Learning to Check: Unleashing Potentials for Self-Correction in Large Language Models
2402.13035
0
0
💬
Abstract
Self-correction has achieved impressive results in enhancing the style and security of the generated output from large language models (LLMs). However, recent studies suggest that self-correction might be limited or even counterproductive in reasoning tasks due to LLMs' difficulties in identifying logical mistakes. In this paper, we aim to enhance the self-checking capabilities of LLMs by constructing training data for checking tasks. Specifically, we apply the Chain of Thought (CoT) methodology to self-checking tasks, utilizing fine-grained step-level analyses and explanations to assess the correctness of reasoning paths. We propose a specialized checking format called Step CoT Check. Following this format, we construct a checking-correction dataset that includes detailed step-by-step analysis and checking. Then we fine-tune LLMs to enhance their error detection and correction abilities. Our experiments demonstrate that fine-tuning with the Step CoT Check format significantly improves the self-checking and self-correction abilities of LLMs across multiple benchmarks. This approach outperforms other formats, especially in locating the incorrect position, with greater benefits observed in larger models. For reproducibility, all the datasets and code are provided in https://github.com/bammt/Learn-to-check.
Create account to get full access
Overview
- This paper explores how to enhance the self-checking capabilities of large language models (LLMs) to improve their reasoning abilities.
- The researchers apply the Chain of Thought (CoT) methodology to self-checking tasks, using step-level analyses and explanations to assess the correctness of reasoning paths.
- They propose a specialized checking format called Step CoT Check and construct a dataset with detailed step-by-step analysis and checking.
- The paper demonstrates that fine-tuning LLMs with the Step CoT Check format significantly improves their self-checking and self-correction abilities across multiple benchmarks.
Plain English Explanation
Large language models (LLMs) have made impressive strides in generating high-quality text, but recent studies suggest they may struggle with identifying logical mistakes in their own reasoning. To address this, the researchers in this paper sought to enhance the self-checking capabilities of LLMs.
They took inspiration from the Chain of Thought (CoT) methodology, which involves breaking down a problem into step-by-step analyses. The researchers applied this approach to self-checking tasks, creating a specialized format called Step CoT Check.
This format includes detailed, step-by-step explanations of the reasoning process, which the researchers then used to construct a dataset for training LLMs. By fine-tuning LLMs with this dataset, the researchers were able to significantly enhance the models' ability to detect and correct their own mistakes, especially in larger models.
The researchers made their datasets and code publicly available to allow others to build on their work and improve the self-checking capabilities of LLMs.
Technical Explanation
The researchers in this paper aimed to enhance the self-checking capabilities of large language models (LLMs) to improve their reasoning abilities. They applied the Chain of Thought (CoT) methodology to self-checking tasks, using fine-grained step-level analyses and explanations to assess the correctness of reasoning paths.
Specifically, the researchers proposed a specialized checking format called Step CoT Check. This format involves breaking down a problem-solving process into detailed, step-by-step explanations, which are then used to construct a dataset for training LLMs.
The researchers fine-tuned LLMs with this Step CoT Check dataset and evaluated their performance on multiple benchmarks. Their experiments demonstrated that this approach significantly improves the self-checking and self-correction abilities of LLMs, especially in larger models.
The researchers made their datasets and code publicly available to encourage further research and development in this area.
Critical Analysis
The researchers present a promising approach to enhancing the self-checking capabilities of large language models (LLMs). By applying the Chain of Thought (CoT) methodology to self-checking tasks and creating a specialized Step CoT Check format, they were able to substantially improve the models' ability to detect and correct their own reasoning errors.
One potential limitation of the research is that the experiments were conducted on a limited set of benchmarks. It would be valuable to evaluate the approach on a wider range of tasks to better understand its generalizability.
Additionally, the researchers noted that the benefits of the Step CoT Check format were more pronounced in larger models. This raises questions about the scalability and feasibility of this approach for smaller or more resource-constrained models.
Further research could also explore the long-term impact of this self-checking capability and how it might affect the overall reasoning and decision-making abilities of LLMs. Potential issues, such as overconfidence or a reluctance to explore alternative solutions, should be carefully considered.
Conclusion
This paper presents a novel approach to enhancing the self-checking capabilities of large language models (LLMs) by applying the Chain of Thought (CoT) methodology to self-checking tasks. The researchers' proposed Step CoT Check format and the resulting dataset have been shown to significantly improve the models' ability to detect and correct their own reasoning errors, particularly in larger models.
The public release of the datasets and code provides a foundation for further research and development in this area, which could have far-reaching implications for the reasoning abilities and real-world applications of LLMs. As these models continue to advance, the capacity for self-correction and robust reasoning will be crucial for ensuring their safe and reliable deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
LLMs can Find Mathematical Reasoning Mistakes by Pedagogical Chain-of-Thought
Zhuoxuan Jiang, Haoyuan Peng, Shanshan Feng, Fan Li, Dongsheng Li
0
0
Self-correction is emerging as a promising approach to mitigate the issue of hallucination in Large Language Models (LLMs). To facilitate effective self-correction, recent research has proposed mistake detection as its initial step. However, current literature suggests that LLMs often struggle with reliably identifying reasoning mistakes when using simplistic prompting strategies. To address this challenge, we introduce a unique prompting strategy, termed the Pedagogical Chain-of-Thought (PedCoT), which is specifically designed to guide the identification of reasoning mistakes, particularly mathematical reasoning mistakes. PedCoT consists of pedagogical principles for prompts (PPP) design, two-stage interaction process (TIP) and grounded PedCoT prompts, all inspired by the educational theory of the Bloom Cognitive Model (BCM). We evaluate our approach on two public datasets featuring math problems of varying difficulty levels. The experiments demonstrate that our zero-shot prompting strategy significantly outperforms strong baselines. The proposed method can achieve the goal of reliable mathematical mistake identification and provide a foundation for automatic math answer grading. The results underscore the significance of educational theory, serving as domain knowledge, in guiding prompting strategy design for addressing challenging tasks with LLMs effectively.
5/14/2024

Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning
Yongqi Tong, Dawei Li, Sizhe Wang, Yujia Wang, Fei Teng, Jingbo Shang
0
0
Recent works have shown the benefits to LLMs from fine-tuning golden-standard Chain-of-Thought (CoT) rationales or using them as correct examples in few-shot prompting. While humans can indeed imitate correct examples, learning from our mistakes is another vital aspect of human cognition. Hence, a question naturally arises: textit{can LLMs learn and benefit from their mistakes, especially for their reasoning? } This study investigates this problem from both the prompting and model-tuning perspectives. We begin by introducing textsc{CoTErrorSet}, a new benchmark with 609,432 questions, each designed with both correct and error references, and demonstrating the types and reasons for making such mistakes. To explore the effectiveness of those mistakes, we design two methods: (1) textbf{Self-rethinking} prompting guides LLMs to rethink whether they have made similar previous mistakes; and (2) textbf{Mistake tuning} involves finetuning models in both correct and incorrect reasoning domains, rather than only tuning models to learn ground truth in traditional methodology. We conduct a series of experiments to prove LLMs can obtain benefits from mistakes in both directions. Our two methods offer potentially cost-effective strategies by leveraging errors to enhance reasoning capabilities, which costs significantly less than creating meticulously hand-crafted golden references. We ultimately make a thorough analysis of the reasons behind LLMs' errors, which provides directions that future research needs to overcome. textsc{CoTErrorSet} will be published soon on texttt{url{https://github.com/YookiTong/Learn-from-Mistakes-CotErrorSet}}.
6/10/2024

Chain-of-Though (CoT) prompting strategies for medical error detection and correction
Zhaolong Wu, Abul Hasan, Jinge Wu, Yunsoo Kim, Jason P. Y. Cheung, Teng Zhang, Honghan Wu
0
0
This paper describes our submission to the MEDIQA-CORR 2024 shared task for automatically detecting and correcting medical errors in clinical notes. We report results for three methods of few-shot In-Context Learning (ICL) augmented with Chain-of-Thought (CoT) and reason prompts using a large language model (LLM). In the first method, we manually analyse a subset of train and validation dataset to infer three CoT prompts by examining error types in the clinical notes. In the second method, we utilise the training dataset to prompt the LLM to deduce reasons about their correctness or incorrectness. The constructed CoTs and reasons are then augmented with ICL examples to solve the tasks of error detection, span identification, and error correction. Finally, we combine the two methods using a rule-based ensemble method. Across the three sub-tasks, our ensemble method achieves a ranking of 3rd for both sub-task 1 and 2, while securing 7th place in sub-task 3 among all submissions.
6/14/2024
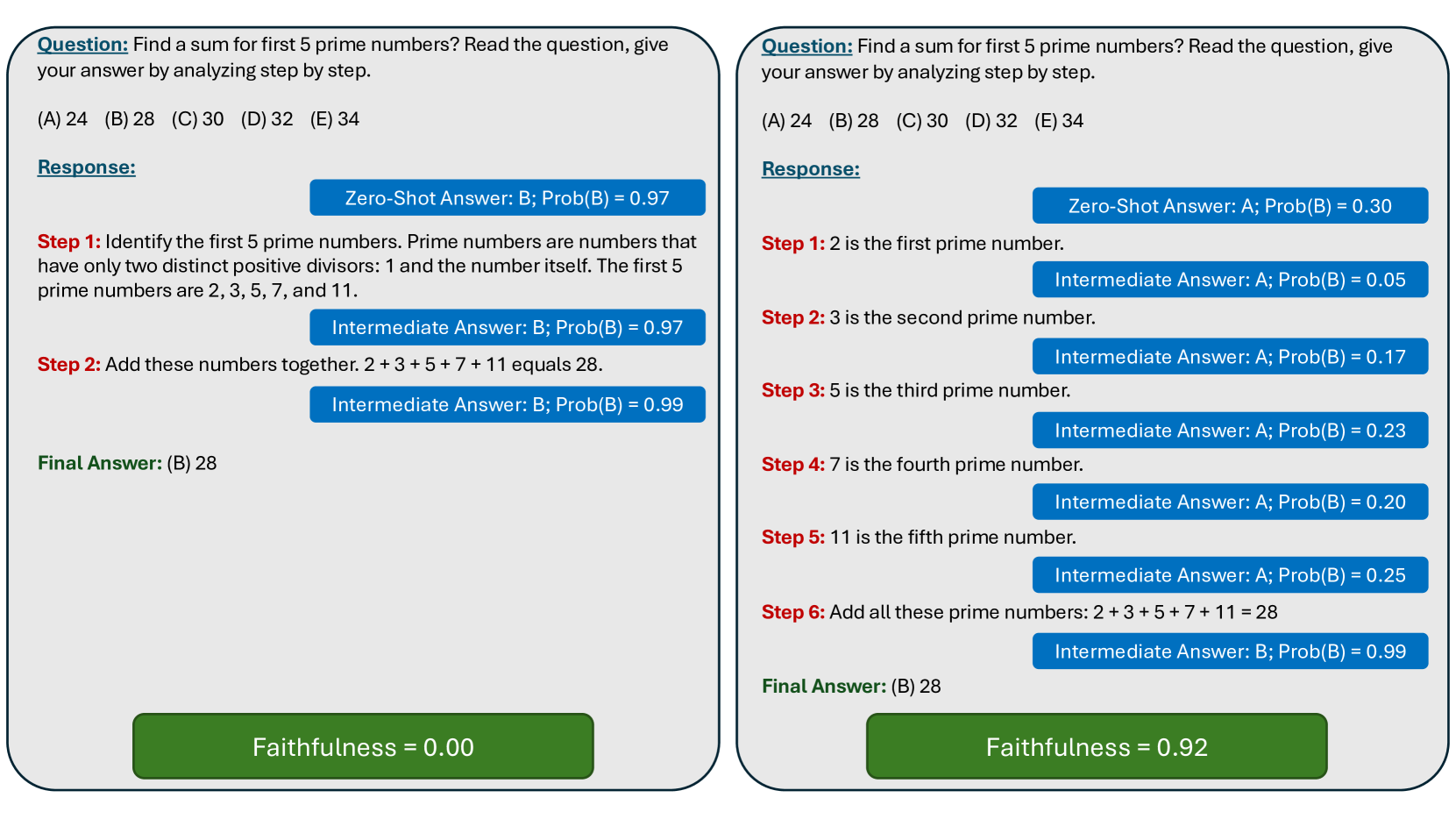
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, Himabindu Lakkaraju
0
0
As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
6/18/2024