Can LLMs Effectively Leverage Graph Structural Information through Prompts, and Why?
2309.16595
0
0
🚀
Abstract
Large language models (LLMs) are gaining increasing attention for their capability to process graphs with rich text attributes, especially in a zero-shot fashion. Recent studies demonstrate that LLMs obtain decent text classification performance on common text-rich graph benchmarks, and the performance can be improved by appending encoded structural information as natural languages into prompts. We aim to understand why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs. First, we rule out the concern of data leakage by curating a novel leakage-free dataset and conducting a comparative analysis alongside a previously widely-used dataset. Second, as past work usually encodes the ego-graph by describing the graph structure in natural language, we ask the question: do LLMs understand the graph structure in accordance with the intent of the prompt designers? Third, we investigate why LLMs can improve their performance after incorporating structural information. Our exploration of these questions reveals that (i) there is no substantial evidence that the performance of LLMs is significantly attributed to data leakage; (ii) instead of understanding prompts as graph structures as intended by the prompt designers, LLMs tend to process prompts more as contextual paragraphs and (iii) the most efficient elements of the local neighborhood included in the prompt are phrases that are pertinent to the node label, rather than the graph structure.
Create account to get full access
Overview
- Evaluates how well large language models (LLMs) can process and reason about graph-structured data with rich text attributes
- Investigates whether the performance improvement from incorporating graph structure is due to data leakage or genuine understanding of the graph structure
- Explores how LLMs interpret prompts describing graph structure and what aspects of the graph are most useful for their predictions
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can process and generate human-like text. Researchers have found that these models can also work with graph-structured data, which is data organized in a network-like structure with nodes and connections between them. When LLMs are given information about the graph structure along with the text content, their performance on tasks like classifying the nodes improves.
This paper aims to understand why the addition of graph structure information helps LLMs. The researchers first rule out the possibility that the performance boost is simply due to the model "cheating" by accidentally learning information that was leaked from the training data. They do this by creating a new dataset that avoids this data leakage problem.
Next, the researchers investigate whether LLMs truly understand the graph structure as intended by the researchers who designed the prompts, or if they are just processing the prompts as regular text. They find that LLMs tend to focus more on the text content that is relevant to the node labels, rather than genuinely understanding the graph structure.
Finally, the paper explores what specific aspects of the graph structure are most useful for LLMs when making their predictions. The key finding is that the most helpful information is not necessarily the full details of the graph, but rather the "local neighborhood" - the nodes and connections that are directly related to the node being classified.
Overall, this research provides insights into how LLMs interact with and reason about graph-structured data, which can inform the development of more effective ways to apply these powerful models to problems involving complex, interconnected data.
Technical Explanation
The researchers first curate a novel dataset that avoids the potential issue of data leakage, which can occur when information about the test set is inadvertently included in the training data. They compare the performance of LLMs on this new dataset to a previously widely-used dataset, and find no substantial evidence that data leakage is a significant factor in the models' improved performance when given graph structure information.
Next, the researchers investigate how LLMs interpret the prompts that describe the graph structure. Past work has typically encoded the "ego-graph" (the node of interest and its direct neighbors) by expressing the graph structure in natural language. However, the researchers find that LLMs do not necessarily understand these prompts as intended - that is, as representations of the underlying graph structure. Instead, the models seem to process the prompts more as contextual paragraphs of text, focusing on the parts that are most relevant to the node label prediction task.
Finally, the paper explores which aspects of the graph structure are most helpful for LLMs when making their predictions. The researchers find that the most efficient elements are not necessarily the full details of the graph topology, but rather the "local neighborhood" - the nodes and connections that are directly related to the node being classified. Phrases that describe these local, label-relevant aspects of the graph appear to be the most useful for improving the LLMs' performance.
Critical Analysis
The researchers acknowledge that their work is limited to a specific set of graph classification tasks and LLM architectures. It would be valuable to extend this analysis to a broader range of graph-related tasks and model types to see if the findings hold true more generally.
Additionally, while the paper rules out data leakage as a significant factor, there may still be other ways in which the LLMs are exploiting biases or shortcuts in the data that are not fully understood. Further investigation into the models' decision-making processes and the types of graph-related reasoning they are capable of would be helpful.
It is also worth considering the potential limitations of using natural language prompts to encode graph structure. Alternative approaches, such as directly incorporating graph neural network architectures into the LLMs, may lead to better understanding and reasoning about the underlying graph data.
Conclusion
This research provides valuable insights into how large language models interact with and reason about graph-structured data. The key findings are that LLMs do not necessarily understand graph structure as intended by prompt designers, and that the most useful information for improving their performance is the "local neighborhood" of nodes and connections that are directly relevant to the task at hand, rather than the full details of the graph topology.
These insights can inform the development of more effective ways to apply LLMs to problems involving complex, interconnected data, such as joint embeddings of graphs and instructions or improving LLM performance through better knowledge integration. As the field of graph machine learning in the era of large language models continues to evolve, this research provides a valuable contribution to our understanding of how these powerful models can be leveraged to reason about and make predictions on structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
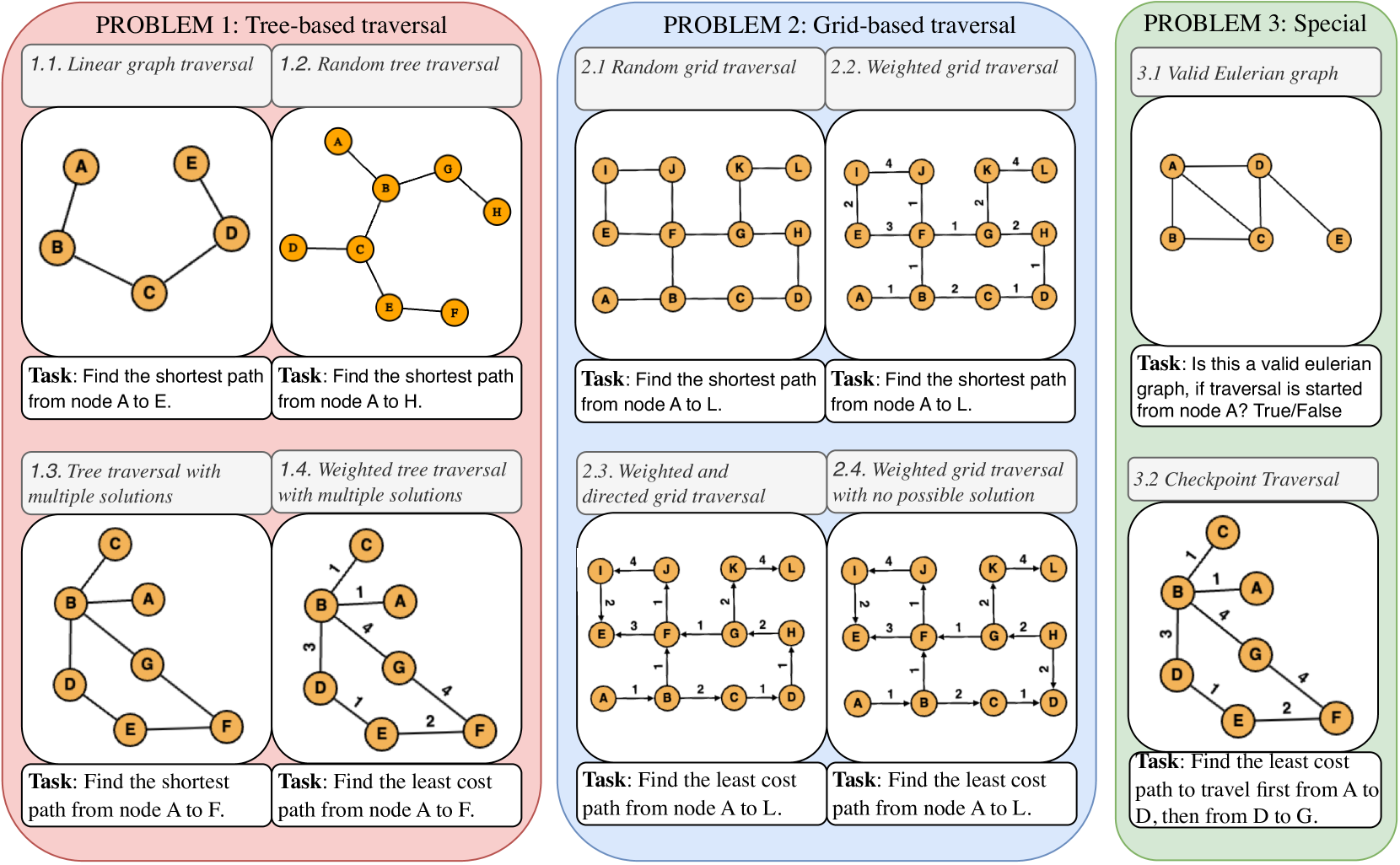
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024
Joint Embeddings for Graph Instruction Tuning
Vlad Argatu, Aaron Haag, Oliver Lohse
0
0
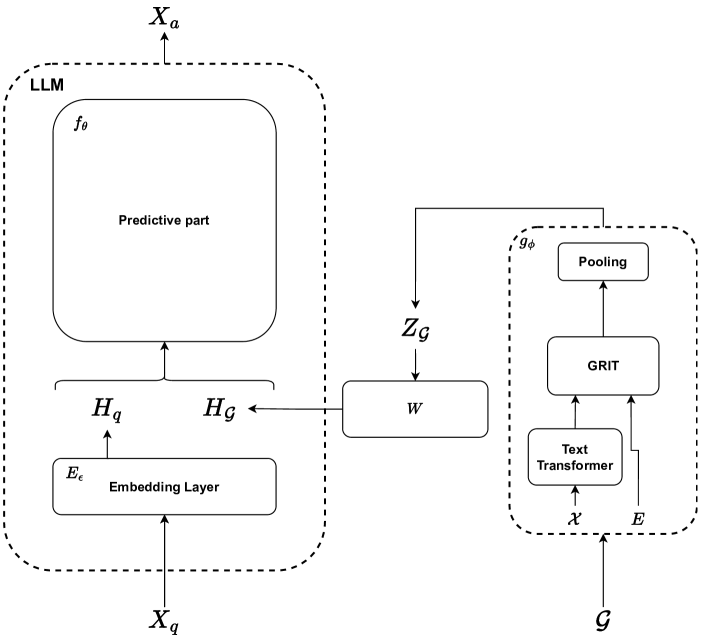
Large Language Models (LLMs) have achieved impressive performance in text understanding and have become an essential tool for building smart assistants. Originally focusing on text, they have been enhanced with multimodal capabilities in recent works that successfully built visual instruction following assistants. As far as the graph modality goes, however, no such assistants have yet been developed. Graph structures are complex in that they represent relation between different features and are permutation invariant. Moreover, representing them in purely textual form does not always lead to good LLM performance even for finetuned models. As a result, there is a need to develop a new method to integrate graphs in LLMs for general graph understanding. This work explores the integration of the graph modality in LLM for general graph instruction following tasks. It aims at producing a deep learning model that enhances an underlying LLM with graph embeddings and trains it to understand them and to produce, given an instruction, an answer grounded in the graph representation. The approach performs significantly better than a graph to text approach and remains consistent even for larger graphs.
6/3/2024
💬
Making Large Language Models Perform Better in Knowledge Graph Completion
Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Wen Zhang, Huajun Chen
0
0
Large language model (LLM) based knowledge graph completion (KGC) aims to predict the missing triples in the KGs with LLMs. However, research about LLM-based KGC fails to sufficiently harness LLMs' inference proficiencies, overlooking critical structural information integral to KGs. In this paper, we explore methods to incorporate structural information into the LLMs, with the overarching goal of facilitating structure-aware reasoning. We first discuss on the existing LLM paradigms like in-context learning and instruction tuning, proposing basic structural information injection approaches. Then we propose a Knowledge Prefix Adapter (KoPA) to fulfill this stated goal. The KoPA uses a structural pre-training phase to comprehend the intricate entities and relations within KGs, representing them as structural embeddings. Then KoPA communicates such cross-modal structural information understanding to the LLMs through a knowledge prefix adapter which projects the structural embeddings into the textual space and obtains virtual knowledge tokens positioned as a prefix of the input prompt. We conduct comprehensive experiments and provide incisive analysis concerning how the introduction of cross-modal structural information would be better for LLM's factual knowledge reasoning ability. Our code and data are available at https://github.com/zjukg/KoPA .
4/16/2024
A Survey of Large Language Models for Graphs
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, Chao Huang
0
0
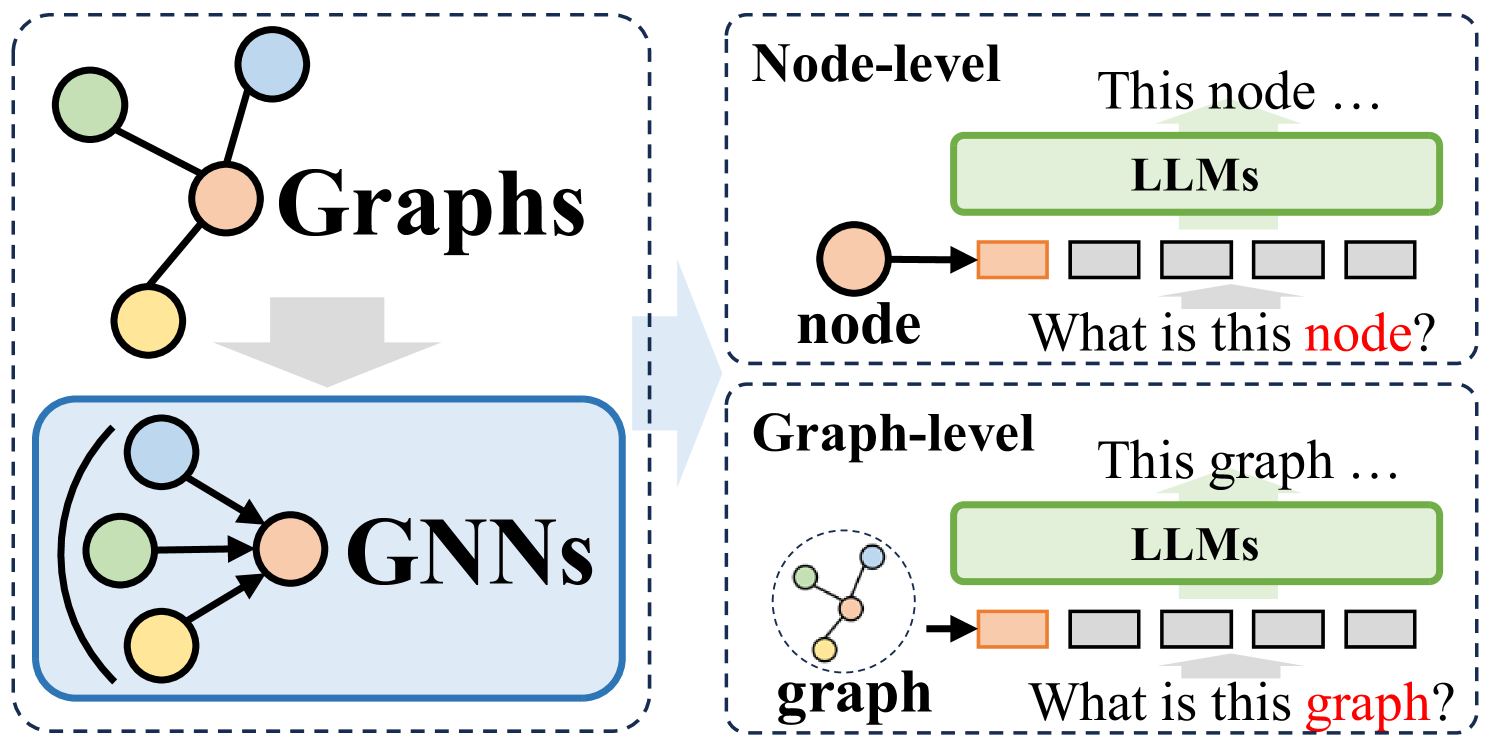
Graphs are an essential data structure utilized to represent relationships in real-world scenarios. Prior research has established that Graph Neural Networks (GNNs) deliver impressive outcomes in graph-centric tasks, such as link prediction and node classification. Despite these advancements, challenges like data sparsity and limited generalization capabilities continue to persist. Recently, Large Language Models (LLMs) have gained attention in natural language processing. They excel in language comprehension and summarization. Integrating LLMs with graph learning techniques has attracted interest as a way to enhance performance in graph learning tasks. In this survey, we conduct an in-depth review of the latest state-of-the-art LLMs applied in graph learning and introduce a novel taxonomy to categorize existing methods based on their framework design. We detail four unique designs: i) GNNs as Prefix, ii) LLMs as Prefix, iii) LLMs-Graphs Integration, and iv) LLMs-Only, highlighting key methodologies within each category. We explore the strengths and limitations of each framework, and emphasize potential avenues for future research, including overcoming current integration challenges between LLMs and graph learning techniques, and venturing into new application areas. This survey aims to serve as a valuable resource for researchers and practitioners eager to leverage large language models in graph learning, and to inspire continued progress in this dynamic field. We consistently maintain the related open-source materials at url{https://github.com/HKUDS/Awesome-LLM4Graph-Papers}.
6/26/2024