Deep Reinforcement Learning from Hierarchical Preference Design

0
🤿
Sign in to get full access
Overview
- Reinforcement learning (RL) is a powerful technique, but designing effective reward functions can be challenging
- This paper proposes a hierarchical reward modeling framework called HERON to ease the reward design process in certain scenarios
- HERON leverages the structure of feedback signals, such as natural hierarchies or sparse rewards with less important surrogate feedback, to create a hierarchical decision tree for comparing RL trajectories
- The paper demonstrates the benefits of HERON, including improved sample efficiency and robustness, across various RL applications
Plain English Explanation
Reinforcement learning is a technique used to train intelligent agents, like robots or computer programs, to perform tasks by trial and error. The key to this approach is defining a reward function that tells the agent how well it's doing and what it should aim for. However, designing a good reward function can be tricky, as the feedback signals from the environment may have complex dependencies or varying scales.
The researchers behind this paper recognized that in some cases, the feedback signals have a natural hierarchy or structure. For example, in a game, the final score might be the most important feedback, but there could also be intermediate feedback signals, like the number of points scored or the time taken to complete a level. HERON is a framework that allows the researchers to exploit this kind of structure to make the reward design process easier.
The idea behind HERON is to create a hierarchical decision tree that compares different possible paths (or "trajectories") the agent could take, based on the importance of the feedback signals. With this preference data, the researchers can then train a reward model that the agent can use to learn the task effectively.
The paper shows that HERON can help train high-performing agents on a variety of challenging tasks, while also providing benefits like improved sample efficiency and robustness. The researchers have made their code available for others to use and build upon.
Technical Explanation
The paper introduces a hierarchical reward modeling framework called HERON, which aims to ease the reward design process in reinforcement learning (RL) by exploiting certain structures in the feedback signals.
The researchers identified two specific scenarios where HERON can be particularly useful:
-
Hierarchical Feedback Signals: In some cases, the feedback signals from the environment naturally present a hierarchy, where some signals are more important than others. HERON can leverage this structure to create a hierarchical decision tree for comparing RL trajectories.
-
Sparse Rewards with Surrogate Feedback: When the reward signal is sparse (i.e., only available at certain points), HERON can utilize less important "surrogate" feedback signals to help guide the policy learning process.
By utilizing the preference data generated from the hierarchical decision tree, HERON can then train a reward model that the RL agent can use to learn the task effectively. The researchers demonstrate the benefits of HERON, including improved sample efficiency and robustness, across several RL applications.
The key elements of HERON include:
- Hierarchical Decision Tree: HERON creates a decision tree that compares RL trajectories based on the importance ranking of the feedback signals.
- Reward Model Training: With the preference data from the decision tree, HERON trains a reward model that the RL agent can use for policy learning.
- RL Agent Training: The trained reward model is then used to train the RL agent to perform the desired task.
The researchers evaluate HERON on various RL tasks and find that it can not only train high-performing agents, but also provide benefits like improved sample efficiency and robustness.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of reward design in reinforcement learning. By leveraging the structure of feedback signals, HERON offers a way to simplify the reward design process in certain scenarios.
One potential limitation of the HERON framework is that it relies on the feedback signals having a clear hierarchy or structure. In some cases, the relationships between feedback signals may be more complex or ambiguous, which could make it difficult to construct a meaningful hierarchical decision tree.
Additionally, the paper does not explore how HERON would perform in situations where the feedback signals themselves are noisy or unreliable. It would be interesting to see how the framework handles such scenarios and whether it can still provide the reported benefits of improved sample efficiency and robustness.
Another area for further research could be investigating how HERON's performance compares to other reward modeling approaches in the literature, such as those that rely on diverse human preferences or adaptive preference scaling.
Overall, the HERON framework represents an important step forward in simplifying the reward design process for reinforcement learning, and the paper presents a well-designed study to demonstrate its capabilities. Continued research in this direction could lead to further advancements in making RL more accessible and effective for a wider range of applications.
Conclusion
This paper introduces a novel hierarchical reward modeling framework called HERON, which aims to ease the reward design process in reinforcement learning. By exploiting the structure of feedback signals, HERON can create a hierarchical decision tree to compare RL trajectories and train a reward model for effective policy learning.
The researchers demonstrate the benefits of HERON, including improved sample efficiency and robustness, across various RL applications. This work represents an important advancement in reinforcement learning, as it provides a systematic way to address the challenge of reward design, which is crucial for the successful deployment of RL systems in real-world scenarios.
The HERON framework opens up new research directions, such as exploring its performance in more complex or noisy feedback environments, and comparing it to other reward modeling approaches. As the field of reinforcement learning continues to evolve, techniques like HERON will play a vital role in making RL more accessible and effective for a wide range of applications, from robotics and game AI to decision-making systems and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Deep Reinforcement Learning from Hierarchical Preference Design
Alexander Bukharin, Yixiao Li, Pengcheng He, Tuo Zhao
Reward design is a fundamental, yet challenging aspect of reinforcement learning (RL). Researchers typically utilize feedback signals from the environment to handcraft a reward function, but this process is not always effective due to the varying scale and intricate dependencies of the feedback signals. This paper shows by exploiting certain structures, one can ease the reward design process. Specifically, we propose a hierarchical reward modeling framework -- HERON for scenarios: (I) The feedback signals naturally present hierarchy; (II) The reward is sparse, but with less important surrogate feedback to help policy learning. Both scenarios allow us to design a hierarchical decision tree induced by the importance ranking of the feedback signals to compare RL trajectories. With such preference data, we can then train a reward model for policy learning. We apply HERON to several RL applications, and we find that our framework can not only train high performing agents on a variety of difficult tasks, but also provide additional benefits such as improved sample efficiency and robustness. Our code is available at url{https://github.com/abukharin3/HERON}.
Read more6/11/2024
🔍
0
Tiered Reward: Designing Rewards for Specification and Fast Learning of Desired Behavior
Zhiyuan Zhou, Shreyas Sundara Raman, Henry Sowerby, Michael L. Littman
Reinforcement-learning agents seek to maximize a reward signal through environmental interactions. As humans, our job in the learning process is to design reward functions to express desired behavior and enable the agent to learn such behavior swiftly. However, designing good reward functions to induce the desired behavior is generally hard, let alone the question of which rewards make learning fast. In this work, we introduce a family of a reward structures we call Tiered Reward that addresses both of these questions. We consider the reward-design problem in tasks formulated as reaching desirable states and avoiding undesirable states. To start, we propose a strict partial ordering of the policy space to resolve trade-offs in behavior preference. We prefer policies that reach the good states faster and with higher probability while avoiding the bad states longer. Next, we introduce Tiered Reward, a class of environment-independent reward functions and show it is guaranteed to induce policies that are Pareto-optimal according to our preference relation. Finally, we demonstrate that Tiered Reward leads to fast learning with multiple tabular and deep reinforcement-learning algorithms.
Read more8/2/2024
🏅
0
Reinforcement Learning from Diverse Human Preferences
Wanqi Xue, Bo An, Shuicheng Yan, Zhongwen Xu
The complexity of designing reward functions has been a major obstacle to the wide application of deep reinforcement learning (RL) techniques. Describing an agent's desired behaviors and properties can be difficult, even for experts. A new paradigm called reinforcement learning from human preferences (or preference-based RL) has emerged as a promising solution, in which reward functions are learned from human preference labels among behavior trajectories. However, existing methods for preference-based RL are limited by the need for accurate oracle preference labels. This paper addresses this limitation by developing a method for crowd-sourcing preference labels and learning from diverse human preferences. The key idea is to stabilize reward learning through regularization and correction in a latent space. To ensure temporal consistency, a strong constraint is imposed on the reward model that forces its latent space to be close to the prior distribution. Additionally, a confidence-based reward model ensembling method is designed to generate more stable and reliable predictions. The proposed method is tested on a variety of tasks in DMcontrol and Meta-world and has shown consistent and significant improvements over existing preference-based RL algorithms when learning from diverse feedback, paving the way for real-world applications of RL methods.
Read more5/9/2024
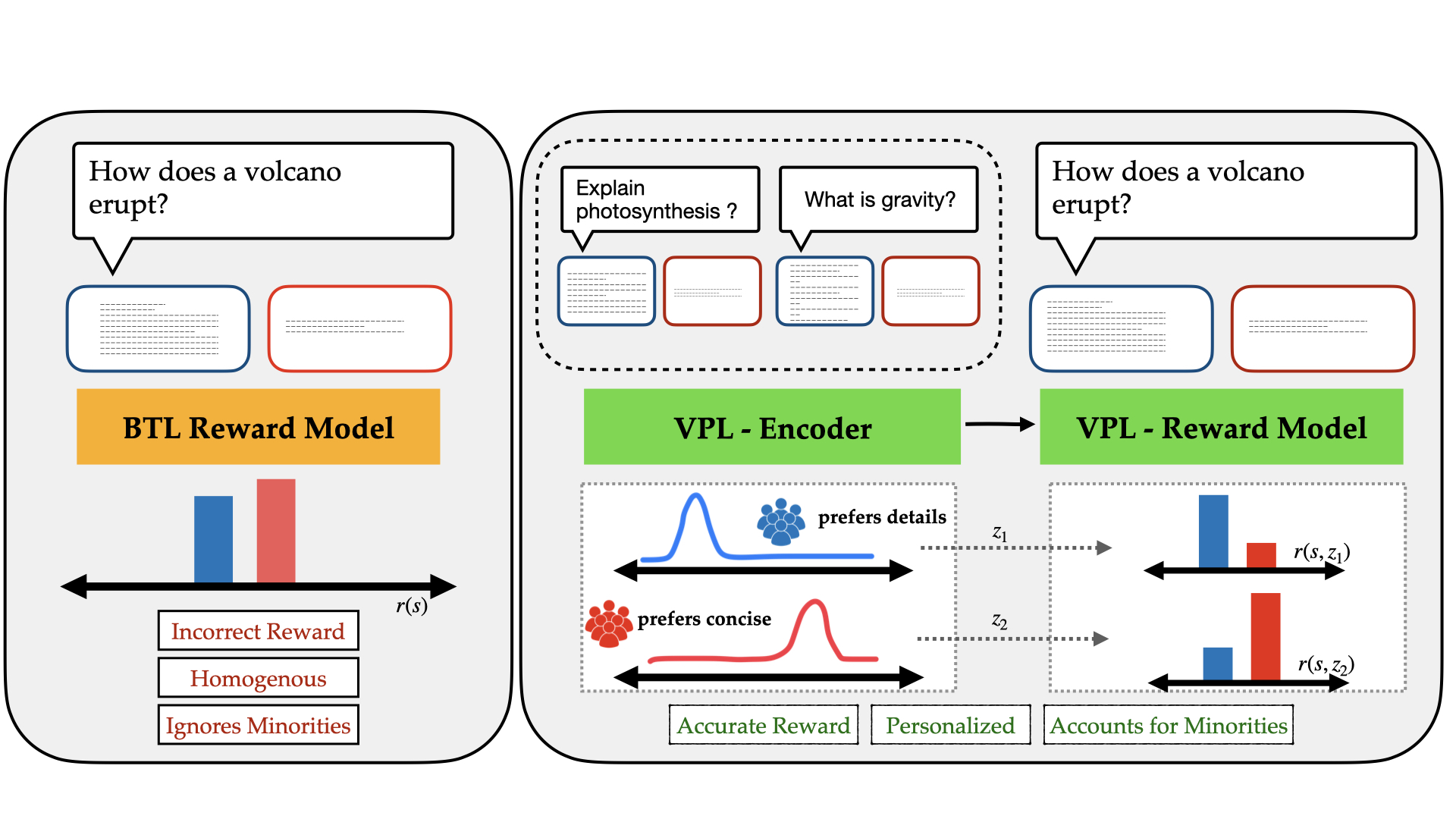
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024