Can Large Multimodal Models Uncover Deep Semantics Behind Images?

0
🤿
Sign in to get full access
Overview
- The provided paper explores the capabilities of large multimodal models in generating dense text.
- It explains the inner workings of multi-modal large language models and how they can be evaluated.
- The paper reviews the current state of multi-modal large language and vision models.
- It discusses whether existing evaluation methods are appropriate for assessing these advanced models.
- The paper introduces a new diffusion-based model that can serve as "eyes" for large language models.
Plain English Explanation
The paper investigates the abilities of complex AI models that can process and generate text, images, and other data types together. These models are called "multimodal" because they work with multiple forms of information.
The researchers explain how these large, sophisticated models work under the hood. They examine ways to thoroughly test and measure the capabilities of these multimodal systems. This includes looking at current evaluation methods and whether they are suitable for assessing the advanced features of these models.
Additionally, the paper introduces a new type of AI model called a "diffusion" model. This model can act as "eyes" for the large language models, helping them better understand and describe the visual world.
Overall, the research aims to shed light on the inner workings and assessment of these powerful multimodal AI systems, which have the potential to transform how we interact with technology.
Technical Explanation
The paper "Exploring the Capabilities of Large Multimodal Models for Dense Text Generation" investigates the abilities of large language models that can process and generate text, images, and other data types together.
The authors explain the architecture and training of these multi-modal large language models in detail. They review the current state of the art in multi-modal large language and vision models and discuss whether existing evaluation methods are appropriate for assessing the advanced capabilities of these systems.
Additionally, the paper introduces a new diffusion-based model that can serve as "eyes" for large language models, helping them better understand and describe the visual world.
Critical Analysis
The paper provides a comprehensive overview of the latest developments in multimodal language models. However, it acknowledges certain caveats and limitations. For instance, the authors note that existing evaluation methods may not adequately capture the true capabilities of these advanced systems.
Additionally, the paper raises the question of whether the new diffusion-based model introduced can truly serve as a reliable "visual system" for large language models. Further research and testing would be needed to validate the effectiveness of this approach.
Overall, the paper makes a valuable contribution to the field by shedding light on the inner workings and assessment of multimodal AI models. But it also highlights the need for continued innovation and critical evaluation as these technologies continue to evolve.
Conclusion
This research paper provides a deep dive into the capabilities and evaluation of large multimodal models. It explains the technical details of how these sophisticated systems process and generate text, images, and other data types together.
The paper also introduces a novel diffusion-based model that can enhance the visual understanding of large language models. This represents an exciting development in the quest to create AI systems that can seamlessly interact with the world around them.
While the research offers significant insights, it also acknowledges the need for further advancements in model evaluation and testing. As these multimodal technologies continue to advance, maintaining a critical and objective perspective will be crucial to ensuring they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Can Large Multimodal Models Uncover Deep Semantics Behind Images?
Yixin Yang, Zheng Li, Qingxiu Dong, Heming Xia, Zhifang Sui
Understanding the deep semantics of images is essential in the era dominated by social media. However, current research works primarily on the superficial description of images, revealing a notable deficiency in the systematic investigation of the inherent deep semantics. In this work, we introduce DEEPEVAL, a comprehensive benchmark to assess Large Multimodal Models' (LMMs) capacities of visual deep semantics. DEEPEVAL includes human-annotated dataset and three progressive subtasks: fine-grained description selection, in-depth title matching, and deep semantics understanding. Utilizing DEEPEVAL, we evaluate 9 open-source LMMs and GPT-4V(ision). Our evaluation demonstrates a substantial gap between the deep semantic comprehension capabilities of existing LMMs and humans. For example, GPT-4V is 30% behind humans in understanding deep semantics, even though it achieves human-comparable performance in image description. Further analysis reveals that LMM performance on DEEPEVAL varies according to the specific facets of deep semantics explored, indicating the fundamental challenges remaining in developing LMMs.
Read more6/21/2024

0
Exploiting LMM-based knowledge for image classification tasks
Maria Tzelepi, Vasileios Mezaris
In this paper we address image classification tasks leveraging knowledge encoded in Large Multimodal Models (LMMs). More specifically, we use the MiniGPT-4 model to extract semantic descriptions for the images, in a multimodal prompting fashion. In the current literature, vision language models such as CLIP, among other approaches, are utilized as feature extractors, using only the image encoder, for solving image classification tasks. In this paper, we propose to additionally use the text encoder to obtain the text embeddings corresponding to the MiniGPT-4-generated semantic descriptions. Thus, we use both the image and text embeddings for solving the image classification task. The experimental evaluation on three datasets validates the improved classification performance achieved by exploiting LMM-based knowledge.
Read more6/6/2024
0
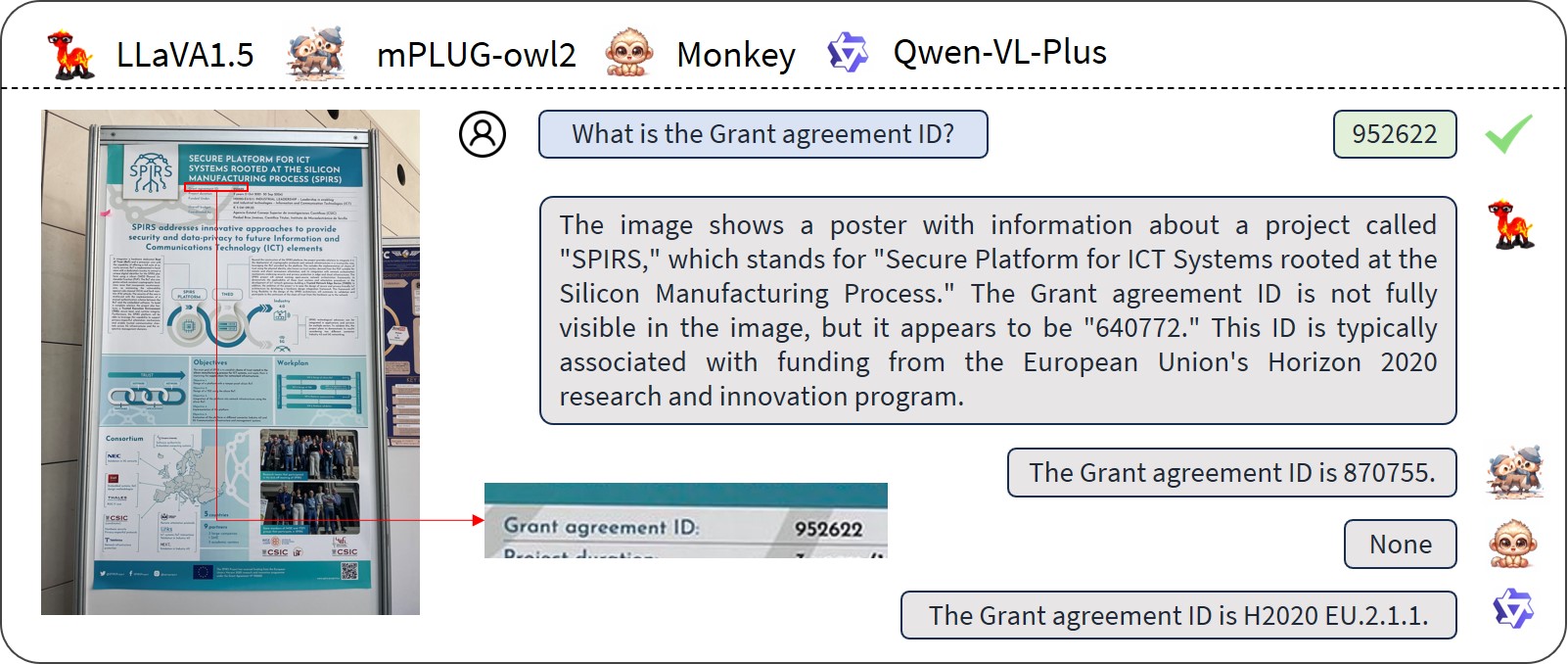
Exploring the Capabilities of Large Multimodal Models on Dense Text
Shuo Zhang, Biao Yang, Zhang Li, Zhiyin Ma, Yuliang Liu, Xiang Bai
While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.
Read more5/14/2024
0
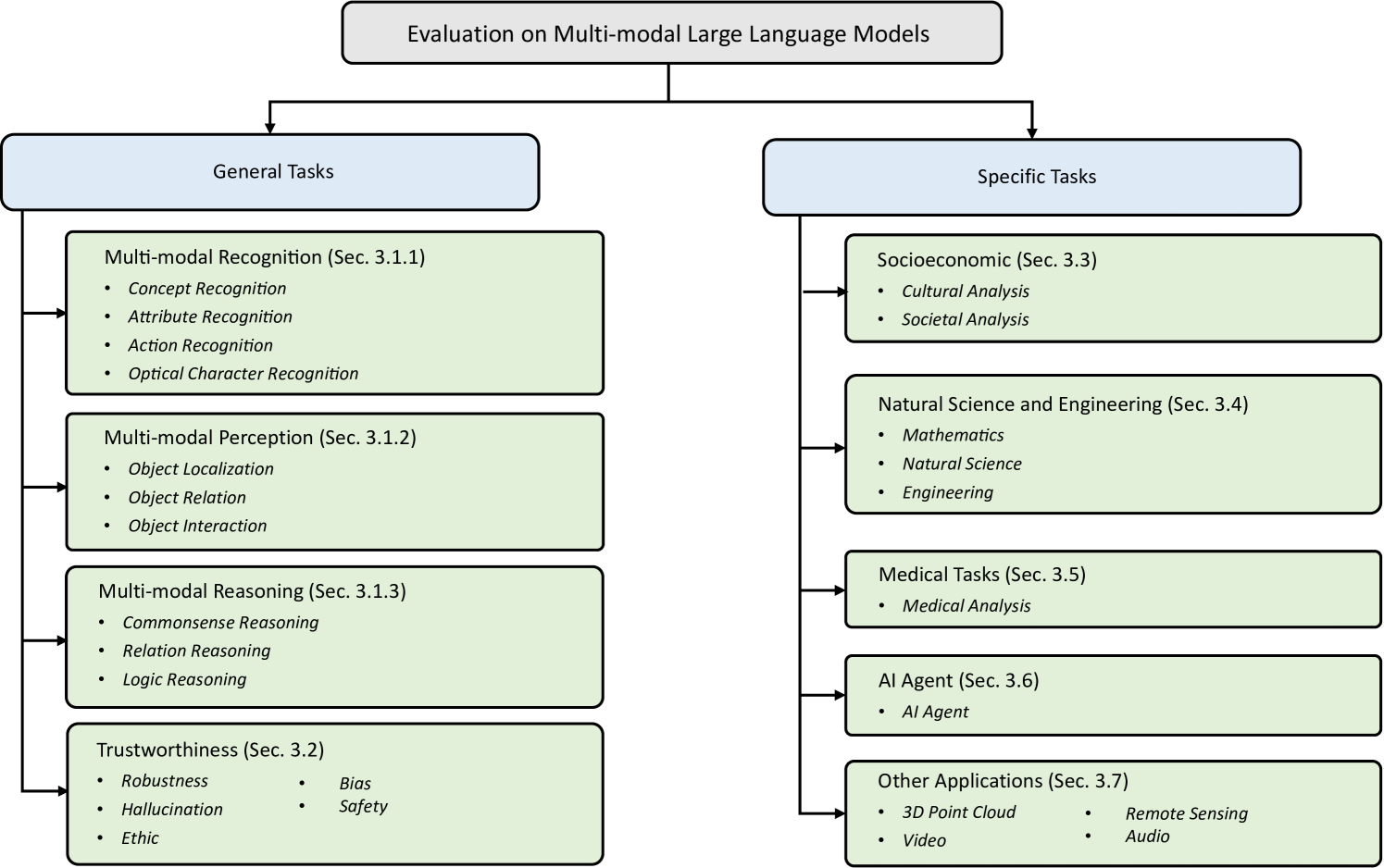
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024