Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning
2403.20046
0
0

Abstract
Recent works have shown the benefits to LLMs from fine-tuning golden-standard Chain-of-Thought (CoT) rationales or using them as correct examples in few-shot prompting. While humans can indeed imitate correct examples, learning from our mistakes is another vital aspect of human cognition. Hence, a question naturally arises: textit{can LLMs learn and benefit from their mistakes, especially for their reasoning? } This study investigates this problem from both the prompting and model-tuning perspectives. We begin by introducing textsc{CoTErrorSet}, a new benchmark with 609,432 questions, each designed with both correct and error references, and demonstrating the types and reasons for making such mistakes. To explore the effectiveness of those mistakes, we design two methods: (1) textbf{Self-rethinking} prompting guides LLMs to rethink whether they have made similar previous mistakes; and (2) textbf{Mistake tuning} involves finetuning models in both correct and incorrect reasoning domains, rather than only tuning models to learn ground truth in traditional methodology. We conduct a series of experiments to prove LLMs can obtain benefits from mistakes in both directions. Our two methods offer potentially cost-effective strategies by leveraging errors to enhance reasoning capabilities, which costs significantly less than creating meticulously hand-crafted golden references. We ultimately make a thorough analysis of the reasons behind LLMs' errors, which provides directions that future research needs to overcome. textsc{CoTErrorSet} will be published soon on texttt{url{https://github.com/YookiTong/Learn-from-Mistakes-CotErrorSet}}.
Create account to get full access
Introduction
The provided text discusses how large language models (LLMs) can be further improved by leveraging their mistakes during the learning process. Key points:
-
LLMs have demonstrated strong capabilities across various tasks, but there is a need to better align their reasoning with human logic. Recent studies have explored Chain-of-Thought (CoT) prompting to instruct LLMs to solve problems in a step-by-step manner.
-
Another critical learning pattern for humans is rethinking and learning from past mistakes, but few studies have focused on this for LLMs.
-
The authors aim to explore the potential for LLMs to learn from their mistakes to boost reasoning abilities. They created a large dataset called CoTErrorSet, which contains over 600,000 questions with both correct references and incorrect rationales collected from LLM responses.
-
Two innovative approaches are introduced: 1) "mistake tuning" that incorporates both correct and incorrect rationales during fine-tuning, and 2) "self-rethinking" that exposes LLMs to both correct and incorrect rationales to iteratively refine their answers.
-
Experiments show these methods consistently improve LLM performance across diverse reasoning tasks, and the authors provide insights into common error types exhibited by LLMs.
Related Work
This paper explores the potential of using large language models (LLMs) to develop human-like reasoning capabilities. The authors highlight various logical and structural reasoning strategies that have been proposed to better align LLMs' thinking processes with those of humans. These enhanced reasoning approaches have been applied to tasks such as commonsense reasoning, logical reasoning, and mathematical reasoning, with promising results.
The focus of this work is to investigate whether LLMs can benefit from rethinking and learning from previous mistakes, which is a key learning pattern in humans. The authors discuss several studies that have explored techniques for adjusting LLMs' reasoning pathways to arrive at better solutions. These include the use of "self-improve" methods that employ chain-of-thought and self-consistency approaches, as well as "self-refine" techniques that encourage LLMs to autonomously correct their outputs.
However, the paper notes that some researchers have argued that LLMs face challenges in self-correcting their responses in the absence of external feedback, and that such attempts might even deteriorate their performance under certain conditions. To address this, the authors suggest fine-tuning LLMs using pairs of errors and their respective corrections generated by a more advanced model, such as GPT-4, as a supervisory mechanism.
Importantly, the paper emphasizes that this work is pioneering in highlighting the impact of exposing LLMs to mistake examples on in-context learning. The authors' experiments reveal that during model tuning, learning from mistakes can inherently enhance itself merely by being exposed to correct examples and errors, without depending on explicit corrections from teacher models.
A Novel Dataset: CoTErrorSet
The paper introduces CoTErrorSet, a novel benchmark dataset for investigating how incorrect rationales can contribute to the reasoning performance of large language models (LLMs). The dataset is built upon various domains, including multiple-choice QA, extractive QA, closed-book QA, formal logic, natural language inference, and arithmetic reasoning.
The questions and references in the dataset are obtained from existing datasets, and each task includes an incorrect response generated by PaLM2, along with demonstrations from PaLM2 on why it made such mistakes. This systematic collection of incorrect rationales aims to provide a new perspective for improving LLM reasoning performance.
To gain a better understanding of the diverse error types in the dataset, the paper employs an LLM-based unsupervised clustering approach to group the errors into more general categories, such as calculation error, numeric error, logical error, commonsense error, linguistic error, and context error. This error analysis provides insights for future enhancement efforts.
Our Methodology: Self-rethinking
The text describes an innovative approach called "self-rethinking" to encourage large language models (LLMs) to consider if they are repeating past errors. The method starts with an initial chain-of-thought (CoT) reasoning, then the model uses the provided reasoning outputs and a random selection of examples from a CoTErrorSet to assess if the most recent response includes similar inaccuracies. If errors are detected, the model formulates a new rationale and undergoes the evaluation process again, repeating this cycle until the model deems its latest answer to be correct or it reaches a set limit of evaluation rounds. The core of self-rethinking lies in the backward-checking stage, where the LLM reviews its reasoning chain with a specific focus on the error types it previously identified. This targeted review helps the LLM to consciously avoid repeating the same types of mistakes it has made in the past. The process includes a loop for error correction and confirmation, and a crucial repeating boundary to prevent the LLM from being caught in an endless loop of self-rethinking.
Our Methodology: Mistake Tuning
The text introduces "mistake tuning," a method to further improve large language models' (LLMs') abilities to distinguish between correct and incorrect reasoning. Mistake tuning involves finetuning LLMs on a combination of correct and incorrect rationales, where the rationales are prefixed with "[CORRECT RATIONALE]" and "[INCORRECT RATIONALE]" respectively.
This process allows LLMs to learn from the implicit reasons and types of mistakes they make during chain-of-thought reasoning, as outlined in the "self-rethinking" approach. The training objective is to maximize the likelihood of the correct rationale given the previous rationales.
Mistake tuning is presented as a cost-effective, straightforward, and efficient alternative to improve LLMs' reasoning abilities without the need for additional annotated golden reasoning references. Previous work has shown that pretraining on controlled signals based on human feedback can lead to better content generation by LLMs.
Experiments
The text summarizes a series of experiments conducted to compare the proposed self-rethinking methods with existing approaches on arithmetic and commonsense reasoning benchmarks. The experiment setup involved selecting various baselines, including standard prompting, Chain-of-Thought (CoT), self-refine, and self-consistency, as well as using the PaLM2 and GPT4 models. The benchmarks considered were GSM8K, AQuA, MathQA, Openbook, LogiQA, and Critical Reasoning in MARB.
The results showed that the self-rethinking method achieved superior performance with significant improvements, particularly in GSM8K, AQuA, MathQA, and LogiQA, outperforming self-consistency under similar computing costs. However, the self-rethinking method fell short of self-refine's results on the MathQA dataset, which is specifically tailored towards operation-based arithmetic problems.
The paper also presented results on the 8-shot examples of CoT and self-rethinking using the PaLM2 model, demonstrating a clear advantage of the self-rethinking method over the standard 8-shot CoT approach in few-shot learning scenarios for complex problem-solving tasks.
Additionally, the paper explored the concept of "mistake tuning," where both correct and incorrect rationales were combined to fine-tune the Flan-T5 models. The results showed that mistake tuning consistently outperformed standard fine-tuning with only correct rationales, suggesting the value of engaging with incorrect reasoning to enhance the models' problem-solving and reasoning capabilities.
In conclusion, the self-rethinking method proved effective in improving the accuracy and reliability of responses in large language models, particularly in tasks requiring strong logic and prone to minor errors. The paper also highlighted the potential benefits of incorporating incorrect rationales in the training process to further enhance the models' problem-solving and reasoning abilities.
Further Studies

The paper examines the impact of different numbers of rethinking iterations, denoted as k, on the performance of the framework on two benchmarks - GSM8K and LogiQA. As k increases from 1 to 24, the GSM8K performance increases by 8.11% and the LogiQA performance increases by 12.37%, indicating a positive correlation between the number of rethinking iterations and the reasoning abilities of the language models.
The paper also includes an ablation study on the rethinking process, examining the impact of different component combinations in the prompts guiding the language models to self-rethink. The results show that the inclusion or exclusion of different components has varying effects on the accuracy in the GSM8K and LogiQA domains, but the overall performance across the different component combinations is relatively similar, indicating the flexibility and stability of the method.
Unveiling LLM’s Reasoning Errors
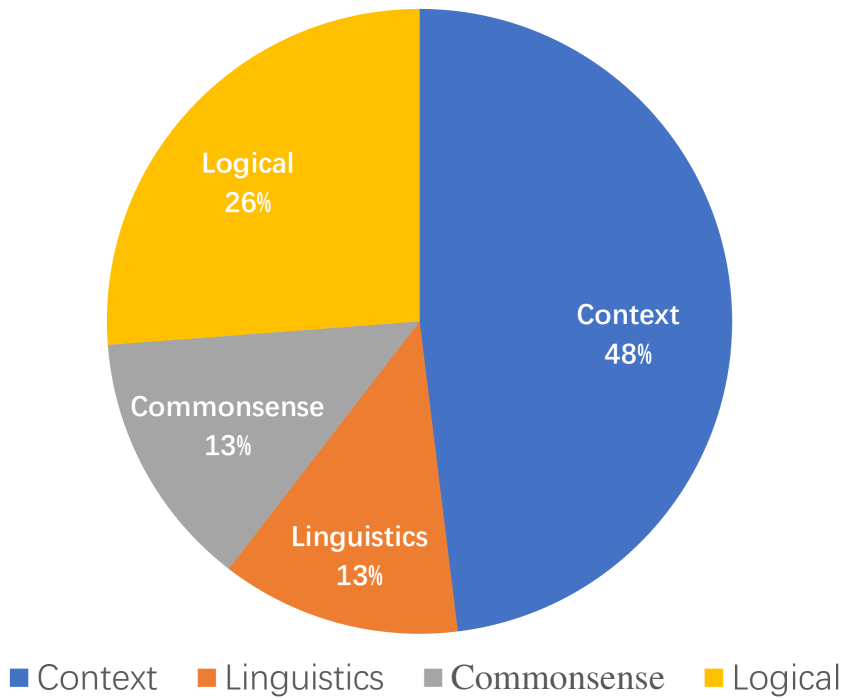
The text provides a detailed analysis of the different types of mistakes that can occur in large language model (LLM) inference processes. The authors sampled mistake examples from the GSM8K and LogiQA datasets to conduct an in-depth analysis of both arithmetic and commonsense reasoning errors.
For commonsense reasoning, the authors found that errors often arise from the model's limitations in understanding and accurately applying context. This reveals that current LLMs may still fall short in consistently recalling precise factual knowledge within a given context. The authors suggest that Retrieval-Augmented Generation (RAG) systems hold promise for yielding more faithful and contextually aligned results.
Regarding arithmetic reasoning, the analysis shows that the most common errors made by LLMs are related to calculation. This can be attributed to the different nature of LLMs compared to tools like calculators. The authors suggest that using a Program-of-Thought (PoT) approach, as proposed by Chen et al. (2022), is a promising way to instruct LLMs to generate code to solve problems, leading to more accurate calculation results.
Additionally, the text highlights that logical errors are another type of error that LLMs suffer from. The causes of these logical errors are more complicated and nuanced, often stemming from the model's limitations in comprehending mathematical concepts or its inability to correctly infer the needed function from the context of the question. The authors note that more fine-grained analysis and methods are needed to address such complex logical errors in arithmetic reasoning.
Conclusions and Future Work
The paper explores whether large language models (LLMs) can learn from their mistakes. To investigate this, the authors introduce CoTErrorSet, a new benchmark that collects both correct and incorrect chain-of-thought (CoT) rationales across various domains. The benchmark is designed to demonstrate mistakes for LLMs.
The paper proposes two potential solutions to expose the effects of mistakes from different perspectives: self-rethinking and mistake tuning. These approaches achieve consistent and significant improvements, demonstrating the benefits of learning from reasoning errors.
The paper also conducts a comprehensive analysis of common mistakes made by LLMs in both arithmetic and commonsense reasoning. The findings from this analysis aim to provide clear directions for future improvements.
For future work, the authors envision developing algorithms or loss functions to help LLMs learn from implicit information within mistakes. Incorporating contrastive learning to differentiate correct and incorrect references, as well as leveraging memorization and retrieval-augmented skills, are suggested as potential avenues to further improve performance by learning from mistakes.
The primary goal of this work is to establish a new paradigm for LLMs to learn from their errors.
tations
The paper acknowledges several limitations in their study beyond the challenge of fine-tuning commercial large language models (LLMs). The self-rethinking methodology they used may not be entirely suitable for tasks where a distinct, objective label is not readily available, such as in machine translation or dialogue generation. These areas pose a unique challenge as the correctness of outputs can often be subjective or context-dependent, making it difficult to apply their approach effectively. Additionally, their utilization of the CoTErrorSet collection for mistake tuning necessitates a ground truth label for each sample, which could pose a potential impediment to the applicability of their method in low-resource scenarios. The paper states that future work will continually improve the method and bring the concept of learning from mistakes to wider scenarios and applications.
Appendix A An example in CoTErrorSet
Appendix B Algorithm for self-rethinking
Appendix C Reasoning Mistake Examples
Appendix D More Details about LLM-based Clustering Approach
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
LLMs can Find Mathematical Reasoning Mistakes by Pedagogical Chain-of-Thought
Zhuoxuan Jiang, Haoyuan Peng, Shanshan Feng, Fan Li, Dongsheng Li
0
0
Self-correction is emerging as a promising approach to mitigate the issue of hallucination in Large Language Models (LLMs). To facilitate effective self-correction, recent research has proposed mistake detection as its initial step. However, current literature suggests that LLMs often struggle with reliably identifying reasoning mistakes when using simplistic prompting strategies. To address this challenge, we introduce a unique prompting strategy, termed the Pedagogical Chain-of-Thought (PedCoT), which is specifically designed to guide the identification of reasoning mistakes, particularly mathematical reasoning mistakes. PedCoT consists of pedagogical principles for prompts (PPP) design, two-stage interaction process (TIP) and grounded PedCoT prompts, all inspired by the educational theory of the Bloom Cognitive Model (BCM). We evaluate our approach on two public datasets featuring math problems of varying difficulty levels. The experiments demonstrate that our zero-shot prompting strategy significantly outperforms strong baselines. The proposed method can achieve the goal of reliable mathematical mistake identification and provide a foundation for automatic math answer grading. The results underscore the significance of educational theory, serving as domain knowledge, in guiding prompting strategy design for addressing challenging tasks with LLMs effectively.
5/14/2024
📈
Learning From Mistakes Makes LLM Better Reasoner
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, Weizhu Chen
0
0
Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve their reasoning capabilities, this work explores whether LLMs can LEarn from MistAkes (LEMA), akin to the human learning process. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LEMA incorporates mistake-correction data pairs during fine-tuning LLMs. Specifically, we first collect inaccurate reasoning paths from various LLMs, and then employ GPT-4 as a ''corrector'' to identify the mistake step, explain the reason for the mistake, correct the mistake and generate the final answer. In addition, we apply a correction-centric evolution strategy that effectively expands the question set for generating correction data. Experiments across various LLMs and reasoning tasks show that LEMA effectively improves CoT-alone fine-tuning. Our further ablations shed light on the non-homogeneous effectiveness between CoT data and correction data. These results suggest a significant potential for LLMs to improve through learning from their mistakes. Our code, models and prompts are publicly available at https://github.com/microsoft/LEMA.
4/1/2024
💬
Learning to Check: Unleashing Potentials for Self-Correction in Large Language Models
Che Zhang, Zhenyang Xiao, Chengcheng Han, Yixin Lian, Yuejian Fang
0
0
Self-correction has achieved impressive results in enhancing the style and security of the generated output from large language models (LLMs). However, recent studies suggest that self-correction might be limited or even counterproductive in reasoning tasks due to LLMs' difficulties in identifying logical mistakes. In this paper, we aim to enhance the self-checking capabilities of LLMs by constructing training data for checking tasks. Specifically, we apply the Chain of Thought (CoT) methodology to self-checking tasks, utilizing fine-grained step-level analyses and explanations to assess the correctness of reasoning paths. We propose a specialized checking format called Step CoT Check. Following this format, we construct a checking-correction dataset that includes detailed step-by-step analysis and checking. Then we fine-tune LLMs to enhance their error detection and correction abilities. Our experiments demonstrate that fine-tuning with the Step CoT Check format significantly improves the self-checking and self-correction abilities of LLMs across multiple benchmarks. This approach outperforms other formats, especially in locating the incorrect position, with greater benefits observed in larger models. For reproducibility, all the datasets and code are provided in https://github.com/bammt/Learn-to-check.
6/18/2024
🤯
LLMs cannot find reasoning errors, but can correct them given the error location
Gladys Tyen, Hassan Mansoor, Victor Cu{a}rbune, Peter Chen, Tony Mak
0
0
While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023b; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we show that poor self-correction performance stems from LLMs' inability to find logical mistakes, rather than their ability to correct a known mistake. Firstly, we benchmark several state-of-the-art LLMs on their mistake-finding ability and demonstrate that they generally struggle with the task, even in highly objective, unambiguous cases. Secondly, we test the correction abilities of LLMs -- separately from mistake finding -- using a backtracking setup that feeds ground truth mistake location information to the model. We show that this boosts downstream task performance across our 5 reasoning tasks, indicating that LLMs' correction abilities are robust. Finally, we show that it is possible to obtain mistake location information without ground truth labels or in-domain training data. We train a small classifier with out-of-domain data, which exhibits stronger mistake-finding performance than prompting a large model. We release our dataset of LLM-generated logical mistakes, BIG-Bench Mistake, to enable further research into locating LLM reasoning mistakes.
6/5/2024