Detecting Statements in Text: A Domain-Agnostic Few-Shot Solution

0

Sign in to get full access
Overview
- This paper proposes a novel few-shot learning approach for detecting statements in text that is agnostic to the specific domain.
- The method leverages language models and few-shot learning techniques to enable rapid adaptation to new domains with limited training data.
- The authors demonstrate the effectiveness of their approach on several benchmarks, including how to solve few-shot abusive content, few-shot detection of machine-generated text, and simple semantic-aided few-shot learning.
Plain English Explanation
The paper presents a new way to teach an AI system to identify statements in written text, even when it has only seen a few examples. This is useful because sometimes you might want to use an AI to analyze text in a new area or domain, but you don't have a lot of labeled examples to train it on.
The key idea is to leverage large language models that have been trained on massive amounts of text data. These models can capture the general patterns and structure of language, which the researchers then use as a starting point. They then fine-tune the language model using just a few labeled examples of the specific task they want to perform, in this case, detecting statements.
This "few-shot learning" approach allows the AI to quickly adapt to new domains without requiring a lot of labeled data. The authors show that their method outperforms other few-shot learning techniques on several different benchmarks, including how to solve few-shot abusive content, few-shot detection of machine-generated text, and simple semantic-aided few-shot learning.
The ability to quickly adapt to new domains with limited data has important applications, such as liberating seen classes to boost few-shot zero and language models for text classification where context learning is crucial.
Technical Explanation
The paper proposes a domain-agnostic few-shot learning approach for detecting statements in text. The core idea is to leverage large pre-trained language models, which have learned rich representations of language, and then fine-tune these models on a small number of labeled examples of the specific task at hand.
The authors use a Transformer-based language model as the backbone, and then apply a few-shot learning technique called prototypical networks. This involves learning a embedding function that maps the input text into a vector representation, and then using these vector representations to classify new examples by comparing them to prototypes learned from the few labeled examples.
The authors evaluate their approach on several benchmarks, including how to solve few-shot abusive content, few-shot detection of machine-generated text, and simple semantic-aided few-shot learning. They show that their domain-agnostic few-shot learning method outperforms other few-shot learning techniques, demonstrating the ability to rapidly adapt to new domains with limited training data.
Critical Analysis
The paper presents a compelling approach to few-shot learning for statement detection, but there are a few potential limitations and areas for further research:
-
Evaluation on a wider range of domains: While the authors demonstrate the effectiveness of their method on several benchmarks, it would be valuable to evaluate it on an even broader range of domains, such as liberating seen classes to boost few-shot zero and language models for text classification where context learning is crucial.
-
Interpretability and explainability: The authors do not provide much insight into how the learned representations and prototypes lead to the classification decisions. Incorporating more interpretability and explainability into the model could help users understand its decision-making process.
-
Robustness to noisy or adversarial inputs: The paper does not explore the model's performance on noisy or adversarial inputs, which could be an important consideration for real-world deployment.
-
Broader societal implications: The authors do not discuss the potential societal impacts or ethical considerations of their work, such as the implications for how to solve few-shot abusive content or the responsible development of such technologies.
Overall, the paper presents a promising approach to few-shot learning for statement detection, but there are opportunities to expand the evaluation, improve the interpretability, and consider the broader implications of the research.
Conclusion
This paper introduces a novel domain-agnostic few-shot learning approach for detecting statements in text. By leveraging large pre-trained language models and fine-tuning them using a small number of labeled examples, the method demonstrates strong performance on several benchmarks, including tasks related to few-shot detection of machine-generated text and simple semantic-aided few-shot learning.
The ability to rapidly adapt to new domains with limited data has important applications in areas such as how to solve few-shot abusive content and liberating seen classes to boost few-shot zero. The authors' work represents a significant step forward in few-shot learning for text analysis, with the potential to enable more flexible and efficient deployment of AI systems in a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detecting Statements in Text: A Domain-Agnostic Few-Shot Solution
Sandrine Chausson, Bjorn Ross
Many tasks related to Computational Social Science and Web Content Analysis involve classifying pieces of text based on the claims they contain. State-of-the-art approaches usually involve fine-tuning models on large annotated datasets, which are costly to produce. In light of this, we propose and release a qualitative and versatile few-shot learning methodology as a common paradigm for any claim-based textual classification task. This methodology involves defining the classes as arbitrarily sophisticated taxonomies of claims, and using Natural Language Inference models to obtain the textual entailment between these and a corpus of interest. The performance of these models is then boosted by annotating a minimal sample of data points, dynamically sampled using the well-established statistical heuristic of Probabilistic Bisection. We illustrate this methodology in the context of three tasks: climate change contrarianism detection, topic/stance classification and depression-relates symptoms detection. This approach rivals traditional pre-train/fine-tune approaches while drastically reducing the need for data annotation.
Read more5/10/2024
0
Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
Simon Munker, Kai Kugler, Achim Rettinger
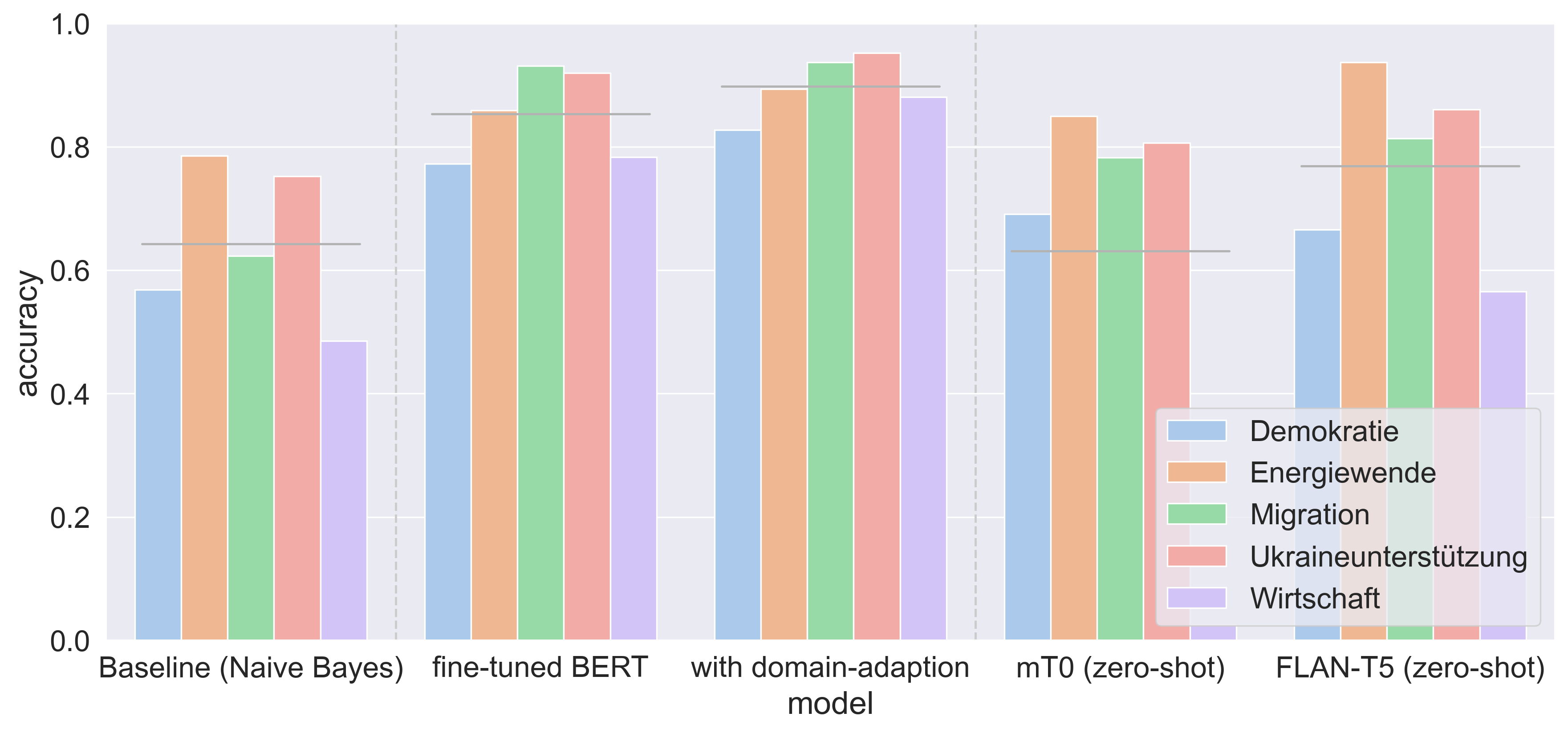
Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
Read more6/27/2024
🌿
0
Political DEBATE: Efficient Zero-shot and Few-shot Classifiers for Political Text
Michael Burnham, Kayla Kahn, Ryan Yank Wang, Rachel X. Peng
Social scientists quickly adopted large language models due to their ability to annotate documents without supervised training, an ability known as zero-shot learning. However, due to their compute demands, cost, and often proprietary nature, these models are often at odds with replication and open science standards. This paper introduces the Political DEBATE (DeBERTa Algorithm for Textual Entailment) language models for zero-shot and few-shot classification of political documents. These models are not only as good, or better than, state-of-the art large language models at zero and few-shot classification, but are orders of magnitude more efficient and completely open source. By training the models on a simple random sample of 10-25 documents, they can outperform supervised classifiers trained on hundreds or thousands of documents and state-of-the-art generative models with complex, engineered prompts. Additionally, we release the PolNLI dataset used to train these models -- a corpus of over 200,000 political documents with highly accurate labels across over 800 classification tasks.
Read more9/4/2024
🔎
0
How to Solve Few-Shot Abusive Content Detection Using the Data We Actually Have
Viktor Hangya, Alexander Fraser
Due to the broad range of social media platforms, the requirements of abusive language detection systems are varied and ever-changing. Already a large set of annotated corpora with different properties and label sets were created, such as hate or misogyny detection, but the form and targets of abusive speech are constantly evolving. Since, the annotation of new corpora is expensive, in this work we leverage datasets we already have, covering a wide range of tasks related to abusive language detection. Our goal is to build models cheaply for a new target label set and/or language, using only a few training examples of the target domain. We propose a two-step approach: first we train our model in a multitask fashion. We then carry out few-shot adaptation to the target requirements. Our experiments show that using already existing datasets and only a few-shots of the target task the performance of models improve both monolingually and across languages. Our analysis also shows that our models acquire a general understanding of abusive language, since they improve the prediction of labels which are present only in the target dataset and can benefit from knowledge about labels which are not directly used for the target task.
Read more5/7/2024