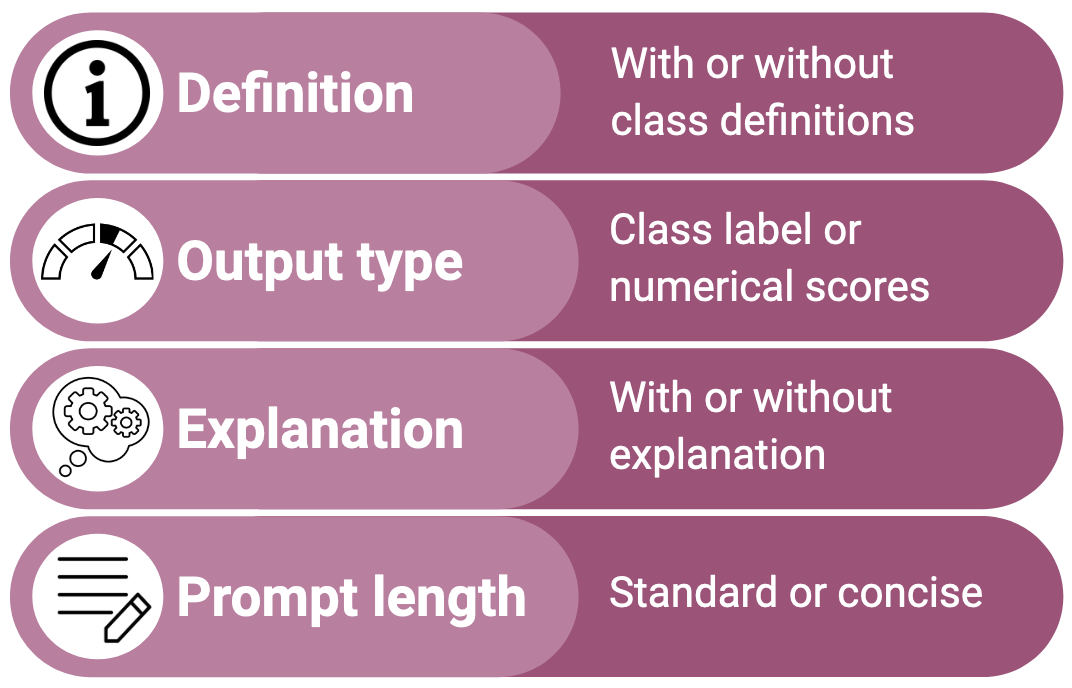
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
Read more6/19/2024