Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts

0
Sign in to get full access
Overview
- This paper presents a novel approach for learning interpretable preferences through multi-objective reward modeling and mixture-of-experts techniques.
- The key idea is to model the human's preferences as a mixture of multiple objective functions, each of which captures a distinct aspect of the preferences.
- This allows the system to learn preferences that are more transparent and easier for humans to understand, compared to a single monolithic reward function.
Plain English Explanation
The paper explores a new way to model and understand a person's preferences, such as the preferences they have when making decisions. Traditionally, a single reward function is used to capture a person's preferences, but this can be difficult for humans to interpret and understand.
Instead, the researchers propose modeling a person's preferences as a mixture of multiple objective functions, each of which represents a different aspect of their preferences. For example, one objective function might capture the person's preference for efficiency, while another might capture their preference for fairness.
By breaking down the preferences into multiple components, the system can learn preferences that are more transparent and easier for humans to understand. This could be useful in applications like RewardBench, where we want to align AI systems with human preferences in an interpretable way.
The paper also explores how techniques like Mixture-of-Experts can be used to effectively learn these multi-objective preference models, building on related work in reward modeling and domain knowledge incorporation.
Technical Explanation
The key technical contributions of the paper are:
-
Multi-Objective Reward Modeling: The authors propose modeling the human's preferences as a mixture of multiple objective functions, each of which captures a distinct aspect of the preferences. This allows the system to learn preferences that are more interpretable than a single monolithic reward function.
-
Mixture-of-Experts Approach: The authors leverage a Mixture-of-Experts (MoE) architecture to effectively learn the multi-objective preference model. This allows the system to adaptively combine the different objective functions based on the context.
-
Experiments and Insights: The authors evaluate their approach on a range of simulated tasks as well as multi-turn preference elicitation. Their results demonstrate that the multi-objective approach can indeed lead to more interpretable and effective preference models compared to baselines.
Critical Analysis
The paper presents a promising approach for learning interpretable preferences, but there are a few potential limitations and areas for further research:
-
Scalability and Complexity: While the multi-objective approach may improve interpretability, it also introduces additional complexity in terms of learning and representing the mixture of objectives. Scaling this approach to real-world, high-dimensional problems may pose challenges.
-
Evaluation and Generalization: The experiments in the paper are focused on simulated domains and relatively simple preference elicitation tasks. More research is needed to understand how well the approach generalizes to complex, real-world decision-making scenarios.
-
Human Factors: The paper does not extensively explore how the interpretability of the preference models is perceived and valued by human users. Incorporating more direct user feedback and evaluation could help refine the approach.
-
Ethical Considerations: As with any preference learning system, there are important ethical considerations around how the preferences are modeled and applied, especially in high-stakes domains. Further research is needed to address these issues.
Conclusion
This paper presents a novel approach for learning interpretable preferences by modeling them as a mixture of multiple objective functions. By breaking down the preferences into more transparent components, the system can learn models that are easier for humans to understand and interact with.
While there are some potential limitations and areas for future research, this work represents an important step towards developing AI systems that can effectively align with human values and preferences in a way that is clear and interpretable. As AI becomes more pervasive in decision-making, techniques like this will be crucial for ensuring that the systems remain accountable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
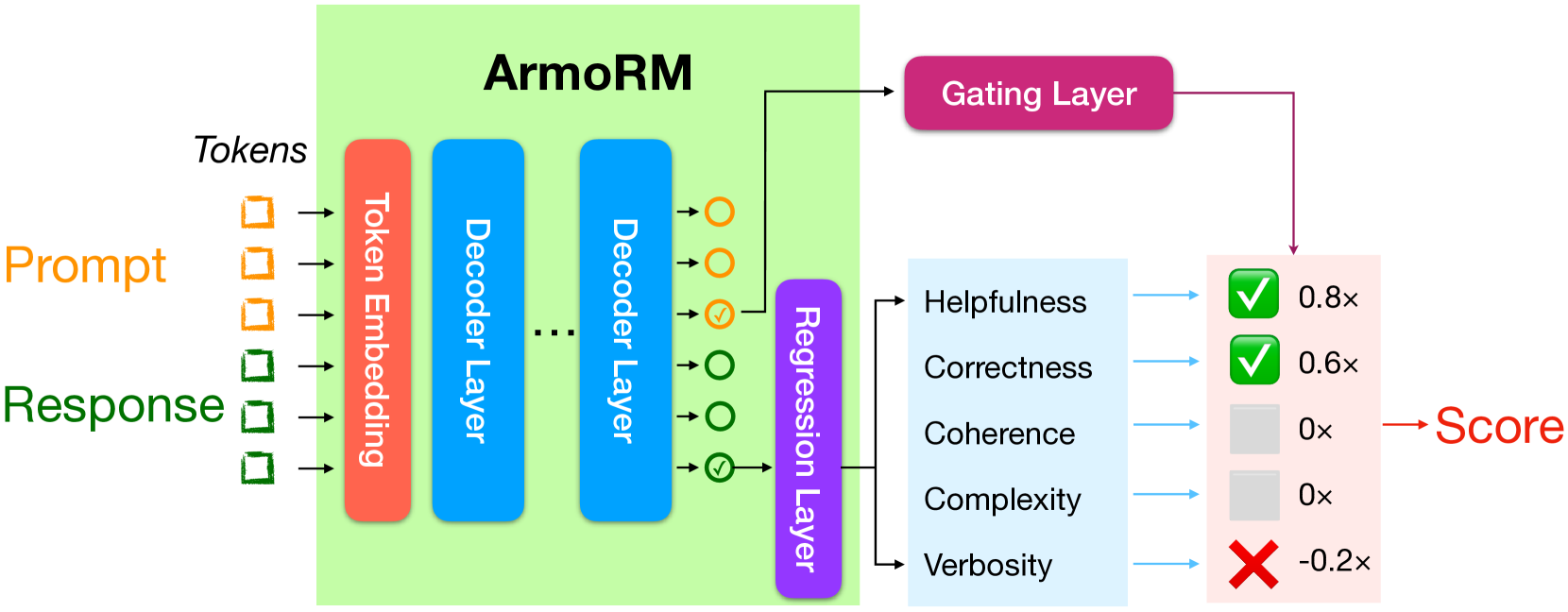
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024

0
RewardBench: Evaluating Reward Models for Language Modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi
Reward models (RMs) are at the crux of successfully using RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. Resources for reward model training and understanding are sparse in the nascent open-source community around them. To enhance scientific understanding of reward models, we present RewardBench, a benchmark dataset and code-base for evaluation. The RewardBench dataset is a collection of prompt-chosen-rejected trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We create specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO). We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Read more6/11/2024
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
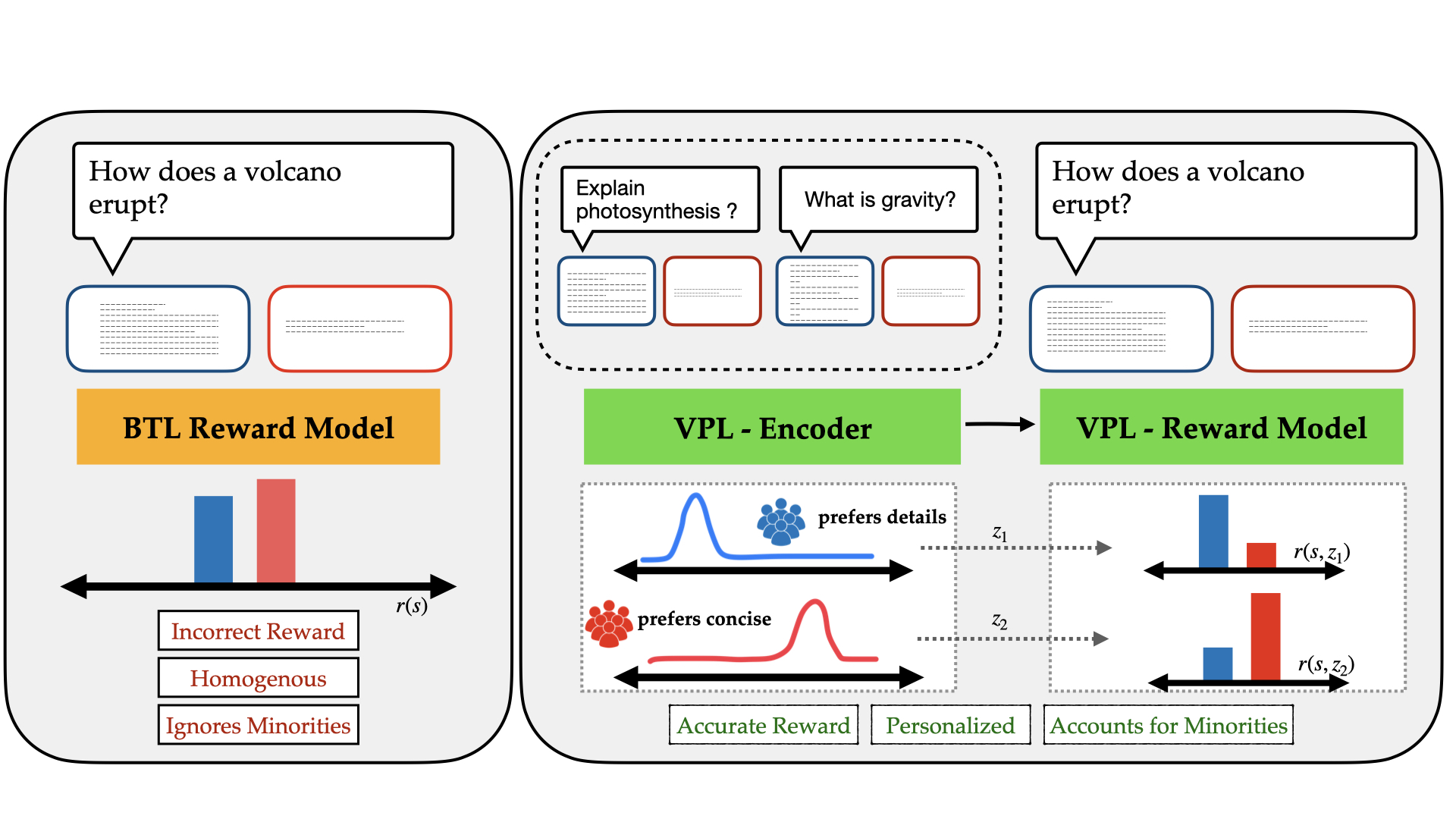
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024
0
Towards Understanding the Influence of Reward Margin on Preference Model Performance
Bowen Qin, Duanyu Feng, Xi Yang
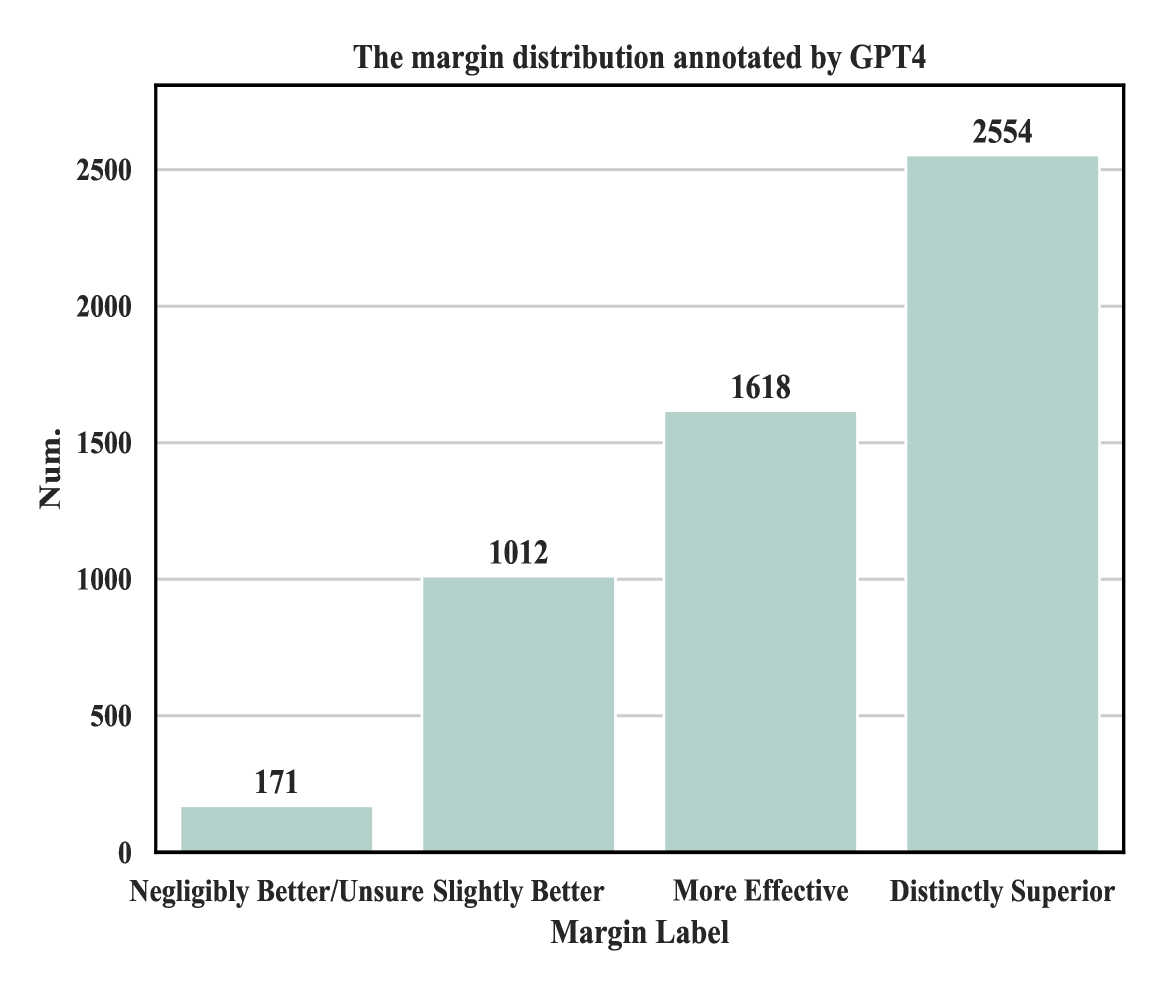
Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for the training of language models. However, the process of using RLHF to develop a language model that is well-aligned presents challenges, especially when it comes to optimizing the reward model. Our research has found that existing reward models, when trained using the traditional ranking objective based on human preference data, often struggle to effectively distinguish between responses that are more or less favorable in real-world scenarios. To bridge this gap, our study introduces a novel method to estimate the preference differences without the need for detailed, exhaustive labels from human annotators. Our experimental results provide empirical evidence that incorporating margin values into the training process significantly improves the effectiveness of reward models. This comparative analysis not only demonstrates the superiority of our approach in terms of reward prediction accuracy but also highlights its effectiveness in practical applications.
Read more4/9/2024