Can Differentiable Decision Trees Enable Interpretable Reward Learning from Human Feedback?

0

Sign in to get full access
Overview
- Explores the use of differentiable decision trees to learn interpretable reward functions that can model human preferences and intent
- Addresses the challenge of many existing frameworks using black-box methods that are difficult to interpret
- Proposes a novel approach to learn reward functions that are both expressive and interpretable
Plain English Explanation
Reward functions are used in reinforcement learning to guide an agent's behavior. However, many existing reward functions are "black-box" models, meaning they are complex and difficult for humans to understand. This paper investigates the use of differentiable decision trees as a way to learn reward functions that are both expressive and interpretable.
The key idea is that decision trees, which use a series of simple if-then-else rules, can provide a clear and intuitive way to represent human preferences. By making these decision trees differentiable, the researchers can use machine learning techniques to automatically learn the structure and parameters of the trees from data.
The advantage of this approach is that the resulting reward function is not a black box, but a set of easily-understood rules that can be inspected and modified by humans. This could be particularly useful in applications where it's important to understand and align the reward function with human values, such as in human-robot interaction or AI safety.
Technical Explanation
The paper proposes a novel framework for learning interpretable reward functions using differentiable decision trees. The key components are:
-
Differentiable Decision Trees: The researchers introduce a new type of decision tree that is fully differentiable, allowing the structure and parameters of the tree to be optimized using gradient-based methods.
-
Reward Function Representation: The reward function is represented as a differentiable decision tree, where each leaf node contains a scalar reward value and the internal nodes represent binary splitting decisions based on the input features.
-
Learning Procedure: The researchers use a two-stage training process. First, they initialize the decision tree structure using a greedy algorithm. Then, they fine-tune the tree parameters and structure using gradient-based optimization to minimize a loss function that encourages the tree to match some target reward function.
-
Experiments: The authors evaluate their approach on several benchmark tasks, including learning reward functions for simple grid-world environments and more complex robotic manipulation tasks. They compare the interpretability and performance of their differentiable decision trees to other reward modeling techniques, such as neural networks.
The key insights from the paper are:
- Differentiable decision trees can effectively learn expressive and interpretable reward functions from data.
- The interpretability of the learned reward functions allows for easier inspection and understanding of the agent's objectives.
- The proposed approach can outperform black-box reward modeling techniques in terms of both interpretability and task performance.
Critical Analysis
The paper presents a promising approach for learning interpretable reward functions, but it also has some potential limitations:
- The experiments are limited to relatively simple environments, and it's unclear how well the approach would scale to more complex real-world scenarios.
- The paper does not address the challenge of learning reward functions when the true reward function is unknown or difficult to specify, which is a common problem in practice.
- The authors do not explore the robustness of the learned reward functions to distributional shift or adversarial perturbations, which is an important consideration for safety-critical applications.
Overall, the paper makes a valuable contribution by demonstrating the potential of differentiable decision trees for learning interpretable reward functions. However, further research is needed to address the limitations and explore the real-world applicability of this approach.
Conclusion
This paper presents a novel framework for learning interpretable reward functions using differentiable decision trees. By representing the reward function as a set of easily-understood if-then-else rules, the approach can provide valuable insights into the agent's objectives and potentially improve the alignment between the agent's behavior and human values. While the current evaluation is limited, the proposed approach represents an important step towards more transparent and interpretable reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can Differentiable Decision Trees Enable Interpretable Reward Learning from Human Feedback?
Akansha Kalra, Daniel S. Brown
Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for capturing human intent to alleviate the challenges of hand-crafting the reward values. Despite the increasing interest in RLHF, most works learn black box reward functions that while expressive are difficult to interpret and often require running the whole costly process of RL before we can even decipher if these frameworks are actually aligned with human preferences. We propose and evaluate a novel approach for learning expressive and interpretable reward functions from preferences using Differentiable Decision Trees (DDTs). Our experiments across several domains, including CartPole, Visual Gridworld environments and Atari games, provide evidence that the tree structure of our learned reward function is useful in determining the extent to which the reward function is aligned with human preferences. We also provide experimental evidence that not only shows that reward DDTs can often achieve competitive RL performance when compared with larger capacity deep neural network reward functions but also demonstrates the diagnostic utility of our framework in checking alignment of learned reward functions. We also observe that the choice between soft and hard (argmax) output of reward DDT reveals a tension between wanting highly shaped rewards to ensure good RL performance, while also wanting simpler, more interpretable rewards. Videos and code, are available at: https://sites.google.com/view/ddt-rlhf
Read more9/9/2024

0
Optimizing Interpretable Decision Tree Policies for Reinforcement Learning
Daniel Vos, Sicco Verwer
Reinforcement learning techniques leveraging deep learning have made tremendous progress in recent years. However, the complexity of neural networks prevents practitioners from understanding their behavior. Decision trees have gained increased attention in supervised learning for their inherent interpretability, enabling modelers to understand the exact prediction process after learning. This paper considers the problem of optimizing interpretable decision tree policies to replace neural networks in reinforcement learning settings. Previous works have relaxed the tree structure, restricted to optimizing only tree leaves, or applied imitation learning techniques to approximately copy the behavior of a neural network policy with a decision tree. We propose the Decision Tree Policy Optimization (DTPO) algorithm that directly optimizes the complete decision tree using policy gradients. Our technique uses established decision tree heuristics for regression to perform policy optimization. We empirically show that DTPO is a competitive algorithm compared to imitation learning algorithms for optimizing decision tree policies in reinforcement learning.
Read more8/22/2024
🤿
0
Deep Reinforcement Learning from Hierarchical Preference Design
Alexander Bukharin, Yixiao Li, Pengcheng He, Tuo Zhao
Reward design is a fundamental, yet challenging aspect of reinforcement learning (RL). Researchers typically utilize feedback signals from the environment to handcraft a reward function, but this process is not always effective due to the varying scale and intricate dependencies of the feedback signals. This paper shows by exploiting certain structures, one can ease the reward design process. Specifically, we propose a hierarchical reward modeling framework -- HERON for scenarios: (I) The feedback signals naturally present hierarchy; (II) The reward is sparse, but with less important surrogate feedback to help policy learning. Both scenarios allow us to design a hierarchical decision tree induced by the importance ranking of the feedback signals to compare RL trajectories. With such preference data, we can then train a reward model for policy learning. We apply HERON to several RL applications, and we find that our framework can not only train high performing agents on a variety of difficult tasks, but also provide additional benefits such as improved sample efficiency and robustness. Our code is available at url{https://github.com/abukharin3/HERON}.
Read more6/11/2024
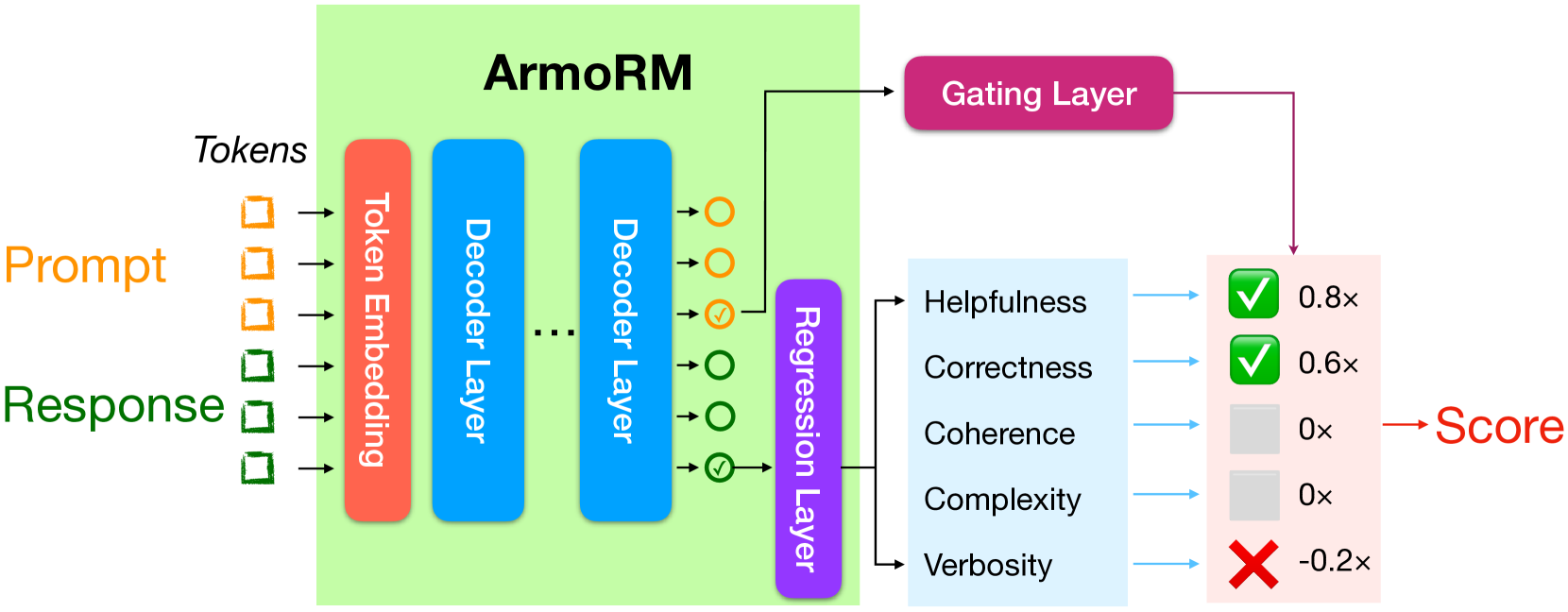
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024