Can Humans Identify Domains?

0

Sign in to get full access
Overview
- This paper investigates whether humans can accurately identify the genre and topic of text documents.
- The study compares human performance to machine learning models on the same classification tasks.
- The findings have implications for understanding human cognitive capabilities and the limitations of current AI systems.
Plain English Explanation
Imagine you're reading a short passage of text. Even without knowing exactly what the text is about, you can often get a sense of the general topic or genre. For example, you might recognize that a passage is discussing a scientific topic, describing a personal experience, or debating a political issue.
This paper explores how well humans perform at this kind of text classification task, compared to machine learning algorithms. The researchers asked participants to read short text samples and indicate the genre (e.g. news article, academic paper, product review) and topic (e.g. healthcare, sports, politics). They then compared the human responses to the classifications produced by state-of-the-art AI models.
The key finding is that humans are surprisingly good at this task, often outperforming the AI systems. This suggests that humans have developed sophisticated cognitive abilities to rapidly understand and categorize text, abilities that current AI struggle to match. At the same time, the results also reveal the limitations of human perception - even expert participants made mistakes and showed biases in their classifications.
Understanding the strengths and weaknesses of human versus machine text understanding is important for developing more intelligent and trustworthy AI systems. It also sheds light on the remarkable flexibility and adaptability of the human mind when it comes to processing and making sense of language.
Technical Explanation
The paper reports on a series of experiments that compare human and machine performance on genre and topic classification of text documents. The researchers collected a diverse corpus of over 200,000 text samples across 12 genres and 12 topics. They then recruited human participants to read and classify random samples from this corpus along both the genre and topic dimensions.
Concurrently, the researchers trained state-of-the-art machine learning models, including transformer-based language models, to perform the same classification tasks on the same text corpus. They evaluated the human and machine performance using standard metrics like accuracy, precision, and F1-score.
The key finding is that humans significantly outperformed the AI models on both the genre and topic classification tasks. Humans achieved accuracy scores over 80%, compared to 60-70% for the best-performing machine learning models. Qualitative analysis revealed that humans leveraged higher-level semantic understanding and reasoning to make their classifications, rather than simply relying on superficial textual features.
However, the study also uncovered some biases and limitations in human text comprehension. For example, participants tended to over-classify texts as belonging to academic or news genres, and showed systematic misclassifications on certain topic domains. The researchers hypothesize that these patterns arise from the participants' own experiences and backgrounds.
Overall, the results suggest that humans possess remarkable capabilities for rapidly understanding and categorizing textual information, capabilities which current AI systems have yet to fully match. The findings have implications for developing more robust and trustworthy natural language processing technologies, as well as for understanding the cognitive foundations of human language understanding.
Critical Analysis
A key strength of this study is the careful experimental design and large-scale dataset, which provides a comprehensive and rigorous comparison of human and machine text classification abilities. The use of state-of-the-art machine learning models as benchmarks also ensures the results reflect the current state-of-the-art in AI performance.
However, a potential limitation is the reliance on crowdsourced participants for the human evaluation. While this approach allows for testing a diverse set of individuals, it may not fully capture the capabilities of highly-trained domain experts. It would be worthwhile to replicate the study with specialized participants, such as professional editors or literary scholars, to see if their performance differs from the general pool.
Additionally, the paper does not delve deeply into the specific cognitive mechanisms or heuristics that underlie human text understanding. Further research is needed to unpack the exact strategies and biases that humans employ when classifying genres and topics. This could help inform the development of more human-like AI systems.
Finally, the study is limited to a single language (English) and text modality (written). It would be valuable to expand the research to other languages, speech, and multimodal data to test the generalizability of the findings.
Overall, this is a well-designed and insightful study that advances our understanding of the interplay between human and machine text comprehension. The results highlight the remarkable flexibility of human cognition, while also identifying areas where AI systems have room for improvement.
Conclusion
This paper provides compelling evidence that humans possess sophisticated cognitive abilities for rapidly understanding and categorizing textual information. Across a wide range of genres and topics, human participants significantly outperformed state-of-the-art machine learning models on classification tasks.
The findings shed light on the remarkable capabilities of the human mind when it comes to processing and making sense of language. At the same time, the study reveals biases and limitations in human text comprehension, suggesting that both human and machine approaches have unique strengths and weaknesses.
Understanding these differences is crucial for developing more intelligent and trustworthy natural language processing technologies. It also has implications for fields like cognitive science, where the paper contributes to our understanding of the cognitive underpinnings of human language understanding.
Ultimately, this research highlights the complementary nature of human and machine intelligence, and the potential for synergistic approaches that leverage the best of both. As AI systems become more sophisticated, continued exploration of the human-machine interface will be essential for unlocking the full potential of language technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can Humans Identify Domains?
Maria Barrett, Max Muller-Eberstein, Elisa Bassignana, Amalie Brogaard Pauli, Mike Zhang, Rob van der Goot
Textual domain is a crucial property within the Natural Language Processing (NLP) community due to its effects on downstream model performance. The concept itself is, however, loosely defined and, in practice, refers to any non-typological property, such as genre, topic, medium or style of a document. We investigate the core notion of domains via human proficiency in identifying related intrinsic textual properties, specifically the concepts of genre (communicative purpose) and topic (subject matter). We publish our annotations in *TGeGUM*: A collection of 9.1k sentences from the GUM dataset (Zeldes, 2017) with single sentence and larger context (i.e., prose) annotations for one of 11 genres (source type), and its topic/subtopic as per the Dewey Decimal library classification system (Dewey, 1979), consisting of 10/100 hierarchical topics of increased granularity. Each instance is annotated by three annotators, for a total of 32.7k annotations, allowing us to examine the level of human disagreement and the relative difficulty of each annotation task. With a Fleiss' kappa of at most 0.53 on the sentence level and 0.66 at the prose level, it is evident that despite the ubiquity of domains in NLP, there is little human consensus on how to define them. By training classifiers to perform the same task, we find that this uncertainty also extends to NLP models.
Read more4/3/2024

0
Domain-specific long text classification from sparse relevant information
C'elia D'Cruz, Jean-Marc Bereder, Fr'ed'eric Precioso, Michel Riveill
Large Language Models have undoubtedly revolutionized the Natural Language Processing field, the current trend being to promote one-model-for-all tasks (sentiment analysis, translation, etc.). However, the statistical mechanisms at work in the larger language models struggle to exploit the relevant information when it is very sparse, when it is a weak signal. This is the case, for example, for the classification of long domain-specific documents, when the relevance relies on a single relevant word or on very few relevant words from technical jargon. In the medical domain, it is essential to determine whether a given report contains critical information about a patient's condition. This critical information is often based on one or few specific isolated terms. In this paper, we propose a hierarchical model which exploits a short list of potential target terms to retrieve candidate sentences and represent them into the contextualized embedding of the target term(s) they contain. A pooling of the term(s) embedding(s) entails the document representation to be classified. We evaluate our model on one public medical document benchmark in English and on one private French medical dataset. We show that our narrower hierarchical model is better than larger language models for retrieving relevant long documents in a domain-specific context.
Read more8/26/2024
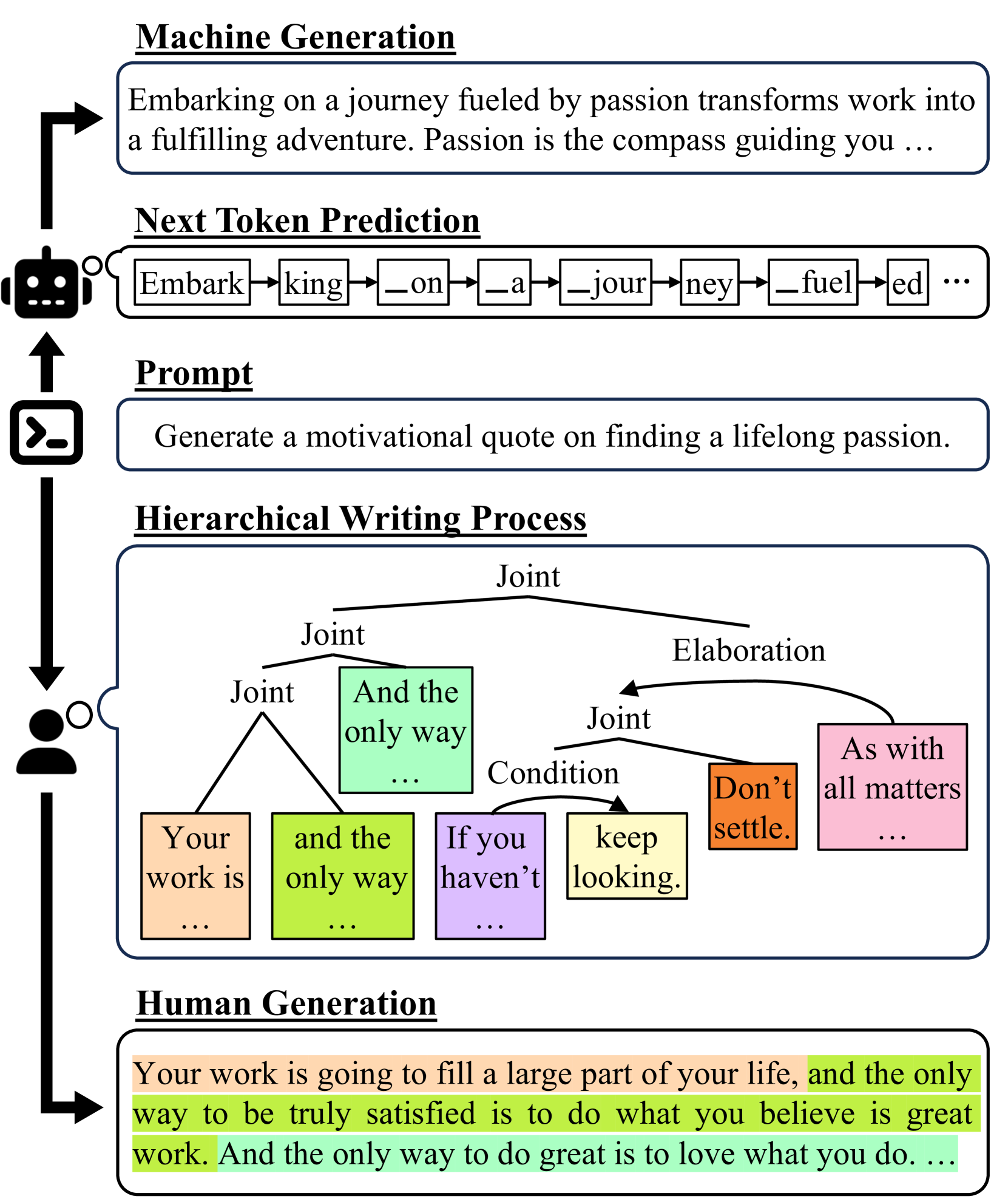
0
Threads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
Zae Myung Kim, Kwang Hee Lee, Preston Zhu, Vipul Raheja, Dongyeop Kang
With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset are available at https://github.com/minnesotanlp/threads-of-subtlety.
Read more6/10/2024

0
Detecting Statements in Text: A Domain-Agnostic Few-Shot Solution
Sandrine Chausson, Bjorn Ross
Many tasks related to Computational Social Science and Web Content Analysis involve classifying pieces of text based on the claims they contain. State-of-the-art approaches usually involve fine-tuning models on large annotated datasets, which are costly to produce. In light of this, we propose and release a qualitative and versatile few-shot learning methodology as a common paradigm for any claim-based textual classification task. This methodology involves defining the classes as arbitrarily sophisticated taxonomies of claims, and using Natural Language Inference models to obtain the textual entailment between these and a corpus of interest. The performance of these models is then boosted by annotating a minimal sample of data points, dynamically sampled using the well-established statistical heuristic of Probabilistic Bisection. We illustrate this methodology in the context of three tasks: climate change contrarianism detection, topic/stance classification and depression-relates symptoms detection. This approach rivals traditional pre-train/fine-tune approaches while drastically reducing the need for data annotation.
Read more5/10/2024