The Price of Implicit Bias in Adversarially Robust Generalization
2406.04981
0
0
Abstract
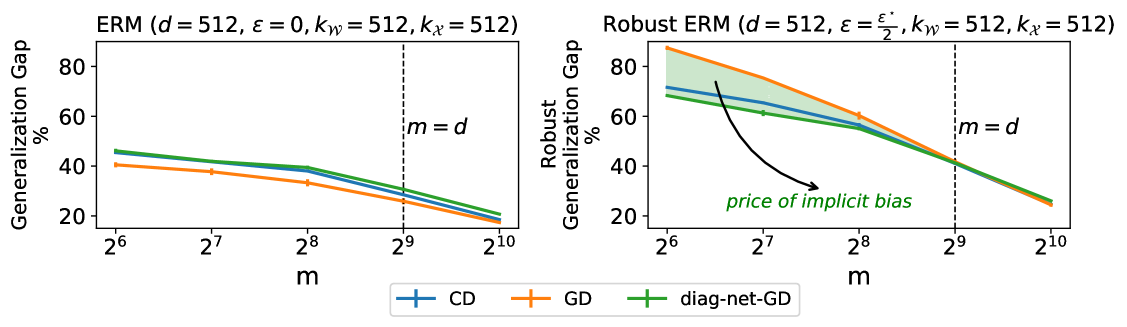
We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
Create account to get full access
Overview
- The paper examines the relationship between implicit biases in machine learning models and their adversarial robustness.
- It investigates the potential tradeoffs between optimizing for adversarial robustness and maintaining the natural performance of models.
- The research explores how implicit biases in model architectures and training data can impact a model's ability to be adversarially robust.
Plain English Explanation
The paper looks at how the natural biases that can develop in machine learning models during training can affect their ability to be robust against adversarial attacks. Adversarial attacks are small, carefully crafted changes to input data that can cause a model to make incorrect predictions.
The researchers wanted to understand if optimizing a model to be more adversarially robust might come at the cost of its natural performance on normal, unmodified data. They explored how the inherent biases that get "baked into" a model's architecture or the data it's trained on can influence its robustness.
For example, a model trained on ImageNet may develop an implicit bias towards certain visual features. This could make the model more vulnerable to adversarial attacks that target those biases, even if the model is trained to be robust. The paper investigates these tradeoffs and how they manifest in different machine learning settings.
Technical Explanation
The paper presents a theoretical and empirical analysis of the relationship between implicit biases in machine learning models and their adversarial robustness. The researchers developed a framework to quantify the "price of implicit bias" - the extent to which a model's natural performance may need to be sacrificed to achieve adversarial robustness.
Through experiments on various benchmark datasets and model architectures, the paper demonstrates that the presence of implicit biases can significantly impact a model's ability to be adversarially robust. For example, models trained on CIFAR-10 were found to be more vulnerable to adversarial attacks than models trained on MNIST, likely due to the more complex implicit biases present in the CIFAR-10 dataset.
The researchers also investigated the effects of different training techniques, such as adversarial training, on mitigating the impact of implicit biases. Their findings suggest that while adversarial training can improve a model's robustness, it may not be able to fully eliminate the influence of underlying biases.
Critical Analysis
The paper provides valuable insights into the complex interplay between implicit biases and adversarial robustness in machine learning models. However, it also highlights the inherent challenges in fully addressing these issues.
One limitation discussed in the paper is the difficulty in precisely quantifying and disentangling the various sources of implicit bias, which can arise from the model architecture, training data, and optimization process. The researchers acknowledge that their framework for measuring the "price of implicit bias" may not capture all the nuances of these relationships.
Additionally, the paper focuses primarily on standard image classification tasks, which may not fully generalize to other machine learning domains. Further research is needed to understand how these principles apply to more complex, real-world applications.
Finally, the paper raises important questions about the broader societal implications of these findings. If implicit biases in machine learning models can undermine their adversarial robustness, it could have significant consequences for the deployment of these systems in high-stakes applications, such as healthcare or finance. Continued scrutiny and responsible development of these technologies will be crucial.
Conclusion
This paper makes a significant contribution to our understanding of the intricate relationship between implicit biases and adversarial robustness in machine learning models. By quantifying the "price of implicit bias," the researchers have shed light on a fundamental tradeoff that must be considered when developing robust and reliable AI systems.
The insights from this work have important implications for the design of machine learning architectures, the curation of training data, and the development of techniques to mitigate the impact of biases. As the field of AI continues to advance, addressing these challenges will be crucial for ensuring the trustworthiness and fairness of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Can Implicit Bias Imply Adversarial Robustness?
Hancheng Min, Ren'e Vidal
0
0
The implicit bias of gradient-based training algorithms has been considered mostly beneficial as it leads to trained networks that often generalize well. However, Frei et al. (2023) show that such implicit bias can harm adversarial robustness. Specifically, they show that if the data consists of clusters with small inter-cluster correlation, a shallow (two-layer) ReLU network trained by gradient flow generalizes well, but it is not robust to adversarial attacks of small radius. Moreover, this phenomenon occurs despite the existence of a much more robust classifier that can be explicitly constructed from a shallow network. In this paper, we extend recent analyses of neuron alignment to show that a shallow network with a polynomial ReLU activation (pReLU) trained by gradient flow not only generalizes well but is also robust to adversarial attacks. Our results highlight the importance of the interplay between data structure and architecture design in the implicit bias and robustness of trained networks.
6/6/2024
🛠️
Faster Margin Maximization Rates for Generic and Adversarially Robust Optimization Methods
Guanghui Wang, Zihao Hu, Claudio Gentile, Vidya Muthukumar, Jacob Abernethy
0
0
First-order optimization methods tend to inherently favor certain solutions over others when minimizing an underdetermined training objective that has multiple global optima. This phenomenon, known as implicit bias, plays a critical role in understanding the generalization capabilities of optimization algorithms. Recent research has revealed that in separable binary classification tasks gradient-descent-based methods exhibit an implicit bias for the $ell_2$-maximal margin classifier. Similarly, generic optimization methods, such as mirror descent and steepest descent, have been shown to converge to maximal margin classifiers defined by alternative geometries. While gradient-descent-based algorithms provably achieve fast implicit bias rates, corresponding rates in the literature for generic optimization methods are relatively slow. To address this limitation, we present a series of state-of-the-art implicit bias rates for mirror descent and steepest descent algorithms. Our primary technique involves transforming a generic optimization algorithm into an online optimization dynamic that solves a regularized bilinear game, providing a unified framework for analyzing the implicit bias of various optimization methods. Our accelerated rates are derived by leveraging the regret bounds of online learning algorithms within this game framework. We then show the flexibility of this framework by analyzing the implicit bias in adversarial training, and again obtain significantly improved convergence rates.
4/9/2024
🔮
On the Implicit Bias of Adam
Matias D. Cattaneo, Jason M. Klusowski, Boris Shigida
0
0
In previous literature, backward error analysis was used to find ordinary differential equations (ODEs) approximating the gradient descent trajectory. It was found that finite step sizes implicitly regularize solutions because terms appearing in the ODEs penalize the two-norm of the loss gradients. We prove that the existence of similar implicit regularization in RMSProp and Adam depends on their hyperparameters and the training stage, but with a different norm involved: the corresponding ODE terms either penalize the (perturbed) one-norm of the loss gradients or, conversely, impede its reduction (the latter case being typical). We also conduct numerical experiments and discuss how the proven facts can influence generalization.
6/18/2024

Uniform Convergence of Adversarially Robust Classifiers
Rachel Morris, Ryan Murray
0
0
In recent years there has been significant interest in the effect of different types of adversarial perturbations in data classification problems. Many of these models incorporate the adversarial power, which is an important parameter with an associated trade-off between accuracy and robustness. This work considers a general framework for adversarially-perturbed classification problems, in a large data or population-level limit. In such a regime, we demonstrate that as adversarial strength goes to zero that optimal classifiers converge to the Bayes classifier in the Hausdorff distance. This significantly strengthens previous results, which generally focus on $L^1$-type convergence. The main argument relies upon direct geometric comparisons and is inspired by techniques from geometric measure theory.
6/24/2024