Can LLMs perform structured graph reasoning?
2402.01805
0
0
Abstract
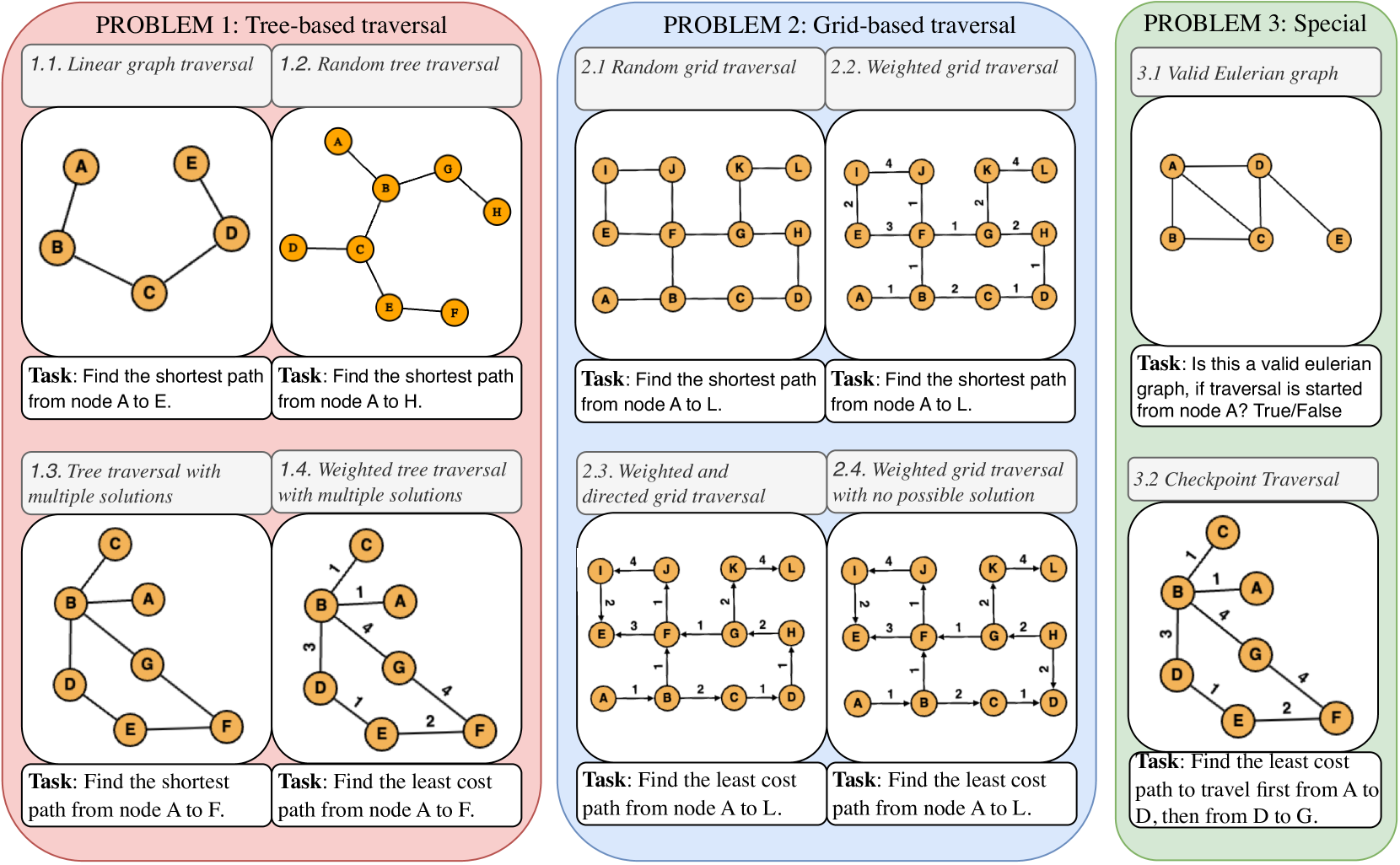
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores the limitations of graph reasoning in large language models (LLMs)
- It examines the ability of LLMs to perform reasoning tasks that require understanding and navigating graph structures
- The researchers designed a benchmark to test LLM performance on various graph reasoning tasks
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Researchers are interested in whether these models can also reason about more complex information, like the relationships between different concepts represented in a graph.
A graph is a way of visualizing information as a set of nodes (representing individual concepts) connected by edges (representing the relationships between them). Reasoning about graphs requires understanding how these nodes and edges are structured and using that knowledge to answer questions or solve problems.
In this paper, the researchers created a benchmark - a standardized set of tasks - to test the graph reasoning abilities of LLMs. They looked at how well these models could answer questions, follow paths through a graph, and make inferences based on the graph structure.
The results suggest that while LLMs can perform some basic graph reasoning, they still struggle with more advanced tasks that require deeper understanding of the graph structure. The researchers hope that this benchmark can help guide future research to improve the graph reasoning capabilities of LLMs.
Technical Explanation
The paper Exploring the Limitations of Graph Reasoning in Large Language Models examines the ability of large language models (LLMs) to perform reasoning tasks that require understanding and navigating graph structures.
The researchers designed a benchmark called GRAIL (Graph Reasoning Ability in Language Models) to test the graph reasoning capabilities of LLMs. GRAIL includes tasks that assess a model's ability to answer questions based on graph information, follow paths through a graph, and make inferences about the relationships between graph entities.
The researchers evaluated several state-of-the-art LLMs, including GPT-3, PaLM, and Megatron-LM, on the GRAIL benchmark. The results showed that while the LLMs were able to perform some basic graph reasoning tasks, they struggled with more advanced tasks that required deeper understanding of the graph structure.
For example, the models performed well on tasks that involved simple retrieval of information from the graph, such as answering questions about the attributes of a specific entity. However, they had more difficulty with tasks that required reasoning about the relationships between multiple entities or following complex paths through the graph.
The paper suggests that the limitations of LLMs in graph reasoning may be due to their fundamental architecture, which is primarily based on processing and generating text rather than explicitly modeling graph structures. The researchers propose that incorporating more graph-specific inductive biases and reasoning mechanisms into LLMs could help improve their performance on these types of tasks.
Critical Analysis
The paper provides a thorough and well-designed benchmark for evaluating the graph reasoning capabilities of large language models. The researchers have carefully considered a range of graph reasoning tasks that cover different levels of complexity, from simple retrieval to more advanced relational and path-based reasoning.
One potential limitation of the study is that it focuses solely on the performance of LLMs, without comparing their performance to other types of models that may be more specialized for graph reasoning, such as graph neural networks or knowledge graph embedding models. It would be interesting to see how the LLMs' performance compares to these other approaches.
Additionally, the paper does not delve deeply into the specific reasons why LLMs struggle with certain graph reasoning tasks. While the researchers propose that the LLMs' text-centric architecture may be a limiting factor, more detailed analysis of the models' internal representations and reasoning processes could provide further insights.
Nevertheless, the GRAIL benchmark and the findings presented in this paper represent an important step forward in understanding the limitations of current LLMs and identifying areas for future research to improve their graph reasoning abilities. As the field of AI continues to advance, the ability to reason about and understand complex graph structures will become increasingly crucial for a wide range of applications.
Conclusion
The paper "Exploring the Limitations of Graph Reasoning in Large Language Models" provides a comprehensive evaluation of the graph reasoning capabilities of state-of-the-art large language models. The researchers designed a benchmark called GRAIL to assess the models' ability to answer questions, follow paths, and make inferences based on graph structures.
The results suggest that while LLMs can perform some basic graph reasoning tasks, they still struggle with more advanced tasks that require deeper understanding of the graph structure. This indicates that the current text-centric architecture of LLMs may not be well-suited for certain types of reasoning that rely on the explicit representation and manipulation of graph-based information.
The insights from this paper can help guide future research to improve the graph reasoning capabilities of large language models, which will be increasingly important as these models are applied to a wider range of real-world problems that involve complex, interconnected data. By addressing the limitations identified in this study, researchers may be able to develop LLMs that can more effectively leverage the power of graph-based reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
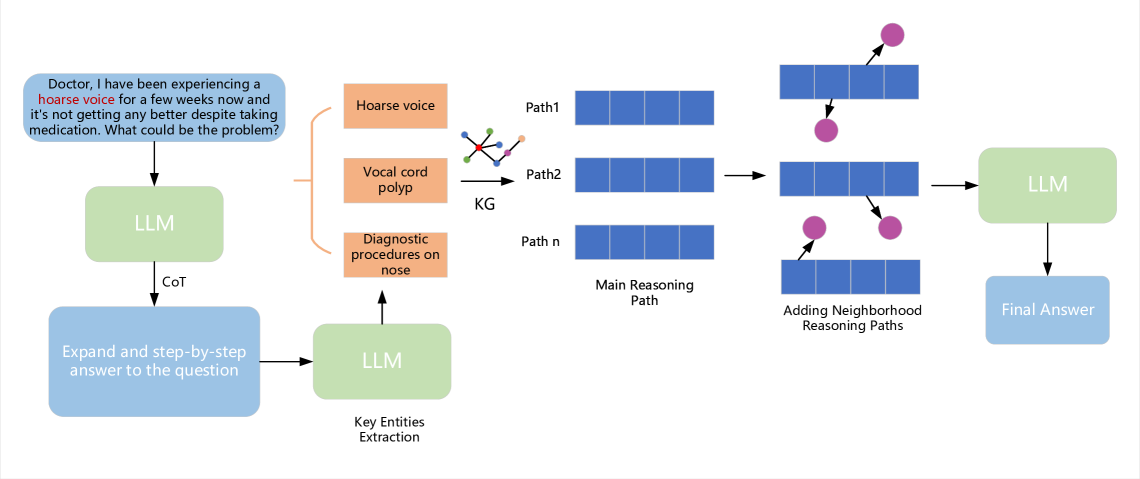
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
0
0
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
4/23/2024
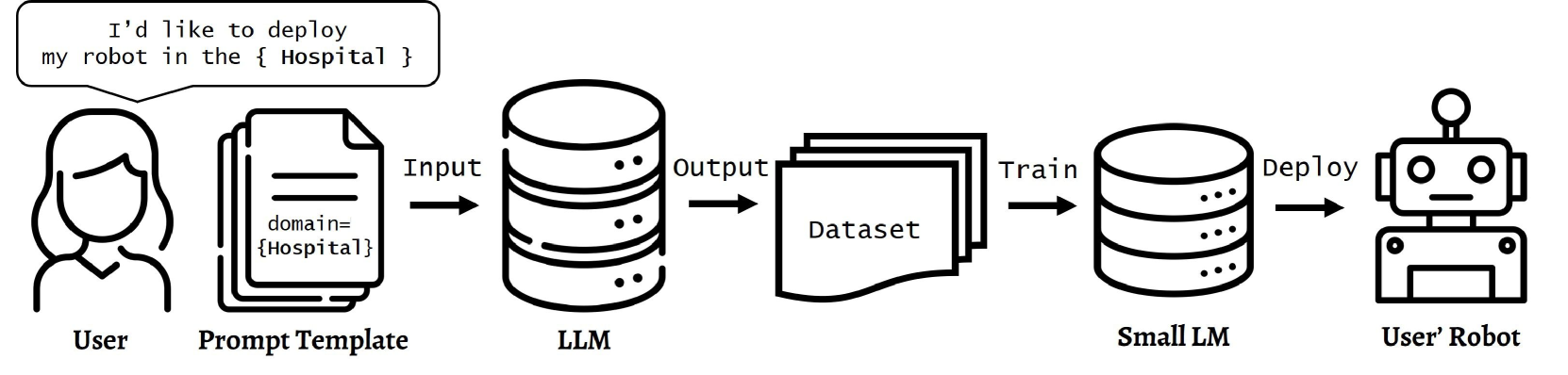
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Gawon Choi, Hyemin Ahn
0
0
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
4/8/2024
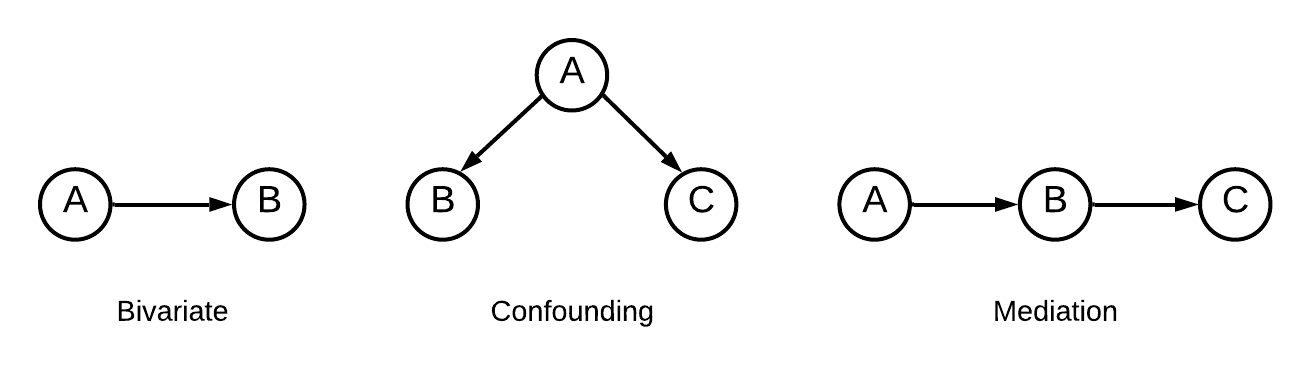
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024