Joint Embeddings for Graph Instruction Tuning
2405.20684
0
0
Abstract
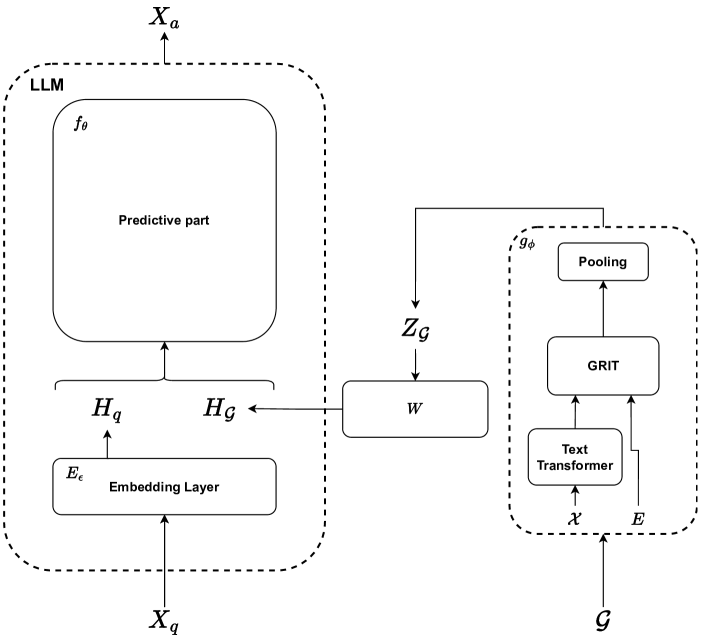
Large Language Models (LLMs) have achieved impressive performance in text understanding and have become an essential tool for building smart assistants. Originally focusing on text, they have been enhanced with multimodal capabilities in recent works that successfully built visual instruction following assistants. As far as the graph modality goes, however, no such assistants have yet been developed. Graph structures are complex in that they represent relation between different features and are permutation invariant. Moreover, representing them in purely textual form does not always lead to good LLM performance even for finetuned models. As a result, there is a need to develop a new method to integrate graphs in LLMs for general graph understanding. This work explores the integration of the graph modality in LLM for general graph instruction following tasks. It aims at producing a deep learning model that enhances an underlying LLM with graph embeddings and trains it to understand them and to produce, given an instruction, an answer grounded in the graph representation. The approach performs significantly better than a graph to text approach and remains consistent even for larger graphs.
Create account to get full access
Overview
- This paper explores the use of joint embeddings to improve the performance of large language models (LLMs) on graph-related tasks through instruction tuning.
- The researchers propose a novel approach called GraphGPT that leverages the power of LLMs while incorporating graph-specific knowledge.
- The paper also provides a broader survey of the use of LLMs for graph-related tasks and discusses parameter-efficient tuning techniques to make the process more scalable.
Plain English Explanation
The paper explores a new way to improve the performance of large language models (LLMs) on tasks involving graphs. Graphs are a way of representing relationships between different things, and they are used in many important applications like social networks, transportation planning, and drug discovery.
The researchers developed a technique called GraphGPT that combines the powerful natural language understanding capabilities of LLMs with specific knowledge about graph-related concepts. By training the LLM on a diverse set of instructions related to graph tasks, the model can learn to better understand and reason about the structure and properties of graphs.
This approach is part of a broader trend of using LLMs for graph-related tasks, which has shown promising results. The paper also discusses techniques for tuning LLMs efficiently so that they can be applied to a wide range of graph problems without requiring extensive retraining.
Technical Explanation
The paper proposes a novel approach called GraphGPT that combines large language models (LLMs) with graph-specific knowledge through instruction tuning. The researchers hypothesize that by training LLMs on a diverse set of instructions related to graph tasks, the model can learn to better understand and reason about the structure and properties of graphs.
The key technical contributions of the paper include:
-
A framework for joint embedding of graph structures and natural language instructions, which allows the LLM to learn a shared representation for both modalities.
-
Techniques for parameter-efficient tuning of LLMs to make the instruction tuning process more scalable and applicable to a wide range of graph-related tasks.
-
Extensive evaluation of the GraphGPT approach on a diverse set of graph tasks, demonstrating significant performance improvements over existing methods.
The authors also provide a broader survey of the use of LLMs for graph-related tasks, highlighting the potential of this approach and the challenges that still need to be addressed.
Critical Analysis
The paper presents a compelling approach for leveraging the power of large language models (LLMs) for graph-related tasks. The key strengths of the proposed GraphGPT framework include its ability to effectively combine graph-specific knowledge with the strong natural language understanding capabilities of LLMs, as well as the techniques for parameter-efficient tuning that make the approach more scalable.
However, the paper also acknowledges some limitations and areas for further research. For example, the instruction tuning process relies on the availability of a diverse set of high-quality instructions, which may not always be easy to obtain. Additionally, the paper does not explore the potential biases or limitations of the LLM itself, which could be an important consideration when applying the technique to real-world graph problems.
Further research could also investigate the robustness of the GraphGPT approach to different types of graph structures and tasks, as well as explore ways to make the instruction tuning process more automated and efficient. Additionally, counter-intuitive findings about the potential of LLMs to outperform specialized graph machine learning models in certain tasks deserve further scrutiny and exploration.
Conclusion
This paper presents a novel approach called GraphGPT that leverages the power of large language models (LLMs) for graph-related tasks through instruction tuning. The key innovation is the joint embedding of graph structures and natural language instructions, which allows the LLM to learn a shared representation that can be effectively applied to a wide range of graph problems.
The paper also provides a broader survey of the use of LLMs for graph-related tasks and discusses techniques for parameter-efficient tuning to make the approach more scalable. While the proposed GraphGPT framework shows promising results, the paper also highlights areas for further research, such as the need to address potential biases and limitations of the LLM itself.
Overall, this work represents an important step forward in the integration of graph machine learning and large language models, and its insights could have significant implications for a wide range of applications that rely on graph-based representations and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Graph Machine Learning in the Era of Large Language Models (LLMs)
Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, Qing Li
0
0
Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
6/5/2024
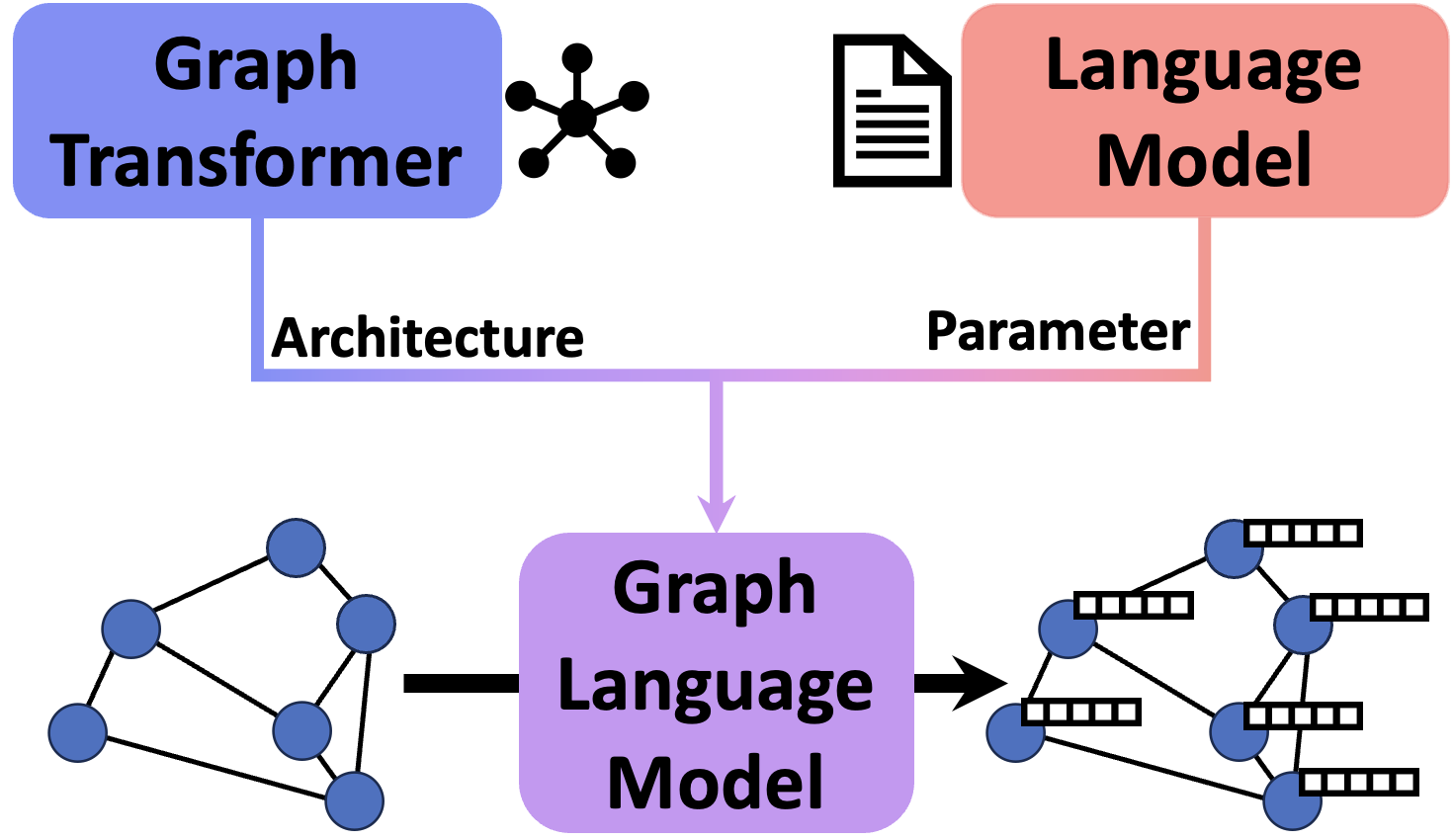
Graph Language Models
Moritz Plenz, Anette Frank
0
0
While Language Models (LMs) are the workhorses of NLP, their interplay with structured knowledge graphs (KGs) is still actively researched. Current methods for encoding such graphs typically either (i) linearize them for embedding with LMs -- which underutilize structural information, or (ii) use Graph Neural Networks (GNNs) to preserve the graph structure -- but GNNs cannot represent text features as well as pretrained LMs. In our work we introduce a novel LM type, the Graph Language Model (GLM), that integrates the strengths of both approaches and mitigates their weaknesses. The GLM parameters are initialized from a pretrained LM to enhance understanding of individual graph concepts and triplets. Simultaneously, we design the GLM's architecture to incorporate graph biases, thereby promoting effective knowledge distribution within the graph. This enables GLMs to process graphs, texts, and interleaved inputs of both. Empirical evaluations on relation classification tasks show that GLM embeddings surpass both LM- and GNN-based baselines in supervised and zero-shot setting, demonstrating their versatility.
6/4/2024

Dr.E Bridges Graphs with Large Language Models through Words
Zipeng Liu, Likang Wu, Ming He, Zhong Guan, Hongke Zhao, Nan Feng
0
0
Significant efforts have been directed toward integrating powerful Large Language Models (LLMs) with diverse modalities, particularly focusing on the fusion of vision, language, and audio data. However, the graph-structured data, inherently rich in structural and domain-specific knowledge, have not yet been gracefully adapted to LLMs. Existing methods either describe the graph with raw text, suffering the loss of graph structural information, or feed Graph Neural Network (GNN) embeddings directly into LLM at the cost of losing semantic representation. To bridge this gap, we introduce an innovative, end-to-end modality-aligning framework, equipped with a pretrained Dual-Residual Vector Quantized-Variational AutoEncoder (Dr.E). This framework is specifically designed to facilitate token-level alignment with LLMs, enabling an effective translation of the intrinsic `language' of graphs into comprehensible natural language. Our experimental evaluations on standard GNN node classification tasks demonstrate competitive performance against other state-of-the-art approaches. Additionally, our framework ensures interpretability, efficiency, and robustness, with its effectiveness further validated under both fine-tuning and few-shot settings. This study marks the first successful endeavor to achieve token-level alignment between GNNs and LLMs.
6/26/2024
🚀
Can LLMs Effectively Leverage Graph Structural Information through Prompts, and Why?
Jin Huang, Xingjian Zhang, Qiaozhu Mei, Jiaqi Ma
0
0
Large language models (LLMs) are gaining increasing attention for their capability to process graphs with rich text attributes, especially in a zero-shot fashion. Recent studies demonstrate that LLMs obtain decent text classification performance on common text-rich graph benchmarks, and the performance can be improved by appending encoded structural information as natural languages into prompts. We aim to understand why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs. First, we rule out the concern of data leakage by curating a novel leakage-free dataset and conducting a comparative analysis alongside a previously widely-used dataset. Second, as past work usually encodes the ego-graph by describing the graph structure in natural language, we ask the question: do LLMs understand the graph structure in accordance with the intent of the prompt designers? Third, we investigate why LLMs can improve their performance after incorporating structural information. Our exploration of these questions reveals that (i) there is no substantial evidence that the performance of LLMs is significantly attributed to data leakage; (ii) instead of understanding prompts as graph structures as intended by the prompt designers, LLMs tend to process prompts more as contextual paragraphs and (iii) the most efficient elements of the local neighborhood included in the prompt are phrases that are pertinent to the node label, rather than the graph structure.
6/18/2024