Threads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
2402.10586
0
0
Abstract
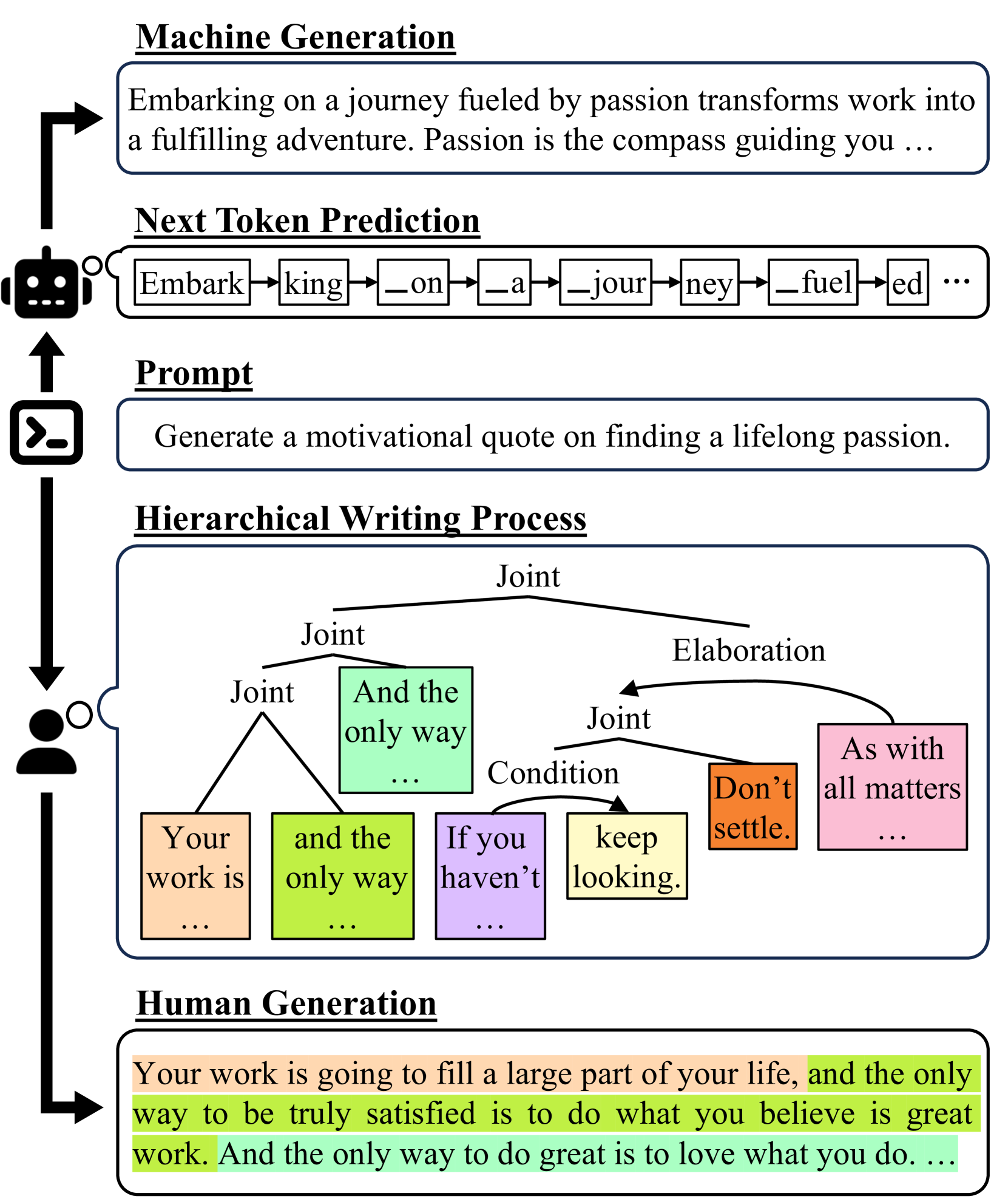
With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset are available at https://github.com/minnesotanlp/threads-of-subtlety.
Create account to get full access
Overview
- This paper proposes a novel approach for detecting machine-generated text by analyzing the discourse structure and rhetorical patterns in the text.
- The key idea is that machine-generated text, even when it appears fluent and coherent, often lacks the subtle discourse-level cues that are present in human-written text.
- The researchers develop a model based on Rhetorical Structure Theory to capture these hierarchical discourse structures and use them to differentiate between human-written and machine-generated text.
Plain English Explanation
The paper examines a clever way to tell if a piece of text was written by a human or generated by a machine. Even when machine-generated text looks and sounds natural, it often lacks the nuanced discourse patterns that are present in human writing. The researchers developed a model that analyzes the hierarchical structure of the text, based on a theory called Rhetorical Structure Theory. By looking at how the different parts of the text connect and flow together, their model can detect subtle cues that distinguish human-written text from machine-generated text. This approach is particularly useful for identifying machine-generated text that might otherwise be difficult to detect, as it goes beyond simply looking at surface-level features of the text.
Technical Explanation
The paper proposes a method for detecting machine-generated text by modeling the hierarchical discourse structure of the text using Rhetorical Structure Theory (RST). RST is a framework for understanding how different parts of a text (called "discourse units") relate to each other in a hierarchical manner to convey meaning.
The researchers develop an RST-based model that captures these discourse-level relationships and use them as features to distinguish between human-written and machine-generated text. Specifically, they extract features related to the depth and breadth of the discourse tree, the distribution of discourse relations, and the coherence of the text. These features are then used to train a classifier to predict whether a given text was written by a human or generated by a machine.
The authors evaluate their approach on a range of datasets, including link to "Deciphering Textual Authenticity: A Generalized Strategy Through the Lens of Rhetorical Structure", link to "Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text", and link to "MAGE: Machine-Generated Text Detection in the Wild". They show that their RST-based model outperforms a range of baselines and other state-of-the-art approaches for machine-generated text detection.
Critical Analysis
The paper presents a promising approach for detecting machine-generated text by leveraging the hierarchical discourse structure of the text. One strength of this method is that it can capture more nuanced linguistic cues that may not be easily detected by simpler surface-level features.
However, the paper acknowledges that the performance of the model may be sensitive to the specific dataset and genre of text being analyzed. There is also a risk that as language models become more sophisticated, they may start to better mimic the discourse-level patterns observed in human-written text, potentially reducing the effectiveness of this approach over time.
Additionally, while the paper provides a thorough technical evaluation, it would be interesting to see more real-world applications and case studies to understand the practical implications and limitations of this technique. link to "Few-Shot Detection of Machine-Generated Text Using Discrete Representational Predictors" and link to "MUGC: Machine-Generated versus User-Generated Content" may provide further insights in this direction.
Conclusion
This paper presents a novel approach for detecting machine-generated text by modeling the hierarchical discourse structure of the text using Rhetorical Structure Theory. The key insight is that even when machine-generated text appears fluent and coherent, it often lacks the subtle discourse-level cues that are present in human-written text.
The proposed RST-based model outperforms a range of baselines and other state-of-the-art approaches for machine-generated text detection, making it a promising technique for a variety of applications, such as content moderation, misinformation detection, and plagiarism identification. As language models continue to advance, techniques like this that can capture more nuanced linguistic patterns will become increasingly important for maintaining the integrity of written communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
Exploring the Limitations of Detecting Machine-Generated Text
Jad Doughman, Osama Mohammed Afzal, Hawau Olamide Toyin, Shady Shehata, Preslav Nakov, Zeerak Talat
0
0
Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
6/18/2024
📶
Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text
Muhammad Farid Adilazuarda
0
0
Significant progress has been made on text generation by pre-trained language models (PLMs), yet distinguishing between human and machine-generated text poses an escalating challenge. This paper offers an in-depth evaluation of three distinct methods used to address this task: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning. These approaches are rigorously tested on a wide range of machine-generated texts, providing a benchmark of their competence in distinguishing between human-authored and machine-authored linguistic constructs. The results reveal considerable differences in performance across methods, thus emphasizing the continued need for advancement in this crucial area of NLP. This study offers valuable insights and paves the way for future research aimed at creating robust and highly discriminative models.
5/16/2024
🤖
Detecting Machine-Generated Texts: Not Just AI vs Humans and Explainability is Complicated
Jiazhou Ji, Ruizhe Li, Shujun Li, Jie Guo, Weidong Qiu, Zheng Huang, Chiyu Chen, Xiaoyu Jiang, Xinru Lu
0
0
As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an undecided category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why undecided category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
6/27/2024