Making Large Language Models Perform Better in Knowledge Graph Completion
2310.06671
0
0
💬
Abstract
Large language model (LLM) based knowledge graph completion (KGC) aims to predict the missing triples in the KGs with LLMs. However, research about LLM-based KGC fails to sufficiently harness LLMs' inference proficiencies, overlooking critical structural information integral to KGs. In this paper, we explore methods to incorporate structural information into the LLMs, with the overarching goal of facilitating structure-aware reasoning. We first discuss on the existing LLM paradigms like in-context learning and instruction tuning, proposing basic structural information injection approaches. Then we propose a Knowledge Prefix Adapter (KoPA) to fulfill this stated goal. The KoPA uses a structural pre-training phase to comprehend the intricate entities and relations within KGs, representing them as structural embeddings. Then KoPA communicates such cross-modal structural information understanding to the LLMs through a knowledge prefix adapter which projects the structural embeddings into the textual space and obtains virtual knowledge tokens positioned as a prefix of the input prompt. We conduct comprehensive experiments and provide incisive analysis concerning how the introduction of cross-modal structural information would be better for LLM's factual knowledge reasoning ability. Our code and data are available at https://github.com/zjukg/KoPA .
Create account to get full access
Overview
- This paper explores methods to incorporate structural information from knowledge graphs (KGs) into large language models (LLMs) to improve their reasoning abilities.
- Existing LLM-based knowledge graph completion (KGC) approaches fail to fully leverage the structural information inherent in KGs.
- The authors propose a new method called Knowledge Prefix Adapter (KoPA) that uses a structural pre-training phase to learn embeddings of KG entities and relations, and then injects this structural knowledge into LLMs through a knowledge prefix.
Plain English Explanation
Knowledge graphs (KGs) are structured collections of facts, represented as entities (like people, places, or things) and the relationships between them. Large language models (LLMs) are powerful AI systems that can understand and generate human-like text.
The goal of this research is to find a way to combine the strengths of LLMs and KGs to improve the models' ability to reason about and draw insights from the structured information in KGs. Existing approaches have struggled to fully incorporate the structural knowledge in KGs into LLMs.
The key idea behind the Knowledge Prefix Adapter (KoPA) is to first learn embeddings that capture the structure of the KG during a pre-training phase. These embeddings are then used to create a "knowledge prefix" that is added to the input prompt for the LLM. This allows the LLM to leverage the structural information from the KG when generating its output.
The authors show that this approach leads to improved performance on tasks that require reasoning about factual knowledge, compared to LLMs that don't have access to the structural information.
Technical Explanation
The paper proposes the Knowledge Prefix Adapter (KoPA) as a method to incorporate structural information from knowledge graphs (KGs) into large language models (LLMs) for improved reasoning abilities.
The key steps in the KoPA approach are:
-
Structural Pre-training: The authors first train a model to learn embeddings that capture the structure of entities and relations in the KG. This involves learning representations for each entity and relation that encode their connections and properties within the KG.
-
Knowledge Prefix Adapter: The structural embeddings learned in the pre-training phase are then used to create a "knowledge prefix" that is appended to the input prompt for the LLM. This prefix acts as a structured representation of relevant knowledge from the KG, which the LLM can then leverage when generating its output.
The authors conduct extensive experiments to evaluate the impact of the KoPA approach on the factual knowledge reasoning abilities of LLMs. They compare the performance of LLMs with and without the KoPA knowledge prefix on a range of benchmarks, and provide detailed analysis of the results.
The findings indicate that the introduction of structural information through the knowledge prefix significantly boosts the LLM's performance on tasks that require reasoning about factual knowledge, compared to LLMs that do not have access to this structural information.
Critical Analysis
The paper presents a novel and promising approach to incorporating structured knowledge from KGs into LLMs. The authors demonstrate the value of this approach through comprehensive experiments and analysis.
However, the paper does not address some potential limitations and areas for further research:
- The impact of the KoPA approach may be limited to tasks that directly require factual knowledge reasoning. Its benefits for more open-ended language understanding and generation tasks are not explored.
- The pre-training process to learn the structural embeddings is computationally intensive and may not be feasible for very large KGs. Scalability of the approach is not discussed.
- The paper does not provide insights into the types of structural information that are most valuable for improving LLM reasoning, or how the knowledge prefix could be further optimized.
Overall, the KoPA approach represents an important step forward in bridging the gap between the strengths of LLMs and the structured knowledge in KGs. Further research is needed to address the limitations and explore the broader applicability of this technique.
Conclusion
This paper presents a novel method called the Knowledge Prefix Adapter (KoPA) that aims to enhance the factual reasoning abilities of large language models (LLMs) by incorporating structural information from knowledge graphs (KGs).
The key innovation of the KoPA approach is the use of a structural pre-training phase to learn embeddings that capture the entities and relations within a KG, and then injecting this structural knowledge into the LLM through a knowledge prefix added to the input prompt.
The authors demonstrate the effectiveness of this approach through comprehensive experiments, showing significant improvements in the LLM's performance on tasks that require reasoning about factual knowledge. This research represents an important step towards better leveraging the strengths of both LLMs and structured knowledge sources like KGs.
While the paper does not address all the potential limitations and areas for further exploration, the KoPA method offers a promising direction for enhancing the reasoning capabilities of LLMs and unlocking new applications at the intersection of language models and structured knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
New!Enhancing Text-based Knowledge Graph Completion with Zero-Shot Large Language Models: A Focus on Semantic Enhancement
Rui Yang, Jiahao Zhu, Jianping Man, Li Fang, Yi Zhou
0
0
The design and development of text-based knowledge graph completion (KGC) methods leveraging textual entity descriptions are at the forefront of research. These methods involve advanced optimization techniques such as soft prompts and contrastive learning to enhance KGC models. The effectiveness of text-based methods largely hinges on the quality and richness of the training data. Large language models (LLMs) can utilize straightforward prompts to alter text data, thereby enabling data augmentation for KGC. Nevertheless, LLMs typically demand substantial computational resources. To address these issues, we introduce a framework termed constrained prompts for KGC (CP-KGC). This CP-KGC framework designs prompts that adapt to different datasets to enhance semantic richness. Additionally, CP-KGC employs a context constraint strategy to effectively identify polysemous entities within KGC datasets. Through extensive experimentation, we have verified the effectiveness of this framework. Even after quantization, the LLM (Qwen-7B-Chat-int4) still enhances the performance of text-based KGC methods footnote{Code and datasets are available at href{https://github.com/sjlmg/CP-KGC}{https://github.com/sjlmg/CP-KGC}}. This study extends the performance limits of existing models and promotes further integration of KGC with LLMs.
6/28/2024
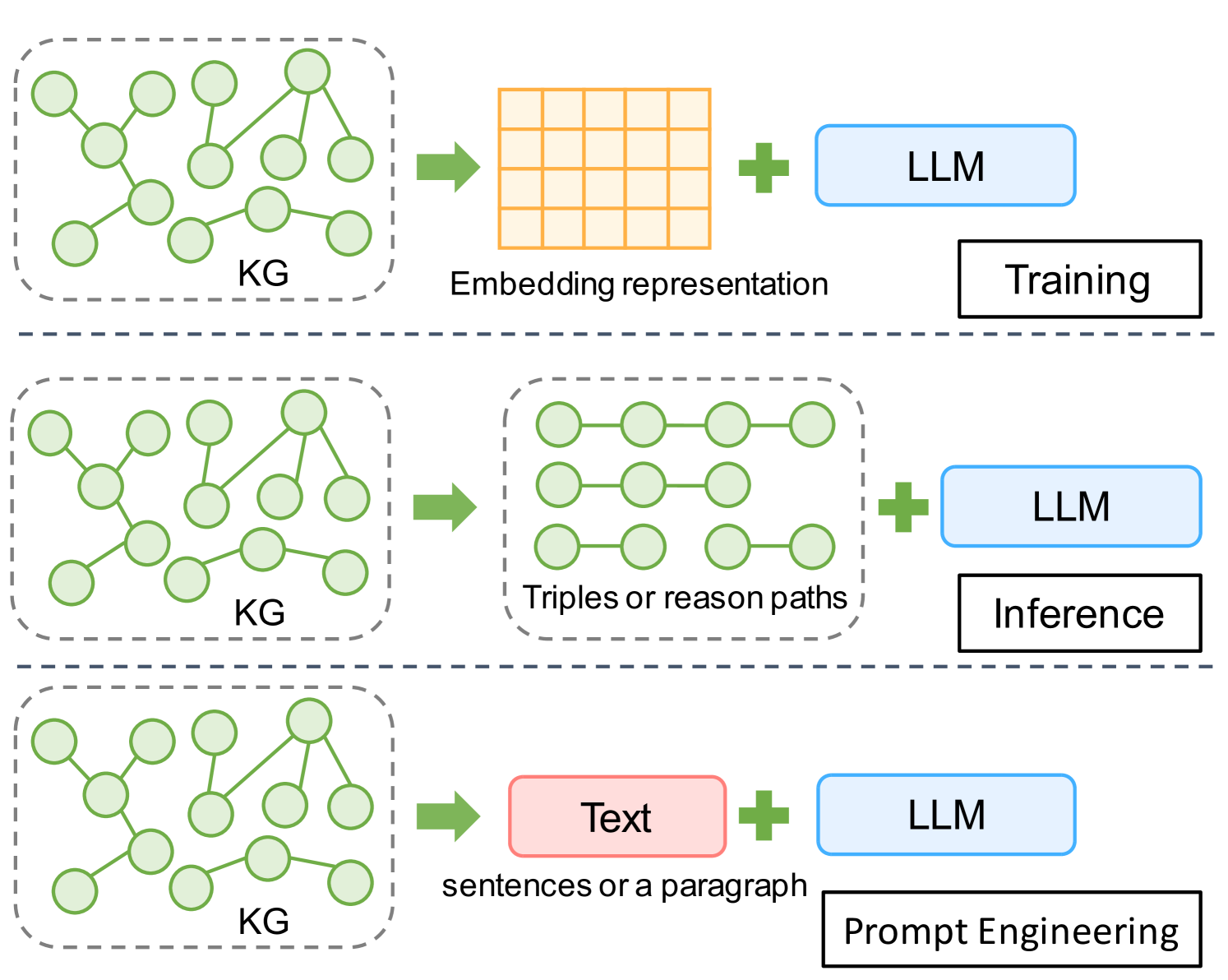
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024

Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Ran Song, Shizhu He, Shengxiang Gao, Li Cai, Kang Liu, Zhengtao Yu, Jun Zhao
0
0
Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
6/27/2024
🚀
Can LLMs Effectively Leverage Graph Structural Information through Prompts, and Why?
Jin Huang, Xingjian Zhang, Qiaozhu Mei, Jiaqi Ma
0
0
Large language models (LLMs) are gaining increasing attention for their capability to process graphs with rich text attributes, especially in a zero-shot fashion. Recent studies demonstrate that LLMs obtain decent text classification performance on common text-rich graph benchmarks, and the performance can be improved by appending encoded structural information as natural languages into prompts. We aim to understand why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs. First, we rule out the concern of data leakage by curating a novel leakage-free dataset and conducting a comparative analysis alongside a previously widely-used dataset. Second, as past work usually encodes the ego-graph by describing the graph structure in natural language, we ask the question: do LLMs understand the graph structure in accordance with the intent of the prompt designers? Third, we investigate why LLMs can improve their performance after incorporating structural information. Our exploration of these questions reveals that (i) there is no substantial evidence that the performance of LLMs is significantly attributed to data leakage; (ii) instead of understanding prompts as graph structures as intended by the prompt designers, LLMs tend to process prompts more as contextual paragraphs and (iii) the most efficient elements of the local neighborhood included in the prompt are phrases that are pertinent to the node label, rather than the graph structure.
6/18/2024