How Beginning Programmers and Code LLMs (Mis)read Each Other

0

Sign in to get full access
Overview
- The paper examines the communication challenges between beginning programmers and code language models (LLMs) when they try to understand each other.
- It explores how misunderstandings can arise due to differences in technical knowledge, communication styles, and expectations.
- The research aims to shed light on these issues to improve the effectiveness of LLMs in computer science education.
Plain English Explanation
When people new to programming try to use AI language models that can generate code, they often struggle to communicate effectively. The paper explores why this happens and how to address the problem.
The main issue is that beginners and code LLMs have very different levels of understanding when it comes to programming concepts and terminology. Beginners may use vague or imprecise language, while the LLMs expect very specific instructions. This can lead to mismatched expectations and frustrating experiences on both sides.
The research aims to shed light on these communication challenges so that LLMs can be designed to better support novice programmers. By understanding how they misread each other, the hope is to create AI assistants that are more effective at helping beginners learn to code.
Technical Explanation
The paper begins by reviewing the state of research on using large language models (LLMs) for code generation and computer science education. It identifies a gap in understanding the communication challenges that arise between novice programmers and these AI systems.
To explore this issue, the researchers conducted a series of experiments. They had beginning programming students interact with a code-generating LLM to complete various tasks. By analyzing the transcripts of these interactions, they were able to identify common patterns of misunderstanding on both sides.
The key findings include:
- Beginners often used vague, high-level language that the LLM struggled to interpret correctly.
- Conversely, the LLM's responses sometimes assumed a level of technical knowledge that the students did not possess.
- There were also differences in communication styles, with the LLM providing very literal, formal responses, while the students used more natural language.
Based on these insights, the researchers propose design recommendations to enhance the interactive experience between novice programmers and code LLMs. This includes strategies for improving the model's ability to understand and respond to beginner-level language.
Critical Analysis
The paper provides valuable insights into an important challenge facing the use of AI in computer science education. By highlighting the communication gaps between beginners and code LLMs, it points to areas for further research and development.
However, the study is limited in scope, focusing only on a single LLM interacting with a small sample of students. Additional research would be needed to understand how these dynamics play out with a wider range of LLM architectures and user populations.
The paper also does not delve deeply into potential solutions beyond high-level design recommendations. More work is needed to translate these ideas into practical, scalable implementations that can be effectively deployed in educational settings.
Furthermore, the paper does not address potential biases or ethical considerations that may arise as these AI systems become more integrated into the learning process. It will be important for future research to consider the broader implications and potential risks of using LLMs in computer science education.
Conclusion
This paper sheds important light on the communication challenges between beginning programmers and code-generating language models. By understanding how these two groups misread each other, researchers can work to design more effective AI assistants for computer science education.
Addressing these issues has the potential to make programming more accessible and engaging for novice learners, ultimately supporting the development of crucial technical skills. As LLMs continue to advance, this research highlights the importance of designing these systems with the needs of end-users in mind.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Beginning Programmers and Code LLMs (Mis)read Each Other
Sydney Nguyen, Hannah McLean Babe, Yangtian Zi, Arjun Guha, Carolyn Jane Anderson, Molly Q Feldman
Generative AI models, specifically large language models (LLMs), have made strides towards the long-standing goal of text-to-code generation. This progress has invited numerous studies of user interaction. However, less is known about the struggles and strategies of non-experts, for whom each step of the text-to-code problem presents challenges: describing their intent in natural language, evaluating the correctness of generated code, and editing prompts when the generated code is incorrect. This paper presents a large-scale controlled study of how 120 beginning coders across three academic institutions approach writing and editing prompts. A novel experimental design allows us to target specific steps in the text-to-code process and reveals that beginners struggle with writing and editing prompts, even for problems at their skill level and when correctness is automatically determined. Our mixed-methods evaluation provides insight into student processes and perceptions with key implications for non-expert Code LLM use within and outside of education.
Read more7/9/2024
📉
0
CSEPrompts: A Benchmark of Introductory Computer Science Prompts
Nishat Raihan, Dhiman Goswami, Sadiya Sayara Chowdhury Puspo, Christian Newman, Tharindu Ranasinghe, Marcos Zampieri
Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
Read more4/5/2024

0
Enhancing Computer Programming Education with LLMs: A Study on Effective Prompt Engineering for Python Code Generation
Tianyu Wang, Nianjun Zhou, Zhixiong Chen
Large language models (LLMs) and prompt engineering hold significant potential for advancing computer programming education through personalized instruction. This paper explores this potential by investigating three critical research questions: the systematic categorization of prompt engineering strategies tailored to diverse educational needs, the empowerment of LLMs to solve complex problems beyond their inherent capabilities, and the establishment of a robust framework for evaluating and implementing these strategies. Our methodology involves categorizing programming questions based on educational requirements, applying various prompt engineering strategies, and assessing the effectiveness of LLM-generated responses. Experiments with GPT-4, GPT-4o, Llama3-8b, and Mixtral-8x7b models on datasets such as LeetCode and USACO reveal that GPT-4o consistently outperforms others, particularly with the multi-step prompt strategy. The results show that tailored prompt strategies significantly enhance LLM performance, with specific strategies recommended for foundational learning, competition preparation, and advanced problem-solving. This study underscores the crucial role of prompt engineering in maximizing the educational benefits of LLMs. By systematically categorizing and testing these strategies, we provide a comprehensive framework for both educators and students to optimize LLM-based learning experiences. Future research should focus on refining these strategies and addressing current LLM limitations to further enhance educational outcomes in computer programming instruction.
Read more7/9/2024
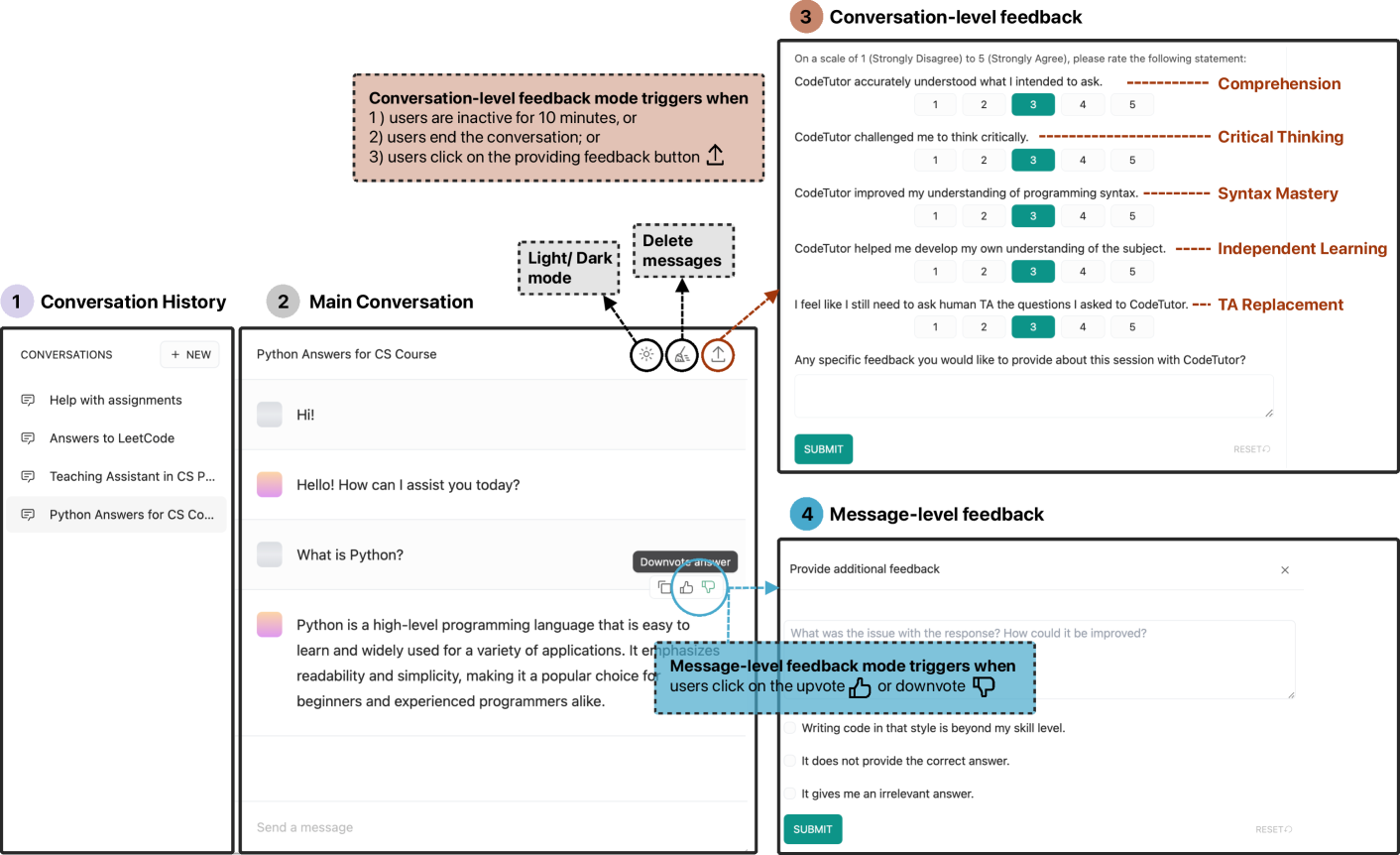
0
Evaluating the Effectiveness of LLMs in Introductory Computer Science Education: A Semester-Long Field Study
Wenhan Lyu (Rachel), Yimeng Wang (Rachel), Tingting (Rachel), Chung, Yifan Sun, Yixuan Zhang
The integration of AI assistants, especially through the development of Large Language Models (LLMs), into computer science education has sparked significant debate. An emerging body of work has looked into using LLMs in education, but few have examined the impacts of LLMs on students in entry-level programming courses, particularly in real-world contexts and over extended periods. To address this research gap, we conducted a semester-long, between-subjects study with 50 students using CodeTutor, an LLM-powered assistant developed by our research team. Our study results show that students who used CodeTutor (the experimental group) achieved statistically significant improvements in their final scores compared to peers who did not use the tool (the control group). Within the experimental group, those without prior experience with LLM-powered tools demonstrated significantly greater performance gain than their counterparts. We also found that students expressed positive feedback regarding CodeTutor's capability, though they also had concerns about CodeTutor's limited role in developing critical thinking skills. Over the semester, students' agreement with CodeTutor's suggestions decreased, with a growing preference for support from traditional human teaching assistants. Our analysis further reveals that the quality of user prompts was significantly correlated with CodeTutor's response effectiveness. Building upon our results, we discuss the implications of our findings for integrating Generative AI literacy into curricula to foster critical thinking skills and turn to examining the temporal dynamics of user engagement with LLM-powered tools. We further discuss the discrepancy between the anticipated functions of tools and students' actual capabilities, which sheds light on the need for tailored strategies to improve educational outcomes.
Read more5/6/2024