Can Implicit Bias Imply Adversarial Robustness?
2405.15942
0
0
Abstract
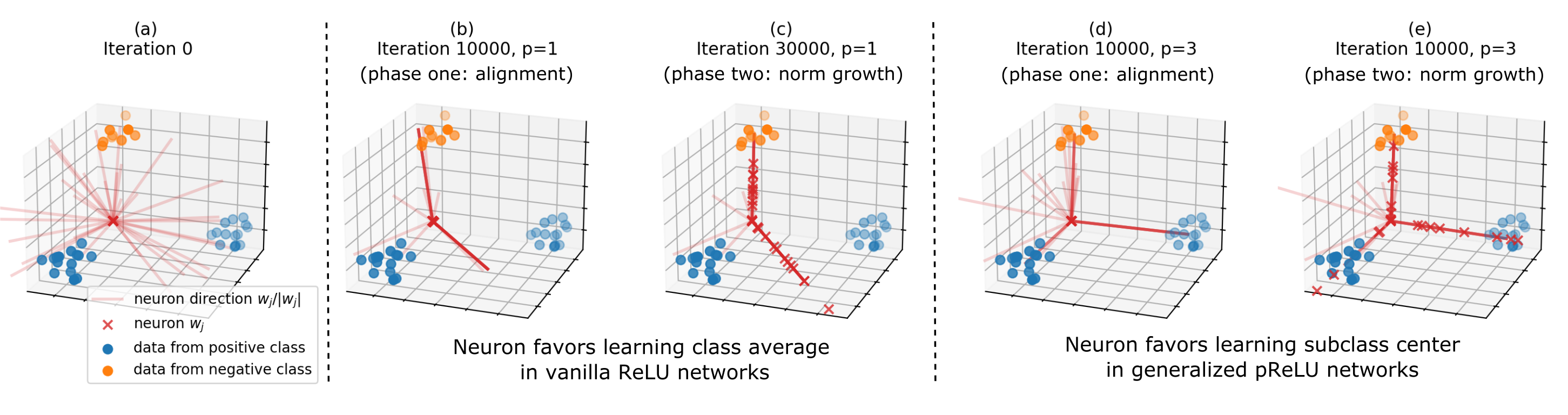
The implicit bias of gradient-based training algorithms has been considered mostly beneficial as it leads to trained networks that often generalize well. However, Frei et al. (2023) show that such implicit bias can harm adversarial robustness. Specifically, they show that if the data consists of clusters with small inter-cluster correlation, a shallow (two-layer) ReLU network trained by gradient flow generalizes well, but it is not robust to adversarial attacks of small radius. Moreover, this phenomenon occurs despite the existence of a much more robust classifier that can be explicitly constructed from a shallow network. In this paper, we extend recent analyses of neuron alignment to show that a shallow network with a polynomial ReLU activation (pReLU) trained by gradient flow not only generalizes well but is also robust to adversarial attacks. Our results highlight the importance of the interplay between data structure and architecture design in the implicit bias and robustness of trained networks.
Create account to get full access
Overview
- The research paper investigates the relationship between implicit bias and adversarial robustness in neural networks.
- It explores whether the presence of implicit bias, which can lead to biased decisions, can also imply that the network is more robust to adversarial attacks.
- The paper presents theoretical and empirical findings on the connection between implicit bias and adversarial robustness.
Plain English Explanation
Neural networks, the powerful AI algorithms that power many modern technologies, can sometimes make biased decisions without us realizing it. This "implicit bias" can lead to unfair or inaccurate outputs, which is a significant concern. However, the researchers behind this paper wondered if this implicit bias might also have a surprising upside - could it make the neural network more resistant to adversarial attacks, where small changes to the input are designed to trick the network into making mistakes?
To investigate this, the researchers set up experiments to test the adversarial robustness of neural networks with different levels of implicit bias. They found that neural networks with a stronger implicit bias tended to be more robust to adversarial attacks. In other words, the same feature that can lead to biased decisions may also help protect the network from being easily fooled by adversaries trying to manipulate its outputs.
This is an intriguing finding, as it suggests there could be a trade-off between fairness and security when it comes to neural network design. Explicitly reducing implicit bias to improve fairness might also make the network more vulnerable to adversarial attacks. The researchers provide theoretical explanations for this connection, as well as insights into how the network architecture and activation functions can influence this relationship.
Technical Explanation
The researchers investigated the connection between implicit bias and adversarial robustness in neural networks. Implicit bias refers to the tendency of neural networks to make biased decisions, even when the training data is unbiased. This can lead to unfair or inaccurate outputs, which is a significant concern in many real-world applications.
The paper presents theoretical and empirical results showing that the presence of implicit bias can also imply greater adversarial robustness. The researchers set up experiments using two-layer neural networks with ReLU activation, testing how the degree of implicit bias affects the network's ability to withstand adversarial attacks.
The key findings include:
-
Neural networks with stronger implicit bias tend to be more robust to adversarial attacks. The researchers provide theoretical explanations for this relationship, linking it to the flatness of the network's decision boundaries.
-
The network architecture and activation function choices can influence the degree of implicit bias and, consequently, the level of adversarial robustness. The researchers explore how these design choices impact the observed trade-off between fairness and security.
-
The results suggest that explicitly reducing implicit bias to improve fairness might also make the network more vulnerable to adversarial attacks. This highlights the potential tension between these two important properties of neural networks.
Critical Analysis
The paper presents a thoughtful and rigorous investigation into the relationship between implicit bias and adversarial robustness. The theoretical and empirical analyses provide valuable insights into the underlying mechanisms behind this connection.
However, the researchers acknowledge several limitations and caveats to their work. For example, the results are primarily demonstrated on simple two-layer networks, and it's unclear how well the findings would extend to more complex, real-world neural network architectures. Additionally, the paper focuses on a specific type of adversarial attack, and the relationship may differ for other attack strategies.
Furthermore, while the trade-off between fairness and security is an important consideration, the researchers do not delve into the broader societal implications of this finding. In many high-stakes applications, such as healthcare or criminal justice, biased decisions can have significant ethical and practical consequences that should be carefully weighed against security concerns.
Additional research on the role of data distribution and network architecture in balancing these competing objectives would be valuable to further our understanding and inform practical guidelines for neural network design.
Conclusion
This research paper offers an intriguing perspective on the relationship between implicit bias and adversarial robustness in neural networks. The key finding - that the presence of implicit bias can imply greater resistance to adversarial attacks - suggests a potential trade-off between fairness and security in neural network design.
While this trade-off requires careful consideration, the insights provided in the paper could inform the development of more secure and reliable AI systems. By understanding the connections between implicit bias, network architecture, and adversarial robustness, researchers and practitioners can work towards designing neural networks that are both fair and resilient to malicious attacks.
As AI continues to be integrated into critical decision-making processes, understanding these complex relationships will be increasingly important for ensuring the trustworthiness and responsible deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
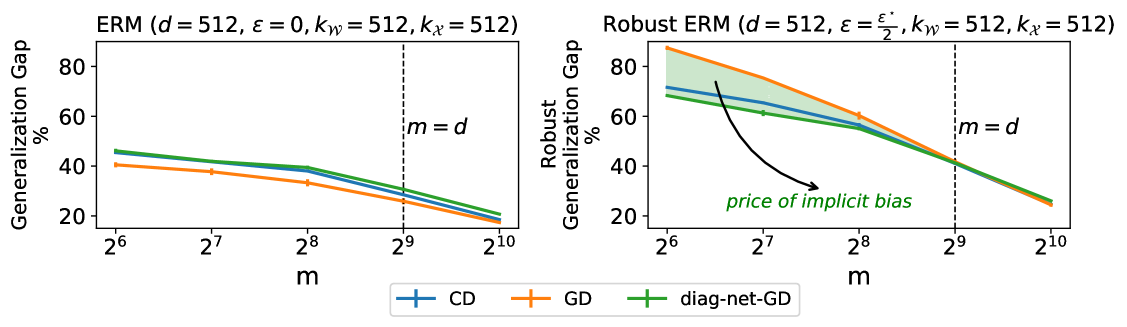
The Price of Implicit Bias in Adversarially Robust Generalization
Nikolaos Tsilivis, Natalie Frank, Nathan Srebro, Julia Kempe
0
0
We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
6/10/2024

Is ReLU Adversarially Robust?
Korn Sooksatra, Greg Hamerly, Pablo Rivas
0
0
The efficacy of deep learning models has been called into question by the presence of adversarial examples. Addressing the vulnerability of deep learning models to adversarial examples is crucial for ensuring their continued development and deployment. In this work, we focus on the role of rectified linear unit (ReLU) activation functions in the generation of adversarial examples. ReLU functions are commonly used in deep learning models because they facilitate the training process. However, our empirical analysis demonstrates that ReLU functions are not robust against adversarial examples. We propose a modified version of the ReLU function, which improves robustness against adversarial examples. Our results are supported by an experiment, which confirms the effectiveness of our proposed modification. Additionally, we demonstrate that applying adversarial training to our customized model further enhances its robustness compared to a general model.
5/8/2024
🏋️
Adversarial Training of Two-Layer Polynomial and ReLU Activation Networks via Convex Optimization
Daniel Kuelbs, Sanjay Lall, Mert Pilanci
0
0
Training neural networks which are robust to adversarial attacks remains an important problem in deep learning, especially as heavily overparameterized models are adopted in safety-critical settings. Drawing from recent work which reformulates the training problems for two-layer ReLU and polynomial activation networks as convex programs, we devise a convex semidefinite program (SDP) for adversarial training of polynomial activation networks via the S-procedure. We also derive a convex SDP to compute the minimum distance from a correctly classified example to the decision boundary of a polynomial activation network. Adversarial training for two-layer ReLU activation networks has been explored in the literature, but, in contrast to prior work, we present a scalable approach which is compatible with standard machine libraries and GPU acceleration. The adversarial training SDP for polynomial activation networks leads to large increases in robust test accuracy against $ell^infty$ attacks on the Breast Cancer Wisconsin dataset from the UCI Machine Learning Repository. For two-layer ReLU networks, we leverage our scalable implementation to retrain the final two fully connected layers of a Pre-Activation ResNet-18 model on the CIFAR-10 dataset. Our 'robustified' model achieves higher clean and robust test accuracies than the same architecture trained with sharpness-aware minimization.
5/24/2024
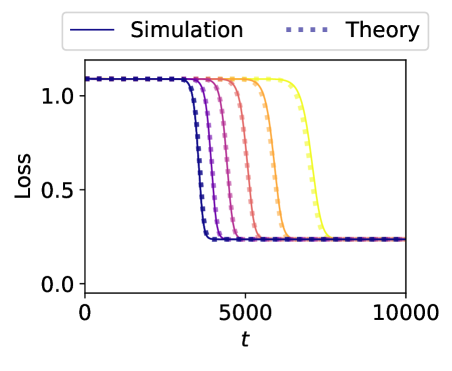
When Are Bias-Free ReLU Networks Like Linear Networks?
Yedi Zhang, Andrew Saxe, Peter E. Latham
0
0
We investigate the expressivity and learning dynamics of bias-free ReLU networks. We firstly show that two-layer bias-free ReLU networks have limited expressivity: the only odd function two-layer bias-free ReLU networks can express is a linear one. We then show that, under symmetry conditions on the data, these networks have the same learning dynamics as linear networks. This allows us to give closed-form time-course solutions to certain two-layer bias-free ReLU networks, which has not been done for nonlinear networks outside the lazy learning regime. While deep bias-free ReLU networks are more expressive than their two-layer counterparts, they still share a number of similarities with deep linear networks. These similarities enable us to leverage insights from linear networks, leading to a novel understanding of bias-free ReLU networks. Overall, our results show that some properties established for bias-free ReLU networks arise due to equivalence to linear networks, and suggest that including bias or considering asymmetric data are avenues to engage with nonlinear behaviors.
6/19/2024